

Transformers, Fast and Slow: New Developments in Language Processing

Articles & Trends
This time, we will focus on large language models based on the transformer architecture, which is the other pillar of modern deep learning and AI -- next to diffusion models.
As some of you may remember, the natural language processing (NLP) field was long dominated by recurrent neural networks (RNNs). However, this was before self-attention-based neural networks, such as the original transformer architecture by Vaswani et al. 2017 (Attention Is All You Need), revolutionized the field.

(Trivia: RNNs used attention mechanisms long before self-attention came along. As I detailed in my book, RNNs used attention between the encoder and the decoder encodings. In transformers, it's called self-attention because it's attention for all the elements of the same set.)
Anyways, all that is history and the chronology of attention may be a good topic for another day. So let's move on and focus on What's new?
Interacting with modern machine learning models
Prompt Engineering
One thing that generative transformer-based language models and image diffusion models (discussed in the last issue) have in common is that they require a certain degree of prompt engineering. Prompt engineering means tweaking the input sequences (or prompts) to produce the desired output.
Sounds complicated? I can assure you that prompt engineering is something you have been using since the dawn of the internet. It's nothing different from changing your Google Search queries until you get the desired search results.
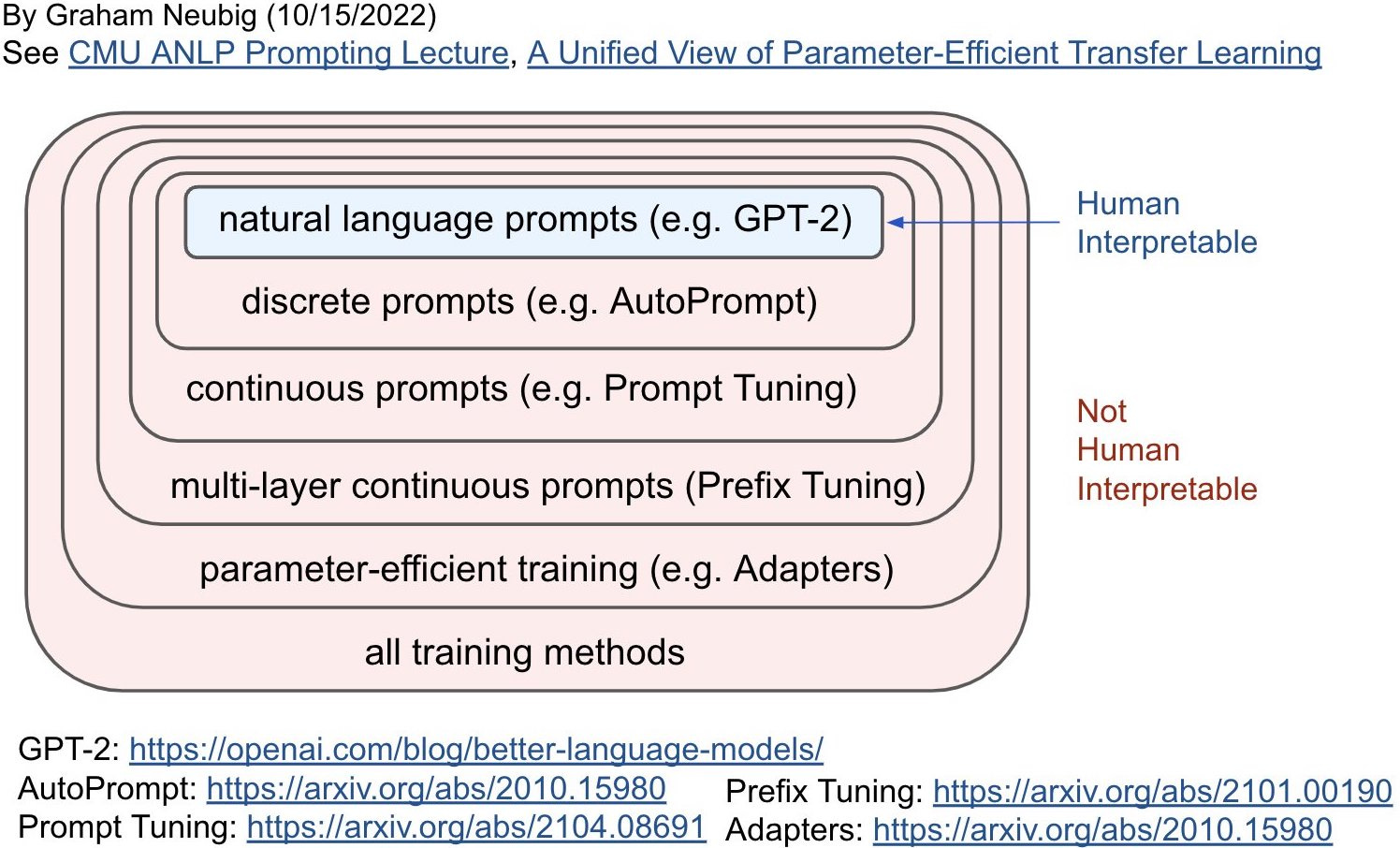
Curious to learn more about prompt engineering? Check out Rick Neubig's excellent taxonomy of prompting methods:
Toxicity
Another thing transformers and diffusion models have in common is that they can have harmful effects, for example, by being misused to produce harmful content. In a recent paper (Prompt Compression and Contrastive Conditioning for Controllability and Toxicity Reduction in Language Models), researchers investigated the effects of compressing prompts. They found that compressing prompts that retain the abstract information in a prompt can reduce toxicity in the generated text.
What are transformers useful for?
Transformers became extremely popular thanks to their impressive capabilities to generate new text. This even went so far that a Google employee mistakenly thought that transformers have become self-conscious. However, what are the "really" useful applications of transformers in the real world besides generating texts?
Language Translation
Besides generating realistic text to complete prompts like "What's the future of Twitter?" language translation is where transformers really shine.
One of the most recent models includes Meta's No Language Left Behind, a transformer model capable of translating between 200 languages.
