

Accelerating PyTorch Model Training
Using Mixed-Precision and Fully Sharded Data Parallelism

Last week, I gave a talk on "Scaling PyTorch Model Training With Minimal Code Changes" at CVPR 2023 in Vancouver. It was really nice to chat with so many people at the event.
For future reference, and for those who couldn't attend, I wanted to try a little experiment and convert the talk into a short article, which you can find below! (PS: more on my takeaways from CVPR next week!)
So, this article delves into how to scale PyTorch model training with minimal code changes. The focus here is on leveraging mixed-precision techniques and multi-GPU training paradigms, not low-level machine optimizations. We will use a simple Vision Transformer (ViT) trained to classify images as our base model.
Starting with a Baseline
Our ViT, trained on a basic dataset from scratch, took about 60 minutes and achieved a test set accuracy of 62%.
In the upcoming sections, we will explore methods to improve the training time and accuracy without major code restructures.
Note that the model and dataset details are not a primary concern here (they are just chosen to be as simple as possible so that you can replicate the code on your own hardware without downloading and installing too many dependencies.) All examples shared here are available in this GitHub repository, where you can explore and reuse the complete code.

A Shift from Training from Scratch
In today's day an age, training deep learning models for text or vision from scratch is often wasteful. We usually leverage pretrained models and finetune them for our purposes to save time, computational resources, and obtain better modeling performance.
If we consider the same ViT architecture we used above, pretrained on a different dataset (ImageNet), and finetune it, we can achieve a far better prediction performance in much less time: 95% test accuracy in 20 min (3 training epochs).

Improving Computational Performance
Above, we have seen that finetuning can give us a large boost over training from scratch, which is summarized in a more compact barplot below.

Of course, our mileage may vary based on the dataset or task, but for many text and vision tasks, starting with a model pretrained on a general, public dataset is worthwhile.
The next sections will explore different tricks to accelerate the training time without sacrificing prediction accuracy.
Introducing the Open-Source Fabric Library
One way to efficiently scale training in PyTorch with minimal code changes is using the open-source Fabric library, which can be considered a lightweight wrapper library/API around PyTorch. We install it via
pip install lightningBut of course, all the techniques we will explore below can also be implemented in pure PyTorch -- the goal of Fabric is to make this a bit more convenient.
Before we explore these "advanced techniques to accelerate our code," let's introduce the small changes from incorporating Fabric into our PyTorch code. (Once we make these changes below, it will be easy to access advanced PyTorch features by changing only 1 line of code.)
The difference between simple PyTorch code and the modified one to use Fabric is subtle and involves only minor modifications, as highlighted in the code below:

To summarize the figure above, the main 3 steps for converting plain PyTorch code to PyTorch+Fabric are as follows:
Import Fabric and instantiate a Fabric object.
Use Fabric to set up the model, the optimizer, and the data loader.
Call
fabric.backward()on the loss instead of the usualloss.backward()

These minor changes now provide a gateway to utilize advanced features in PyTorch without restructuring any more of the existing code.
But before we dive into these "advanced features" below, let's ensure that the model still has the same training runtime and predictive performance as before.

