

Transformers for Long Inputs and Less Training Data

This article is a compilation of 22 AI research highlights, handpicked and summarized. A lot of exciting developments are currently happening in the fields of natural language processing and computer vision!
Of course, I can't fit all the exciting and promising research papers into the monthly Ahead of AI newsletter. So, below, you'll find a supplementary list of interesting papers I either read or skimmed in the last couple of weeks that didn't make it into the primary newsletter.
Happy reading!
Large Language Models
Scaling Transformer to 1M tokens and beyond with RMT (https://arxiv.org/abs/2304.11062, 19 Apr 2023)
Researchers propose using recurrent memory to extend the input context size to 2 million tokens. For comparison, the GPT-4 model in ChatGPT currently supports up to 8,192 tokens. The main idea in this paper is to pass the output, as a memory, along with the input sequence embeddings of the next segment, in a recursive fashion.

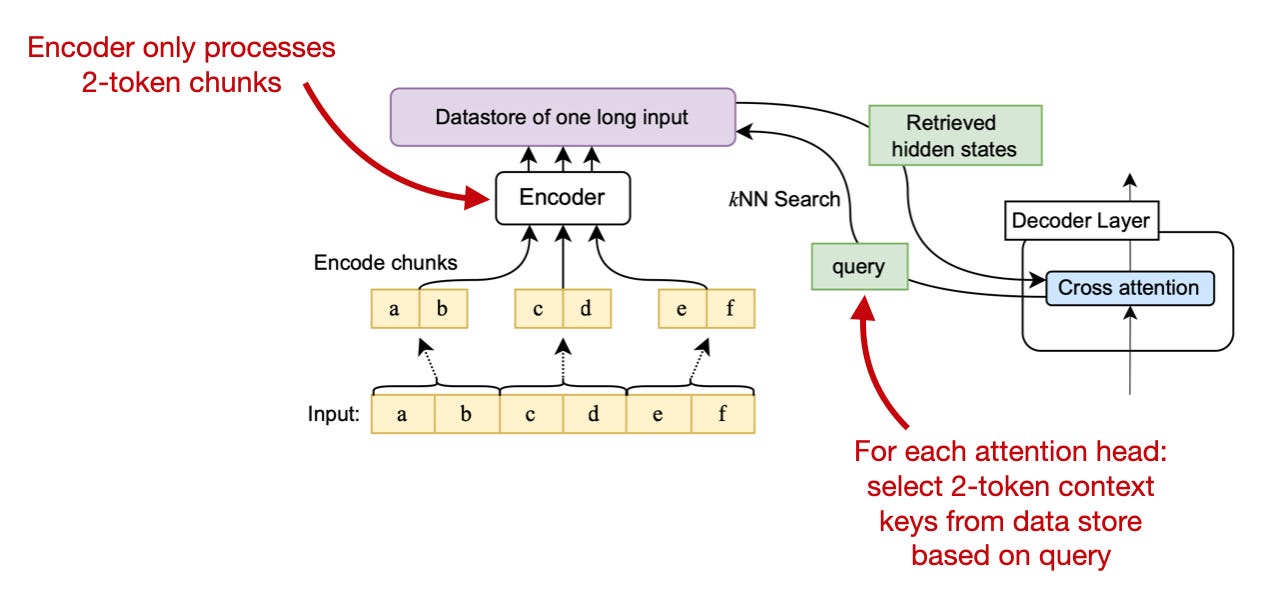
Unlimiformer: Long-Range Transformers with Unlimited Length Input (https://arxiv.org/abs/2305.01625, 2 May 2023)
This method is a wrapper around existing pretrained LLMs without any additional weight tuning, proposing to offload the self-attention mechanism to a k-nearest neighbor (k-NN) look-up. The idea is to encode longer inputs into smaller chunks that are stored in a database. The chunks are then retrieved via k-NN for each attention head.
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes (https://arxiv.org/abs/2305.02301, 3 May 2023)
Researchers propose a distillation mechanism to curate task-specific smaller models that exceed the performance of standard finetuning with less training data. First, they extract a rationale (a sort of reworded prompt) via a large LLM. These rationales and class labels are then used to train smaller task-specific models in supervised fashion.