Protein Folding
You may have heard of DeepMind's AlphaFold2 model that won the CASP 14 protein folding competition two years ago. Yes, in contrast to the original AlphaFold v1 model, AlphaFold2, is based on the architecture of language transformers.
Recently, Meta announced the ESM Metagenomic Atlas consisting of 620 million metagenomic protein structures generated by the ESMFold protein folding model. While ESMFold is said to be 60x faster than AlphaFold 2.
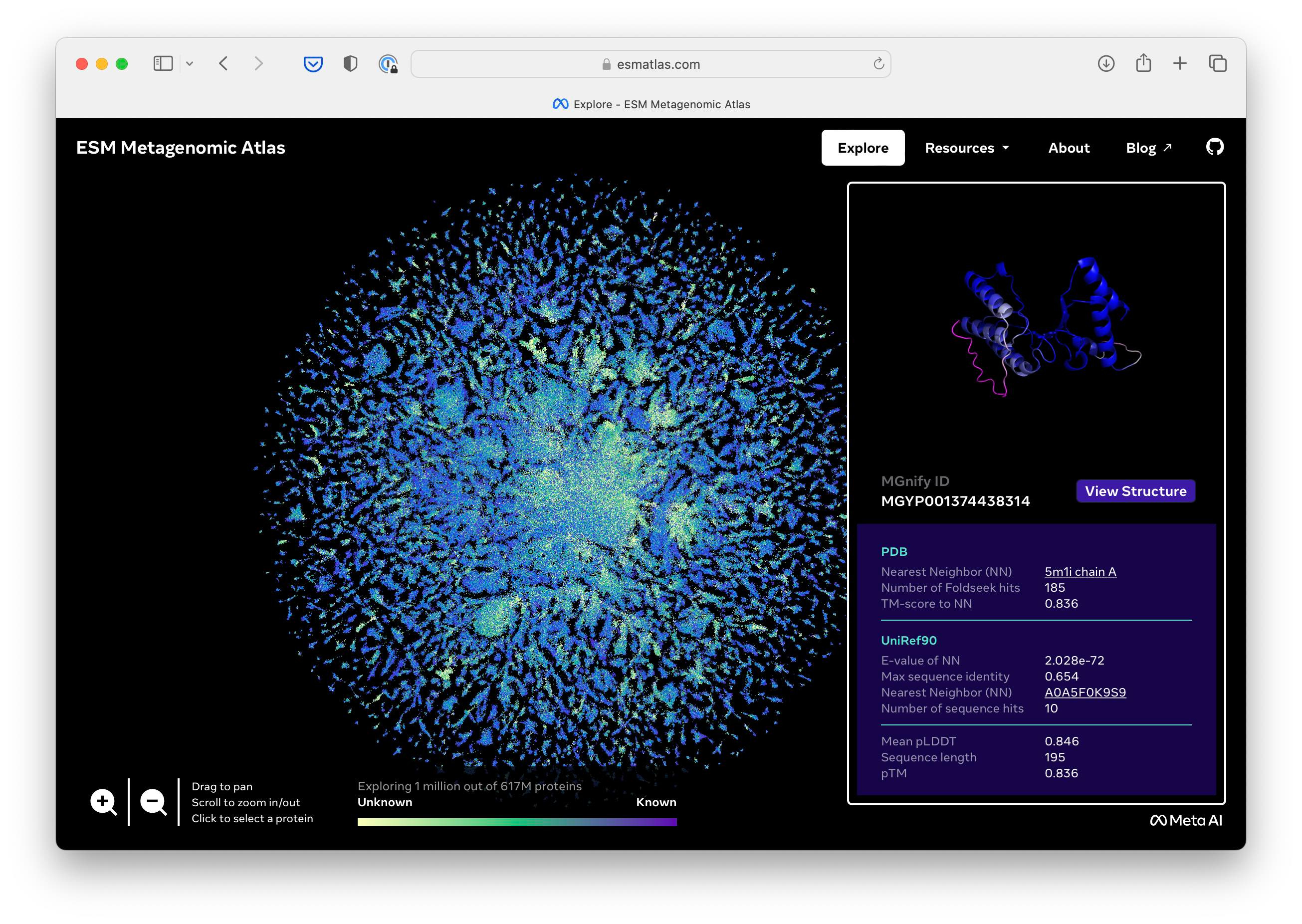
This is great work and a big milestone. In particular, the scale and speed are very impressive. However, I would like to see the CASP15 competition results to get an idea of the model's accuracy on new structures.
Also, it's worth noting that both AlphaFold2 and ESMFold produce accurate structures from protein sequence data. However, they do not solve the actual "protein folding" part or process. Think of these as models that can predict a specific dish (for example, spaghetti bolognese) given a list of ingredients. However, these transformer-based models do not learn the recipe or process of preparing the dish -- they go directly from the ingredient list to the finished meal. Depending on the context, you may consider this as a strength or a weakness.
Question answering
Another area where transformers could have real-world use cases is question-answering. For example, Amazon recently released the multilingual Mintaka dataset consisting of 20,000 question-answer pairs. Mintaka can serve as training data for the next generation of Q&A systems. I hope they will be more useful and capable than the current technologies because who likes interacting with current-gen chatbots?
Approaching AGI?
In my opinion, AGI is nowhere near or around the corner. At the same time, recent language models have awe-inspiring capabilities in generating or translating text and predicting protein structures, as we saw above. Nonetheless, some people might be interested to hear that researchers are working on mechanisms that help transformers to self-improve via a pre-training method called Algorithm Distillation based on reinforcement learning: Large Language Models Can Self-Improve.
Self-attention efficiency and carbon footprints
Researchers consider the original self-attention mechanism (aka scaled-dot product attention) as very inefficient as the memory requirements scale quadratically with the input sequence length. Over the years, researchers developed a lot of alternatives that are more efficient and scale linearly. However, these sparse attention mechanisms remain very unpopular, as we discussed a few months ago.
The unpopularity of self-attention was also included in the recently released State of AI 2022, which observed a similar trend:

