

A Diffusion of Innovations: Recent Developments in Generative Learning

Articles & Trends
Quo Vadis Generative Learning? Where Are We Headed?
Previous years were centered around large language transformers for generating text. While transformers for text and vision remain a focus area for many researchers and AI companies, diffusion models recently stole their spotlight.
With the emergence of diffusion models (full name: denoising diffusion probabilistic models) generative learning has recently seen a big revolution. Approximately 1.5 years ago, in 11 May 2021, we got a taste of diffusion models outperforming GANs. Now, diffusion models are everywhere.
What are diffusion models?
Diffusion models are fundamentally generative models. During training, random noise is added to the input data over a series of steps to perturb it. Then, in a reverse process, the model learns how to invert the noise and denoise the output to recover the original data. During inference, a diffusion model can then be used to generate new data from noise inputs.

Applications of diffusion models
The first really popular and notable applications of diffusion model includes a list of large models for generating art and images; the names below are probably already familiar to you:
DALL•E 2 (by OpenAI, announced 6 Apr 2022)
Imagen (by Google, announced 23 May 2022)
Stable Diffusion (by Stability.ai, announced 22 Aug 2022 & fully open source since release)
Note that while these models can produce realistic and artistic-looking images, there is also mounting criticism since these models were trained on data scraped from the internet without asking permission from the original artist. Furthermore, artists are concerned about AI as a competitor. I do not know enough about IP laws to offer additional insights, but I remember similar criticism that followed Microsoft's Copilottrained on GitHub code last year.
I am not sure where it leaves the artists. What we know today is that AI is not replacing coders; it's more like coders are being replaced by coders who use AI -- similar to what happened in chess following DeepBlue's victory over Karpov in the 90s. I am not sure what it means for artists, but now that it's impossible to put the genie back into the bottle, there is maybe no way around making the best out of it by utilizing these new technologies.
From images to videos
Following the first wave of diffusion models for image generation mentioned above, companies recently started to take it to the next level, releasing models to generate video clips from text input prompts:
Make-A-Video (Meta, announced 29 Sep 2022)
Imagen-video (Google, announced 6 Oct 2022)
I guess that it's only a matter of weeks before we see the first open-source equivalent from Stability.ai. It's also worth noting that OpenAI does not yet have its own version of a video-generating diffusion model. (Also, I wonder that considering their recent Whisper release -- a subtitle generator -- whether they might be working on a video clip resyncing API.)
Also, please note that there are many, many more diffusion models out there. To get a taste of their sheer number, search for "diffusion" in this generative modeling paper list. Or, check out the more than 300 papers (as of this writing!) in the Awesome Diffusion Models List.
I guess the next wave of prominent examples will focus on 3D environments (e.g., for VR) and locomotion. There are already a few notable efforts in this direction:
Applications in biology
Having supervised a PhD student who focused on developing graph neural networks for generating molecules, I cannot help but being impressed by the biological applications of diffusion models as well. For example,

