

Categories of Inference-Time Scaling for Improved LLM Reasoning
And an Overview of Recent Inference-Scaling Papers (Including Recursive Language Models)

Inference scaling has become one of the most effective ways to improve answer quality and accuracy in deployed LLMs.
The idea is straightforward. If we are willing to spend a bit more compute, and more time at inference time (when we use the model to generate text), we can get the model to produce better answers.
Every major LLM provider relies on some flavor of inference-time scaling today. And the academic literature around these methods has grown a lot, too.
Back in March, I wrote an overview of the inference scaling landscape and summarized some of the early techniques.

In this article, I want to take that earlier discussion a step further, group the different approaches into clearer categories, and highlight the newest work that has appeared over the past few months.
As part of drafting a full book chapter on inference scaling for Build a Reasoning Model (From Scratch), I ended up experimenting with many of the fundamental flavors of these methods myself. With hyperparameter tuning, this quickly turned into thousands of runs and a lot of thought and work to figure out which approaches should be covered in more detail in the chapter itself. (The chapter grew so much that I eventually split it into two, and both are now available in the early access program.)
PS: I am especially happy with how the chapter(s) turned out. It takes the base model from about 15 percent to around 52 percent accuracy, which makes it one of the most rewarding pieces of the book so far.
What follows here is a collection of ideas, notes, and papers that did not quite fit into the final chapter narrative but are still worth sharing.
I also plan to add more code implementations to the bonus materials on GitHub over time.
Table of Contents (Overview)
Inference-Time Scaling Overview
Chain-of-Thought Prompting
Self-Consistency
Best-of-N Ranking
Rejection Sampling with a Verifier
Self-Refinement
Search Over Solution Paths
Conclusions, Categories, and Combinations
Bonus: What Do Proprietary LLMs Use?
You can use the left-hand navigation bar in the article’s web view to jump directly to any section.
1. Inference-Time Scaling Overview
Inference-time scaling (also called inference-compute scaling, test-time scaling, or just inference scaling) is an umbrella term for methods that allocate more compute and time during inference to improve model performance.
This idea has been around for a long time, and one can think of ensemble methods in classic machine learning as an early example of inference-time scaling. I.e., using multiple models requires more compute resources but can give better results.
Even in LLM contexts, this idea has been around for a long time. However, I remember it became particularly popular (again) when OpenAI showed an inference-time scaling and training plot in one of their o1 announcement blog articles last year (Learning to Reason with LLMs).
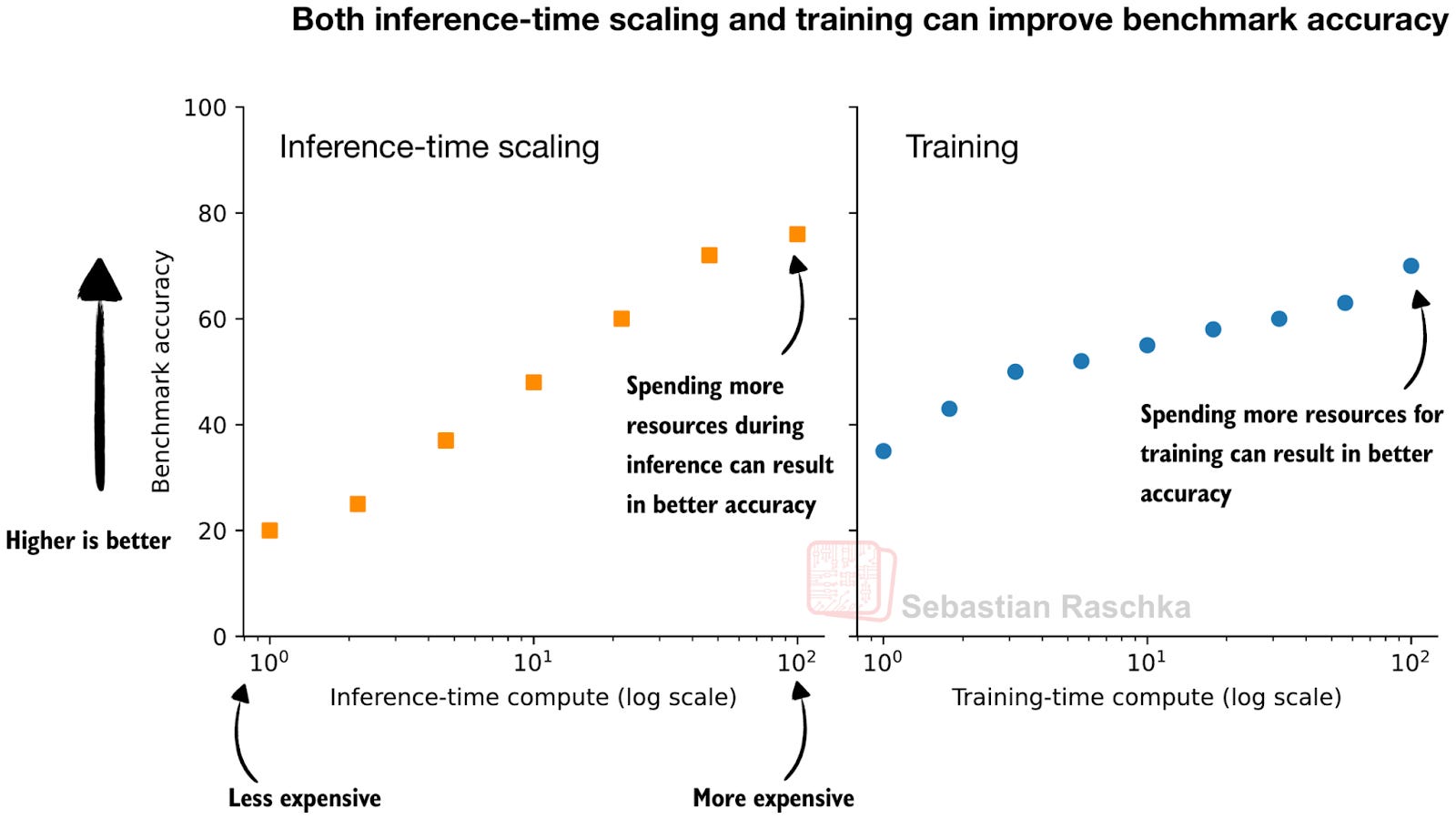
I think this figure, adapted from OpenAI’s blog post, nicely captures the idea behind the two knobs we can use to improve LLMs. We can spend more resources during training (more data, bigger models, more or longer training stages) or inference.
Actually, in practice, it’s even better to do both at the same time: train a stronger model and use additional inference scaling to make it even better.
In this article, I only focus on the left part of the figure, inference-time scaling techniques, i.e., those training-free techniques that don’t change the model weights.