As we can see in the bar plots above, the training runtime and accuracies are exactly the same as before, as expected. (Any fluctuations can be attributed to randomness.)
In the previous section, we modified our PyTorch code using Fabric. Why go through all this hassle? As we will see below, we can now try advanced techniques, like mixed-precision and distributed training, by only changing one line of code, changing
fabric = Fabric(accelerator="cuda")to
fabric = Fabric(accelerator="cuda", precision="bf16-mixed")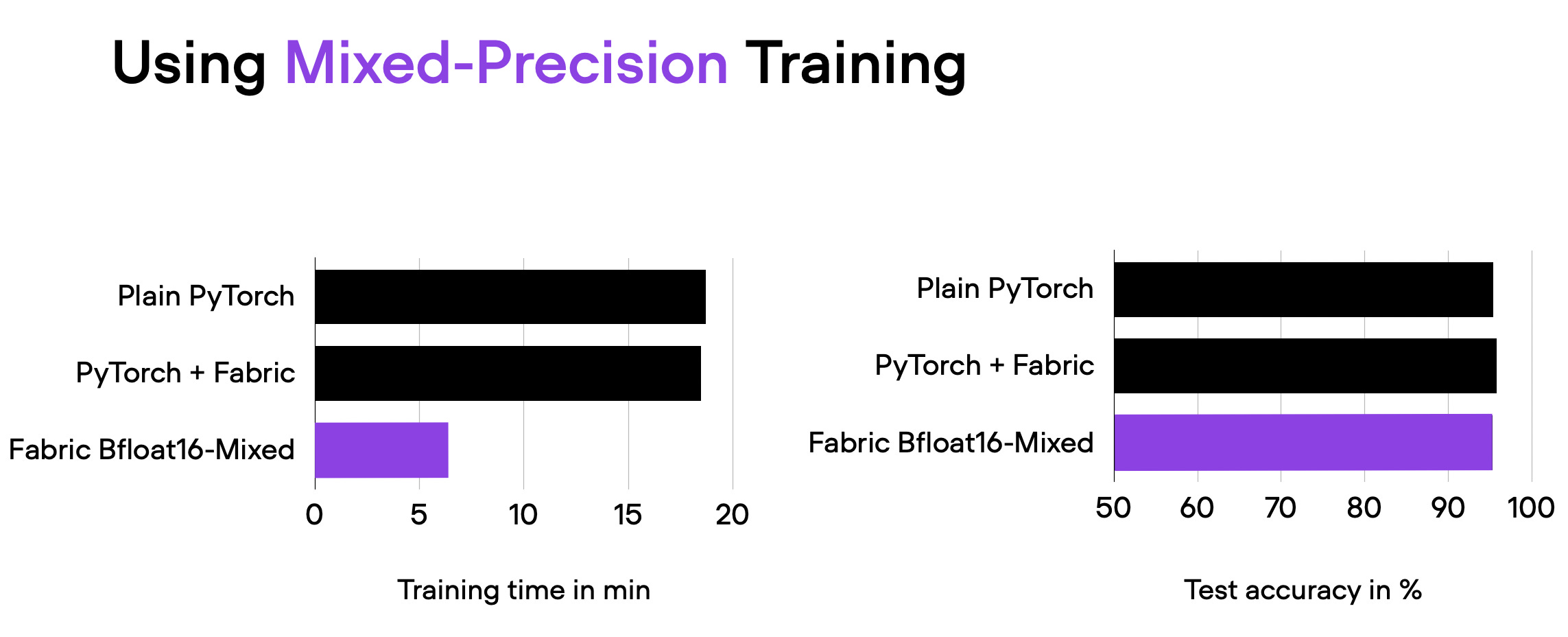
With mixed precision training, we cut down the training time from about 18 minutes to 6 minutes while maintaining the same predictive performance. This reduction in training time was achieved simply by adding the argument precision="bf16-mixed" when instantiating the Fabric object.
Understanding Mixed-Precision Mechanics
Mixed precision training essentially uses both 16-bit and 32-bit precision to ensure that there's no loss in accuracy. The computation of gradients in the 16-bit representation is much faster than in the 32-bit format and also saves a significant amount of memory. This strategy is beneficial, especially when we are memory or compute-constrained.
It's called "mixed-"rather than "low-"precision training because we don't transfer all parameters and operations to 16-bit floats. Instead, we switch between 32-bit and 16-bit operations during training, hence, the term "mixed" precision.
As illustrated in the figure below, mixed-precision training involves converting weights to lower-precision (FP16) for faster computation, calculating gradients, converting gradients back to higher-precision (FP32) for numerical stability, and updating the original weights with the scaled gradients.
This approach allows for efficient training while maintaining the accuracy and stability of the neural network.

In more detail, the steps are as follows.
Convert weights to FP16: In this step, the weights (or parameters) of the neural network, which are initially in FP32 format, are converted to lower-precision FP16 format. This reduces the memory footprint and allows for faster computation, as FP16 operations require less memory and can be processed more quickly by the hardware.
Compute gradients: The forward and backward passes of the neural network are performed using the lower-precision FP16 weights. This step calculates the gradients (partial derivatives) of the loss function with respect to the network’s weights, which are used to update the weights during the optimization process.
Convert gradients to FP32: After computing the gradients in FP16, they are converted back to the higher-precision FP32 format. This conversion is essential for maintaining numerical stability and avoiding issues such as vanishing or exploding gradients that can occur when using lower-precision arithmetic.
Multiply by learning rate and update weights: Now in FP32 format, the gradients are multiplied by a learning rate (a scalar value that determines the step size during optimization).
The product from step 4 is then used to update the original FP32 neural network weights. The learning rate helps control the convergence of the optimization process and is crucial for achieving good performance.
Brain Float 16
Above, we talked about "float 16-bit" precision training. But notice that we specified precision="bf16-mixed" instead of precision="16-mixed" in our code earlier -- both are valid options.
Here, the "bf16" in "bf16-mixed" stands for Brain Floating Point (bfloat16). Google developed this format for machine learning and deep learning applications, particularly in their Tensor Processing Units (TPUs). Bfloat16 extends the dynamic range compared to the conventional float16 format at the expense of decreased precision.