This brings up another question. What is the environmental cost of large language models exactly? In the recent Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model paper, researchers found that training BLOOM required 1,082,990 GPU hours (on cutting edge Nvidia A100s) and emitted approximately 50.5 tonnes of CO2 in total! For comparison, a Boeing 747 releases about 33 tonnes of CO2 on a 330-mile flight.
Resources to learn more
Interested in learning more about language transformers? Below is a curated list of useful resources:
Code examples from my book illustrating the self-attention mechanism step by step
Lucas Beyer's transformer seminar
Andrej Karpathy's minimal PyTorch re-implementation of OpenAI's GPT (Generative Pretrained Transformer)
Research Deep Dive
In this section, I will summarize a selected research paper. To stay on topic with the transformer theme of this newsletter, my pick is a large language model, of course! So here it is, Language Models Are Realistic Tabular Data Generators.
The GReaT (Generation of Realistic Tabular data) method uses an auto-regressive generative LLM based on self-attention to generate synthetic tabular datasets. In particular, the authors use pre-trained transformer-decoder networks (GPT-2 and the smaller Distil-GPT-2, as smaller version that was "distilled" similar to DistilBERT.).
Based pretrained decoder-based transformers, the GReaT procedure consists of two steps, (1) finetuning and (2) sampling.
In stage 1, finetuning, GReaT performs the following steps: (1) transform feature vectors into text; (2) permute feature order to encode order independence; (3) use text for transformer finetuning.

