



Finetuning LLMs Efficiently with Adapters

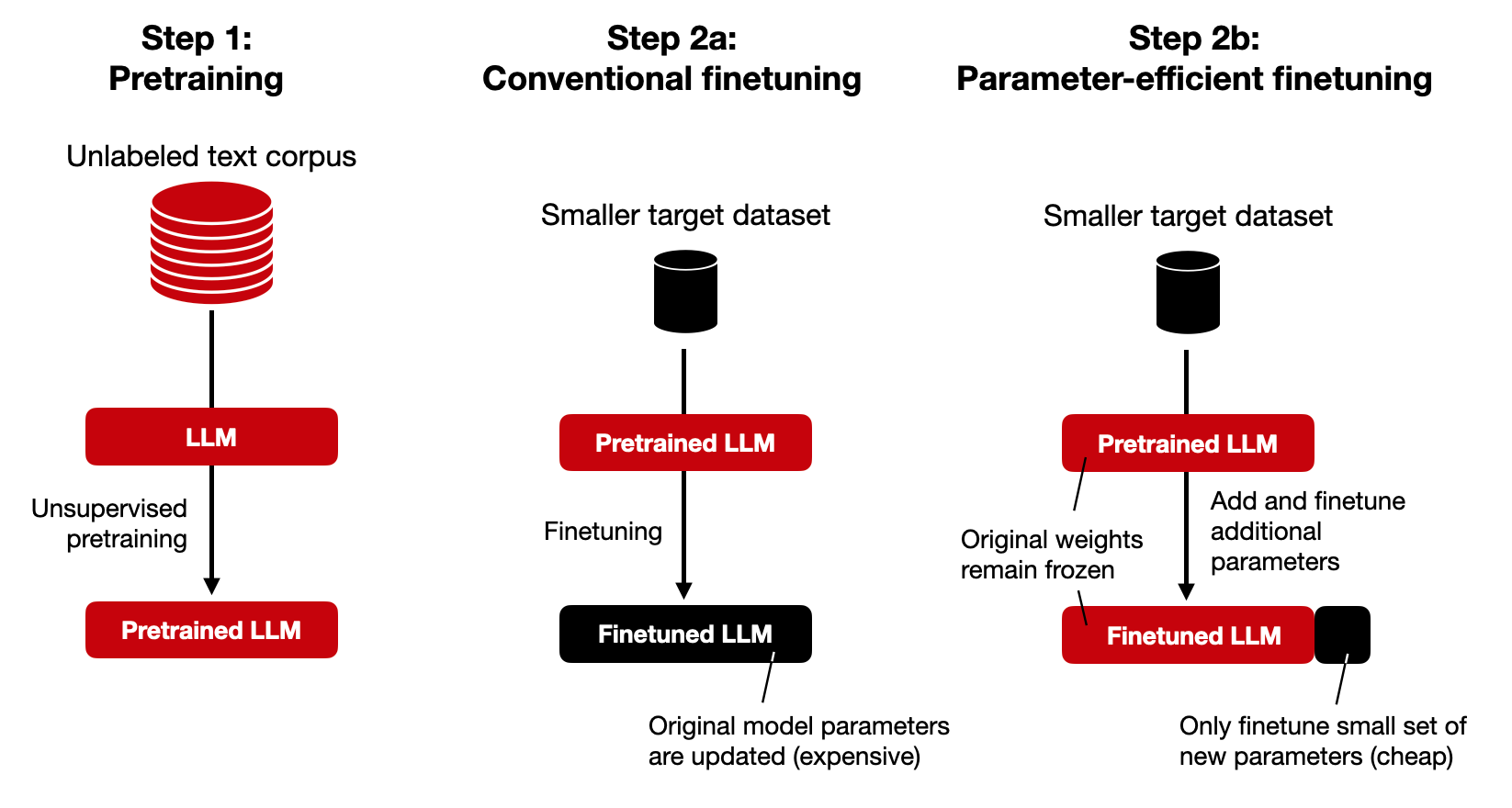
Why Finetuning LLMs?
Large language models (LLMs) like BERT, GPT-3, GPT-4, LLaMA, and others are trained on a large corpus of data and have general knowledge. However, they may not perform as well on specific tasks without finetuning. For example, if you want to use a pretrained LLM for analyzing legal or medical documents, finetuning it on a corpus of legal documents can significantly improve the model's performance. (Interested readers can find an overview of different LLM finetuning methods in my previous article, Finetuning Large Language Models: An Introduction To The Core Ideas And Approaches.)
However, finetuning LLMs can be very expensive in terms of computational resources and time, which is why researchers started developing parameter-efficient finetuning methods.
Parameter-Efficient Finetuning Methods
As discussed in a previous article, many different types of parameter-efficient methods are out there. In an earlier post, I wrote about prompt and prefix tuning. (Although the techniques are somewhat related, you don't need to know or read about prefix tuning before reading this article about adapters.)
In a nutshell, prompt tuning (different from prompting) appends a tensor to the embedded inputs of a pretrained LLM. The tensor is then tuned to optimize a loss function for the finetuning task and data while all other parameters in the LLM remain frozen. For example, imagine an LLM pretrained on a general dataset to generate texts. Prompt (fine)tuning would entail taking this pretrained LLM, adding prompt tokens to the embedded inputs, and then finetuning the LLM to perform, for example, sentiment classification on a finetuning dataset.
The main idea behind prompt tuning, and parameter-efficient finetuning methods in general, is to add a small number of new parameters to a pretrained LLM and only finetune the newly added parameters to make the LLM perform better on (a) a target dataset (for example, a domain-specific dataset like medical or legal documents) and (b) a target task (for example, sentiment classification).
In this article, we are now discussing a related method called adapters, which is centered around the idea of adding tunable layers to the various transformer blocks of an LLM, as opposed to only modifying the input prompts.