The extended dynamic range helps bfloat16 to represent very large and very small numbers, making it more suitable for deep learning applications where a wide range of values might be encountered. However, the lower precision may affect the accuracy of certain calculations or lead to rounding errors in some cases. But in most deep learning applications, this reduced precision has minimal impact on modeling performance.
While bfloat16 was originally developed for TPUs, this format is now supported by several NVIDIA GPUs as well, beginning with the A100 Tensor Core GPUs, which are part of the NVIDIA Ampere architecture.
You can check whether your GPU supports bfloat16 via the following code:
>>> torch.cuda.is_bf16_supported()
TrueIf your GPU does not support brain float 16, you can change precision="bf16-mixed" to precision="16-mixed".
Multi-GPU Training and Fully Sharded Data Parallelism
The next modification we are going to try is multi-GPU training. It becomes beneficial if we have multiple GPUs at our disposal since it allows us to train our models even faster.
A more advanced technique that exploits this strategy is Fully Sharded Data Parallelism (FSDP), which utilizes both data parallelism and tensor parallelism.

In Fabric, we can leverage FSDP by adding the number of devices and multi-GPU training strategy as follows:
fabric = Fabric(
accelerator="cuda", precision="bf16-mixed",
devices=4, strategy="FSDP" # new!
)
It may be no big surprise since we are now involving 4 GPUs, but our code runs in about 2 minutes now, approximately 3 times faster than before when we only used mixed-precision training.
Understanding Data Parallelism and Tensor Parallelism
In data parallelism, the mini-batch is divided, and a copy of the model is available on each of the GPUs. This process speeds up model training as multiple GPUs work in parallel.
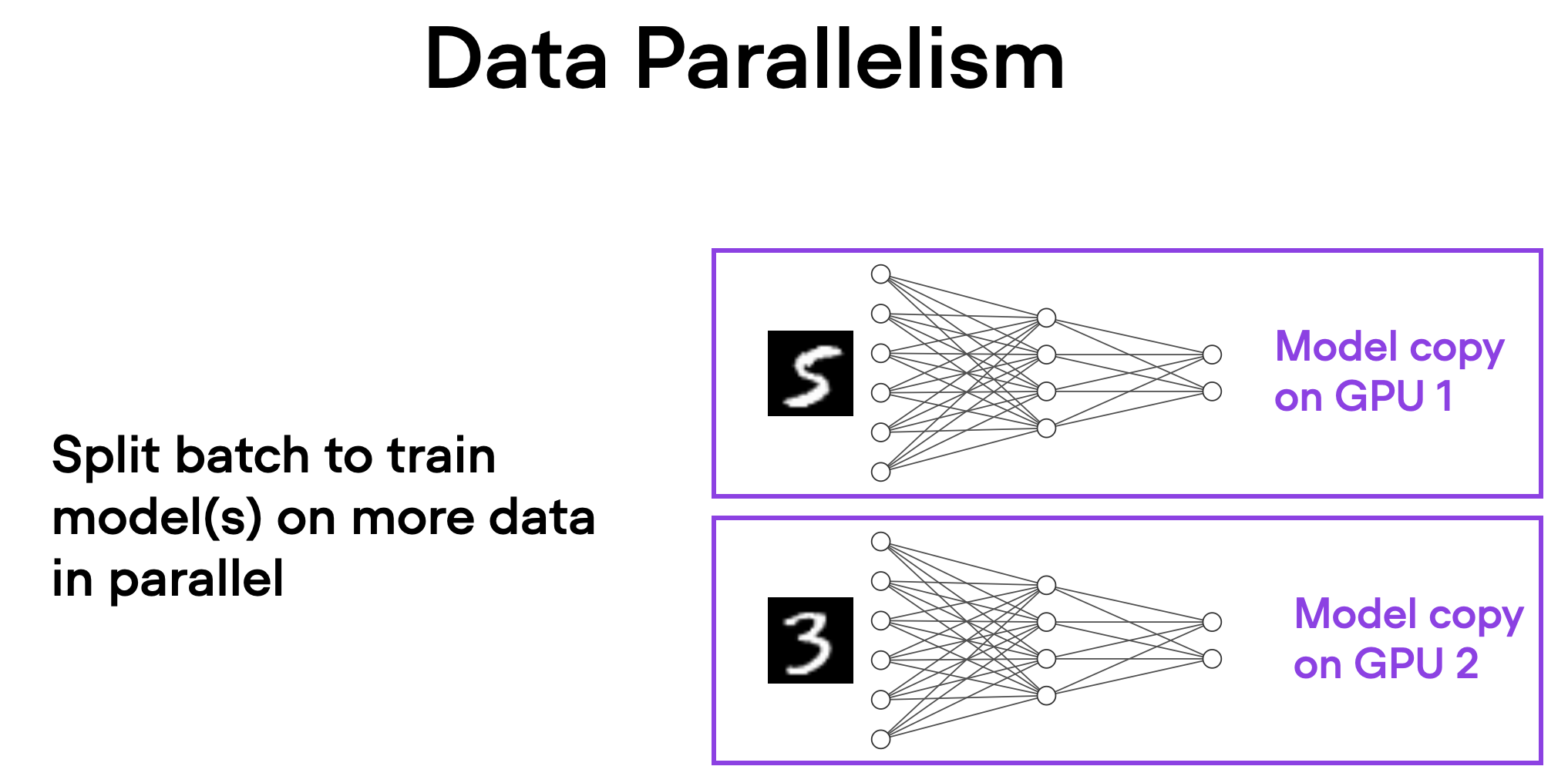
Here's how it works in a nutshell:
The same model is replicated across all the GPUs.
Each GPU is then fed a different subset of the input data (a different mini-batch).
All GPUs independently perform forward and backward passes of the model, computing their own local gradients.
Then, the gradients are collected and averaged across all GPUs.
The averaged gradients are then used to update the model's parameters.
The primary advantage of this approach is speed. Since each GPU is processing a unique mini-batch of data concurrently with the others, the model can be trained on more data in less time. This can significantly reduce the time required to train our model, especially when working with large datasets.