Training Language Models with Language Feedback at Scale (https://arxiv.org/abs/2303.16755, 9 Apr 2023)
Recent methods for LLM finetuning, such as reinforcement learning with human feedback (as used by ChatGPT), involve comparisons between pairs of model-generated outputs in the finetuning procedure (e.g., to develop the reward model). Here, researchers develop an alternative approach called Imitation learning from Language Feedback (ILF): (1) the user asks the model to generate a response; (2) the user then asks to change something about the response; (3) the LLM is finetuned on the refined response.

ResiDual: Transformer with Dual Residual Connections (https://arxiv.org/abs/2304.14802, 28 Apr 2023)
Following the original Attention Is All You Need Transformer architecture, there's always been an ongoing discussion about where to put the layer normalization (e.g., see Xiong et al.). Residual connections before the layer norm (Pre-LN) can result in representation collapse and residual connections after layer norm (Post-LN) can result in vanishing gradient problems. In this paper, the researchers propose fusing the connections in Post-LN and Pre-LN to inherit their advantages while avoiding their limitations.

Someone pointed out that this has already been shown in NormFormer with a less convoluted architecture (http://arxiv.org/abs/2110.09456).
Learning to Compress Prompts with Gist Tokens (https://arxiv.org/abs/2304.08467, 17 Apr 2023)
Prompt engineering is getting a lot of attention these days (no pun intended), but isn't it wasteful to rerun similar prompts repeatedly through the LLM? Researchers develop "gist" tokens that compress the task into special tokens to save compute. The idea is similar to soft prompt tuning, which I wrote about recently, but it also generalizes to novel prompts.

Are Emergent Abilities of Large Language Models a Mirage? (https://arxiv.org/abs/2304.15004, 28 Apr 2023)
In LLM contexts, we use the term emergent abilities to refer to abilities that are not explicitly taught during training (e.g., summarization, translation, and so forth) but emerge as a byproduct of the model's ability to understand and generate text based on the vast amount of information it has been exposed to. In this recent analysis, researchers find strong evidence that these emergent abilities are not a consequence of just scaling these LLMs to larger sizes. The researchers suggest that the emergent abilities are an illusion that arises from picking a specific performance metric and thus emergent abilities "may be creations of the researcher's choices".
On the Possibilities of AI-Generated Text Detection (https://arxiv.org/abs/2304.04736, 10 Apr 2023)
Given the increased number of LLMs and LLM-generated text, researchers revisit the frequently debated topic of whether AI-generated can be reliably detected. In this work, the researchers show that the answer is Yes. Based on information-theoretic bounds, it should be possible to detect AI-generated text given a sufficient sample size in most cases.
Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision (https://arxiv.org/abs/2305.03047, 4 May 2023)
Researchers introduce Dromedary, which beats the comparable Alpaca model, which is, in-turn, a finetuned LLaMA model. In contrast to ChatGPT, Dromedary does not use reinforcement learning with human feedback; it also doesn't require extracting ChatGPT prompts-pairs like Alpaca. Instead, they propose a novel self-align approach that includes appending guidelines to the instruction prompt.
Fundamental Limitations of Alignment in Large Language Models (https://arxiv.org/abs/2304.11082, 19 Apr 2023)
Since the release of ChatGPT in November 2022, much LLM research has focused on instruction-finetuning and aligning LLMs to be more helpful and less harmful for users. This research paper proposes a theoretical approach, called Behavior Expectation Bounds (BEB), that shows alignment can only reduce but not prevent undesirable and harmful behavior. The conclusion is that aligned LLMs are not safe against adversarial prompting attacks.
Evaluating Verifiability in Generative Search Engines (https://arxiv.org/abs/2304.09848, 19 Apr 2023)
LLM-powered generative search engines are on the rise. Researchers audited Bing Chat, NeevaAI, Perplexity AI, and YouChat finding that while responses appear informative and fluent, only 51.5% of the generated sentences are entirely backed by citations. A mere 74.5% of the citations actually provide support for the corresponding sentence.