And stage 2 (sampling) works as follows: pass (incomplete) inputs to finetuned transformer; (2) obtain completed feature vectors from transformer in text format; (3) transfer feature texts to tabular format.

In "machine learning efficiency" experiments, the authors found that classifiers trained on the artificial data perform better (and more similar to the original) when trained on GReat synthetic data compared to synthetic data from other methods.

Assessing how similar the synthetic data is to the original data, the "distance to closest records" diagrams show that GReaT does not copy the training data. Moreover, the authors did a "discriminator measure" study. They combined the original with the synthetic data and assigned a class label to indicate whether the data was original (0) or synthetic (1). Classifiers trained on these datasets had an average accuracy of 70%; they could tell artificial data to some extent. However, GReat faired much better than other synthetic data approaches (the accuracy ranged between 75% to 88%).

Open Source Highlights
Scikit-learn 1.2.0: Pipelines Can Finally Return Pandas DataFrames
The new version of my all-time favorite machine learning library will bring lots of interesting new features. However, the absolute highlight is the new .set_output() method that we can configure to return DataFrame objects:
For example
scalar = StandardScaler().set_output(transform="pandas")
scalar.fit(X_df)
# X_trans_df is a pandas DataFrame
X_trans_df = scalar.transform(X_df)or
log_reg = make_pipeline(
SimpleImputer(), StandardScaler(), LogisticRegression())
log_reg.set_output(transform="pandas")This will help us eliminate many workarounds in the future where we need to pass around column names.
You can learn more about the other new features in the What's New in v 1.2 docs.
While it is not officially out yet, you can already check out the sklearn 1.2dev0 version by installing the nightly build:
pip install --pre --extra-index https://pypi.anaconda.org/scipy-wheels-nightly/simple scikit-learnEmbetter: Embeddings for Scikit-Learn
I recently stumbled upon embetter, a little scikit-learn compatible library centered around embeddings for computer vision and text. Using embetter, you can build a classifier pipeline that trains a logistic regression model on sentence embeddings of a transformer in 4 lines of code:
text_emb_pipeline = make_pipeline(
ColumnGrabber("text"),
SentenceEncoder('all-MiniLM-L6-v2')
LogisticRegression()
)It probably won't break any predictive performance records, but it's a nice, quick performance baseline when working with text and image datasets.
Lightning 1.8: Colossal AI for Large Transformers
A new Lightning release (formerly PyTorch Lightning) is out! Befitting this language model-themed newsletter issue, it features a new Trainer strategy, Colossal-AI.
# Select the strategy with good defaults
trainer = Trainer(strategy="colossalai")As its name implies, Colossal-AI allows us to train very large transformer models by implementing different parallelism algorithms:
Data parallelism
Pipeline parallelism
1D, 2D, 2.5D, 3D tensor parallelism
Sequence parallelism
Zero redundancy optimization
(What are those and how do they work? This is an excellent topic for the Machine learning Questions & Answers section!)
You can read more about the other features in the new Lightning 1.8 release in the Changelog here.
Better Transformers in PyTorch 1.13
Ahead of the PyTorch Conference next month, there is a new release of PyTorch as well! Among the highlights is the now-stable version of BetterTransformer, which was previously included as a beta version in 1.12. BetterTransformer is geared towards transformer inference in production. You can learn more about it in this tutorial here.
Muse: Diffusion models in production
Our team at Lightning AI launched the Muse app, which showcases how you can put a large model like Stable Diffusion into production. Of course, the code is fully open source.