Now, also considering transformer-based models such as ProteinBERT and AlphaFold 2, I wonder what the future of graph neural networks brings. On the one hand, Microsoft launched a huge initiative and team centered around molecular modeling with graph neural networks last year. Still, the most impressive applications of AI to molecular data were not graph neural network-based. One explanation is that we still haven't figured out how to scale graph neural networks beyond small molecules, but we will see what the future brings. Similar to investors diversifying their investments, we shouldn't be putting all our eggs in one basket.
Resources to learn more
Interested in learning more about diffusion models? Below is a curated list of useful resources:
The illustrated stable diffusion by Jay Alammar
A minimal standalone code example of diffusion model by InFoCusp
How diffusion models work: the math from scratch by Sergios Karagiannakos and Nikolas Adaloglou
What are diffusion models? by Lillian Wang
Does numerical computing have an open future?
As a long-term fan and user of the conda package manager for Python, I was recently honored to be invited to Anadonda's 10-year anniversary panel centered around open source and scientific computing alongside Travis Oliphant, Paige Bailey, and Ryan Abernathy.
Does Numerical Computing Have An Open Future? We are now in open source 2.0. I remember that 10 years ago, we were just uploading our coding projects to GitHub. We've come a long way! Now, in Phase II, where we learn how to maintain things and organize sustainable communities!
A good recent example is PyTorch's move to the Linux Foundation.
A full recording of the panel is available below.
Research Deep Dive
In this section, I will summarize a selected research paper. To stay on topic with the "diffusion theme" of this newsletter, my pick is a diffusion model, of course! So here is a diffusion model for generating tabular data: "TabDDPM: Modeling Tabular Data with Diffusion Models".
First up, why are models for generating tabular data useful? Two application areas come to mind:
Generating larger datasets and oversampling minority classes in case of class imbalance.
Generating realistic, synthetic datasets in contexts where the original data cannot be shared (e.g., because of privacy concerns).
TabDDPM is by no means the first model that attempts to generate realistic tabular data. There is a long history of generative adversarial networks (GANs) and variational autoencoders (VAEs) that have been adopted for this purpose, including notebable examples such as CTab-GAN+ and TVAE.
Here, the premise of the TabDDPM paper is that a diffusion model can outperform its GAN and VAE counterpart (similar to applications in the image and video domains as discussed above in this newsletter.)
How does TabDDPM work?
TabDDPM uses multinomial diffusion for categorical (and binary) features, adding uniform noise. For numerical features, it uses the common Gaussian diffusion process. The reverse diffusion process is then learned via a fully connected network (MLP).
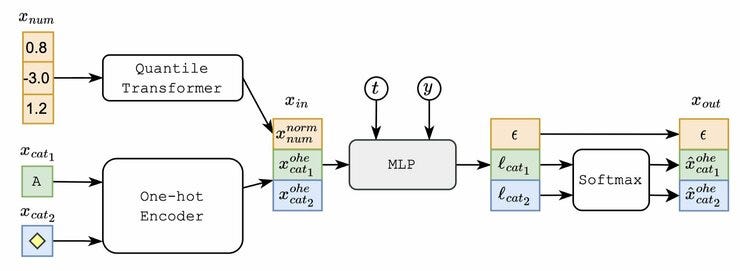
However, note that the TabDDPM does not just memorize training data records. The authors conclude this from an analysis of the “distance to closest record” (DCR) distribution, which contains a substantial amount of non-zero distances.
The subsequent analysis of the quality of the synthetic datasets quantifies the performance of several classifiers trained on the generated data. For instance, across 15 classification and regression datasets, models such as random forest, logistic regression, decision trees, and CatBoost perform better on TabDDPM synthetic data than the synthetic data generated by GANs or VAEs.
If you are curious about trying TabDDPM, the source code for TabDDPM is available here.
Open Source Highlights
Generating high-quality subtitles with Whisper
OpenAI recently announced and released Whisper, an open-source language model to generate subtitles (closed captions) for audio files and summarizations. I took Whisper for a test run, and it worked amazingly well. Compared to YouTube's default method for generating subtitles and the several paid services I tried over the years, Whisper generates subtitles with far greater accuracy. I am particularly impressed by how well it can handle both my accent and technical deep learning jargon.
Hoping that this is useful to you as well, here is the script I used to generate new subtitles for all my deep learning lecture videos on YouTube.
PyTorch multi-GPU support in Jupyter notebooks
If you know me, you know that I am a devout Jupyter notebook user -- Jupyter notebooks are my favorite environment for prototyping and teaching. A little bottleneck of Jupyter notebooks is that it doesn't support most modern multi-GPU paradigms for deep learning due to multiprocessing restrictions. I am delighted to announce that PyTorch Lightning 1.7 introduces multi-GPU support for PyTorch in Jupyter notebooks. You can learn more here!
Feature groups for feature selection
Shameless plug: MLxtend v0.21 now supports feature groups in its feature selection and permutation importance algorithms. This allows users to treat multiple related features (e.g., those created from one-hot encoding) as a single group during selection.

Educational Nuggets
Here are 5 techniques to optimize deep neural network model performance during inference in a computational sense.
(To narrow the scope, the focus is on techniques that don't change the model architecture. Other techniques that affect the architecture, such as pruning, will be discussed in a future issue.)
(1) Parallelization
Parallelization is the process of splitting the training data (mini) batches into chunks. The goal is to process these smaller chunks in parallel.

(2) Vectorization
Vectorization replaces costly for-loops with operations that apply the same operations to multiple elements.

(3) Loop tiling
Changes the data accessing order in a loop to leverage the hardware's memory layout & cache.

(4) Operator fusion
If you have multiple loops, try to merge those into one.

(5) Quantization
Quantization reduces the numerical precision (and typically cast floats->ints) to speed up computation and lower memory requirements (while maintaining accuracy).

Machine Learning Interview Questions
Are you trying to practice your knowledge or prepare for an interview? This section features questions that may (or may not) help you prepare.
What is the distributional hypothesis in NLP? Where is it used, and how far does it hold true?
What is the difference between stateless and stateful training? And when to use which?
What is the difference between recursion and dynamic programming?
(The answers will be provided in the next newsletter.)
Notable Quote
I don’t think we’ll still be doing prompt engineering in five years. (Sam Altman)
Upcoming Events
NeurIPS 2022 (the leading machine learning & AI conference) is coming up soon! Nov 28th through Dec 1st, 2022.
If you are attending, stop by and say hello! I'll co-host a workshop social on "Industry, Academia, and the In-Betweens" (the transition from academia to industry). More details will follow!
Study & Productivity Tips
One of my favorite tools for learning new things is Anki. It's an open-source flashcard program for spaced repetition. Spaced repetition means that questions are only repeated after certain intervals based on a question's perceived difficulty (for example, the question is repeated after 3 days, then 2 weeks, 3 months, 1 year, and so forth.)
I've been using it since my undergrad. It helps me get the most out of my reading & study sessions and remember things. I firmly believe it's one of the essential tools that helped me through my early years of college. Using it for more than a decade now, I've accumulated thousands of cards.
How do I use it? When I read articles or textbooks, I try to ask myself "interesting" questions about notable things I want to remember. Sometimes I also add screenshots as answers.
I add about 5-15 new cards per day. Also, I spend approximately 10-15 minutes reviewing so things don't get out of control.
I often do my daily review in the evening before I wind down for the day. However, sometimes I take advantage of the mobile version and review my cards on the go (for example, when I arrive a few minutes too early for my haircut appointment or when I am waiting at the baggage claim.)
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Hi Sebastian! Congratulations for your excellent work. It really helps to stay update and learn.
In the 'Educational Nuggets' section, you referred to techniques that can optimize performance during inference. However, the Parallelization technique discusses the splitting of training data that does not pertain to the inference phase. Could you please provide further details regarding this matter?