However, data parallelism has some limitations. Most importantly, each GPU must have a complete copy of the model and its parameters. This places a limit on the size of the model we can train, as the model must fit within a single GPU's memory -- this is not feasible for modern ViTs or LLMs.
Unlike data parallelism, which involves splitting a mini-batch across multiple devices, tensor parallelism divides the model itself across GPUs. In data parallelism, every GPU needs to fit the entire model, which can be a limitation when training larger models. Tensor parallelism, on the other hand, allows for training models that might be too large for a single GPU by breaking up the model and distributing it across multiple devices.

How does it work? Think of matrix multiplication. There are two ways to distribute it -- by row or by column. For simplicity, let's consider distribution by column. For instance, we can break down a large matrix multiplication operation into separate computations, each of which can be carried out on a different GPU, as shown in the figure below. The results are then concatenated to get the original result, effectively distributing the computational load.

Conclusion
In this article, we saw how we can tinker with techniques like mixed-precision training and distributed multi-GPU training by changing only a few lines of code. If we use mixed-precision training on the Vision Transformer example, we reduce the runtime 3 fold from ~18 min to ~6 min. And adding 3 more GPUs, we further reduced the training time from ~6 min to ~2 min. That's almost a 10-times improvement without sacrificing prediction accuracy.
Of course, our mileage may vary based on the model, dataset, and task. However, the goal of this article was to mainly outline how we can experiment with these techniques conveniently using PyTorch and Fabric.
(For reference, all code examples are available here on GitHub)
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Wow Lightning does make it super easy to employ mixed precision and distributed training! When I wrote about mixed precision in 2020, when PyTorch just released their AMP (automatic mixed precision) module, it was a mess trying to autocast the layers and remembering their precisions.
Enjoyed the read! Thanks!
Clear and straight to the point, thanks a lot!