The app comes with a step-by-step article (Diffusion Models in Production) on lessons learned and things to consider if you want to make your model scale to thousands of users, from autoscaling to dynamic batching.
Machine Learning Questions & Answers
Are you interested in learning something new, trying to practice your knowledge, or prepare for an interview? This section features questions that may (or may not) help!
What are the different mechanisms for parallelizing the training of large machine learning models using multiple GPUs? (Hint: there are at least 5!) And what are the advantages and disadvantages of these multi-GPU training paradigms?
Answers to last week's questions
Question 1: What is the distributional hypothesis in NLP? Where is it used, and how far does it hold true?
According to the distributional hypothesis, words occurring in the same contexts tend to have similar meanings (original source: Distributional Structure by Zellig S. Harris, 1954). In other words, the more similar the meanings of two words are, the more often they appear in similar contexts. So, for example, the words cat and dog often occur in similar contexts and are more related (both are mammals and pets) than a cat and a sandwich. Looking at large datasets, this may hold more or less, but it is easy to construct individual counter-examples.
The distributional hypothesis is the main idea behind Word2vec, and many natural language transformer models rely on this idea (for example, the masked language model in BERT and the next-word pretraining task used in GPT).
Question 2: What is the difference between stateless and stateful training? And when to use which?
Both stateless (re)training and stateful training refer to different ways of training a production model. Stateless training is like a sliding window that retrains the model on different parts of the data from a given data stream. In stateful training, we train the model on an initial batch of data and then update it periodically (as opposed to retraining it) when new data arrives.
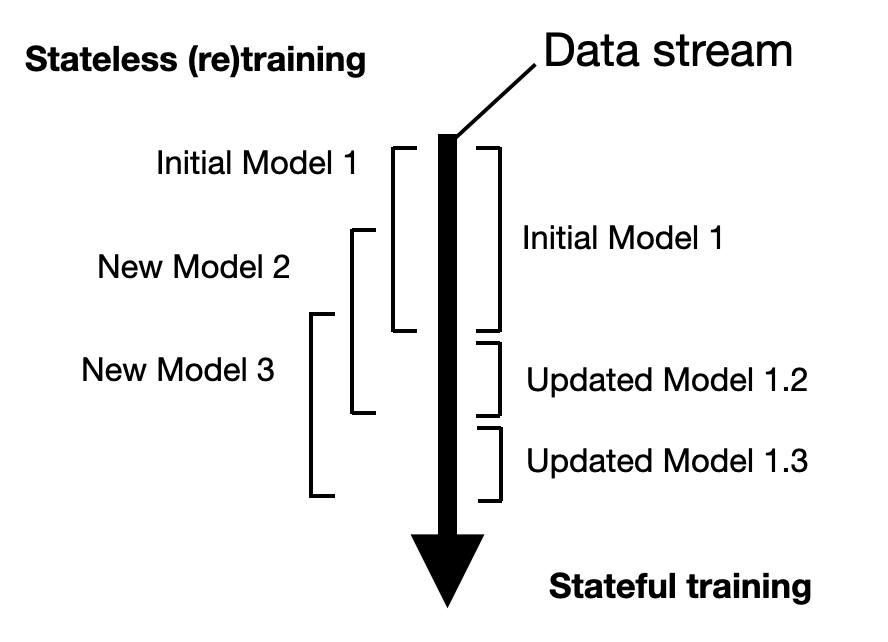
One paradigm is not universally better than the other. However, an advantage of stateful training is that it doesn't require permanent data storage. On the other hand, storing data, if possible, is still a good idea because the model might suffer from "bad" updates, and (temporarily) switching to stateless retraining might make sense.
Question 3: What is the difference between recursion and dynamic programming?
Both recursion and dynamic programming are algorithmic programming techniques.
In recursion, we divide a problem into smaller subproblems in an iterative fashion, often called "divide-and-conquer."
Dynamic programming avoids computing solutions to the same subproblems by storing solutions to subproblems in a data structure that allows fast (constant time) look-ups, for example, dictionaries. Storing the subproblems is also often called "memoization" (not to be confused with "memorization").
In practice, we often apply dynamic programming to recursive algorithms.
Notable Quote
AI/ML as a field moves so so fast. Finding myself saying "back in the day when I was in grad school" when discussing some methods...like a 60-year-old lady. I graduated only two years ago lol.
Upcoming Events
NeurIPS 2022 (the leading machine learning & AI conference) is coming up soon: Nov 28th through Dec 1st, 2022.
If you are attending, stop by and say hello! I'll co-host a workshop social on "Industry, Academia, and the In-Betweens" (the transition from academia to industry). There will be lots of interesting topics to discuss!