StarCoder: may the source be with you! (https://arxiv.org/abs/2305.06161, 9 May 2023)
Researchers trained an 15.5B parameter LLM with a 8k context width on 1 trillion tokens of open-source code scraped from GitHub (via The Stack dataset). After creating this StarCoderBase foundation model, the researchers finetuned it on 35 billion Python tokens. The resulting StarCoder model outperforms every other Code LLM today.
Emergent autonomous scientific research capabilities of large language models (https://arxiv.org/abs/2304.05332, 11 Apr 2023)
The authors chained together multiple LLMs into a multi-LLMs-based Intelligent Agent capable of designing and planning chemistry experiments, including using tools and browsing internet experiments. From a technical standpoint, it's interesting how they connected multiple LLMs in a fashion that actually works so well. But despite the catchy headline, this system does not appear capable of replacing actual researchers coming up with novel hypotheses and designs.
scGPT: Towards Building a Foundation Model for Single-Cell Multi-omics Using Generative AI https://www.biorxiv.org/content/10.1101/2023.04.30.538439v1, May 1)
It's always interesting to see general methods such as transformers being applied to other fields. Here, the researchers use the generative pretraining of LLMs to pretrain a foundation model on single-cell sequencing data, such as genes. The resulting pretrained model exhibits zero-shot and clustering capabilities of gene networks.
PMC-LLaMA: Further Finetuning LLaMA on Medical Papers (https://arxiv.org/abs/2304.14454, 27 Apr 2023)
Another application of LLMs to domain-specific data, but here it's finetuning (not pretraining). Researchers found that a finetuned LLaMA model (finetuned on medical data) outperformed the pretrained base model on medical tasks and ChatGPT. This is as expected, but it is another example that finetuning LLMs will become more and more relevant in the future as companies want to optimize LLM task performance.
Computer Vision
Diffusion Models as Masked Autoencoders (https://arxiv.org/abs/2304.03283, 6 Apr 2023)
In contrast to large language models, pretraining diffusion models do not produce strong representations that could be used in other downstream tasks. However, researchers formulated diffusion models as masked autoencoders to address that. This could spawn new, interesting work on diffusion foundation models for image tasks.

Segment Anything (https://arxiv.org/abs/2304.02643, 5 Apr 2023)
Meta's Segment Anything project introduces a new task, model, and dataset for image segmentation. The accompanying image datasets the largest segmentation dataset to date with over 1 billion masks on 11 million images. What's especially laudable is that the researchers used licensed and privacy-respecting images, so the model can be open-sourced without major copyright concerns.

Segment Everything Everywhere All at Once (https://arxiv.org/abs/2304.06718, 13 May 2023)
Similar to the Segment Anything approach mentioned above, this paper proposes a promptable, interactive model for image segmentation. However, going beyond Segment Anything, this project offers more interaction types and supports higher-level semantic tasks. The researchers say that whereas Segment Anything prompts are limited to limited to points, boxes, and text, their model also supports other prompts, and it can also perform panoptic and instance segmentation.

Generative Disco: Text-to-Video Generation for Music Visualization (https://arxiv.org/abs/2304.08551, 17 Apr 2023)
As mentioned in the previous issue of Ahead and AI, we will be seeing more creative multimodal efforts in the upcoming months, this being one of them where the researchers generate video clips from music user prompts. The text-to-image model proposed in this paper can create a wide variety of videos. Example outputs include abstract animations and animated characters that appear to sing along.
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models (https://arxiv.org/abs/2304.08818, 18 Apr 2023)
This extends the diffusion model (text-to-)image generator idea to generate videos. Interestingly, researchers were able to leverage off-the-shelf pre-trained image diffusion models for this text-to-video project.

Stable and low-precision training for large-scale vision-language models (https://arxiv.org/abs/2304.13013, 25 Apr 2023)
It's pretty common to train various models with bfloat16 (and mixed precision), and with NVIDIA's new H100 GPUs, 8-bit floats are also being supported. But what about quantized training? Researchers introduce Switch-Back, a linear layer for int8 quantized training that outperforms the existing LLM.int8() baseline and matches bfloat16 in accuracy while being ~20% faster.

Patch Diffusion: Faster and More Data-Efficient Training of Diffusion Models (https://arxiv.org/abs/2304.12526 25 Apr 2023)
Patch diffusion speeds up training time of diffusion models 2x by improving data efficiency while maintaining the same image quality. In this specific case, the researchers only required 5,000 training examples to train a competitive model. The idea of this method is to include patch-level information from randomly cropped image patches.
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
I really enjoy these sorts of compilations, especially when you include an infographic from the paper. I might be different, but I'd even prefer 2 sentences and more papers covered.
Great time-saving knowledge distillation