You can find more details on the event website here.
PyTorch Conference 2022 is happening on Dec 2nd, 2022 as a satellite event to NeurIPS in New Orleans. If you are planning on attending, I will be there, too -- come say hello!
Study & Productivity Tips
When it comes to productivity workflows, there are a lot of things I'd love to share. However, the one topic many people ask me about is how I keep up with machine learning & AI at large and how I find interesting papers.
From 2018-2021, I served as a moderator for the machine learning category on arXiv. Several times a week, I read the titles of the 100-300 machine learning manuscripts uploaded daily. I can tell you the problem is not finding interesting papers but how to avoid getting distracted -- how to prioritize and manage your time.
The internet is amazing. There is so much cool stuff out there. But the bitter truth is we can't consume it all. This is particularly true for the machine learning field, which is moving too fast and has way too many interesting subcategories: Activation functions, autoML, calibration, causal inference, CNN architectures ...
How I avoid the fear of missing out is to make lists. I have a list of each major category that I find interesting. And there are a lot of categories that are interesting!

In each list, I collect interesting books, research articles, blog posts, videos, Reddit discussions, and sometimes even Twitter threads. Do I read it all? No, keeping up with that would be a full-time job. And I only capture some of the interesting stuff. Typically, I only focus on resources that can help me learn something new (as opposed to building a broad knowledge base and recreating a personal Wikipedia).
Then, I pick out a handful of resources I want to read throughout the week (having a weekly review routine is a topic for another time). Doing this, I realize that 95% of the stuff I captured is not that important (versus some higher priority stuff related to your current project). So, ignoring resources doesn't mean you were lazy or missing out, but that we are defining your priorities and doing the most important stuff. (And hey, keeping these lists is often helpful, sometimes they are very convenient for a writing or research project!)
What are some resources that I use and check?
I have Google Scholar keyword alerts (e.g., for the deep tabular methods I got recently interested in and several others)
I get most of my ML news from following the right people on Twitter
There are also some newsletters that I really like (e.g., Import AI, The Batch)
I sometimes (but rarely) check the ML subreddit
(PS: In the screenshot above, you may have noticed that I use OneNote for these lists. Why OneNote? Like in many contexts, the tool doesn't matter; it's more about the habit and the workflow. I just adopted OneNote for this purpose since it's frictionless for copy & paste (Markdown always requires an extra step for saving and inserting screenshots). Plus, it syncs across devices -- a nice thing when you are at your favorite tea shop or coffee house and want to look something up in a heated discussion. Of course, there are a lot of other tools out there that work equally well or have different trade-offs. But again, the tool doesn't really matter. Just choose what works for you.)
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
It's interesting how you connect prompt engineering to Google queries. Analogy is sharp, though model nuance differs.