Adapters
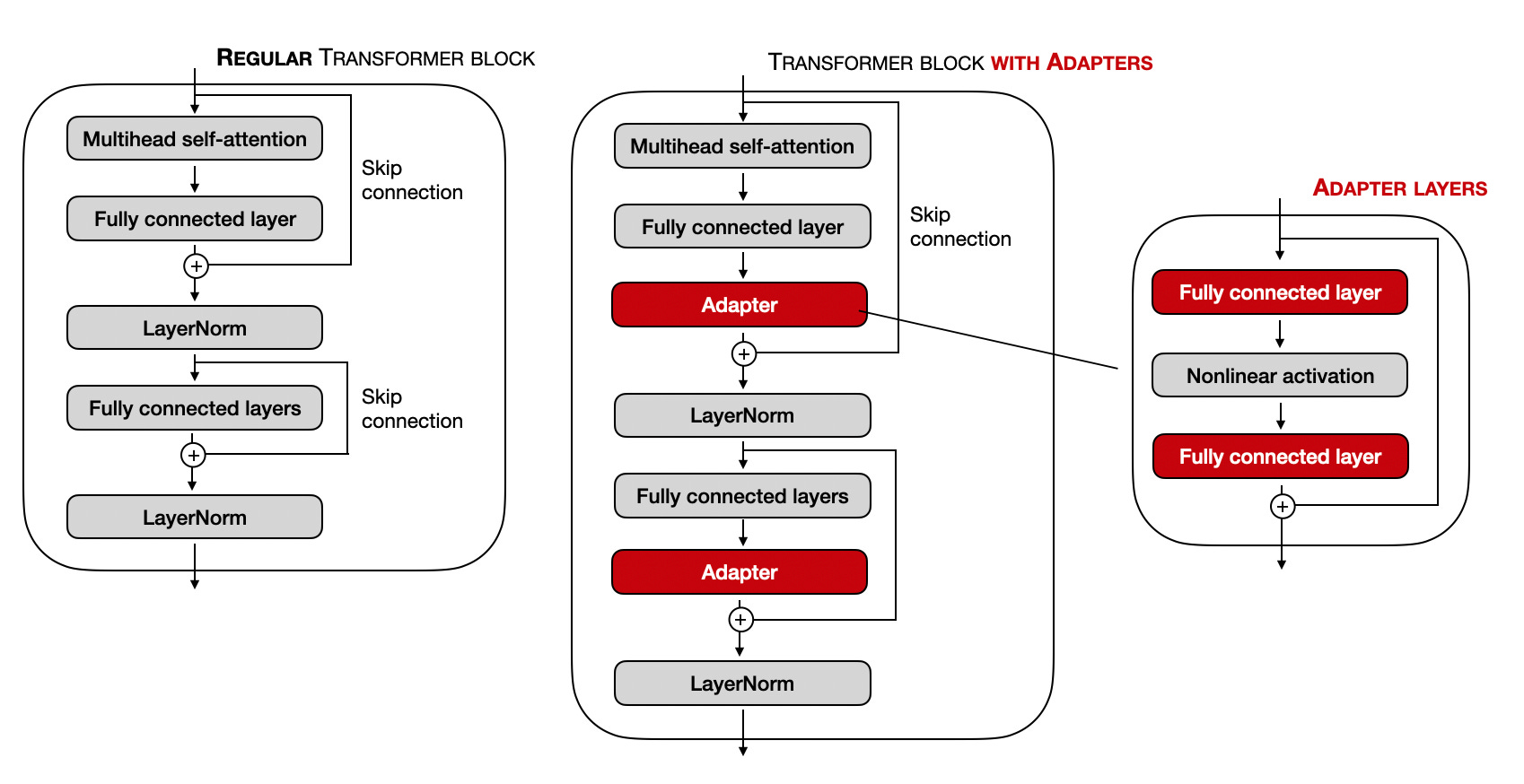
The original adapter method (Houlsby et al. 2019) is somewhat related to the aforementioned prefix tuning method as they also add additional parameters to each transformer block. However, while prefix tuning prepends tunable tensors to the embeddings, the adapter method adds adapter layers in two places, as illustrated in the figure below.
And for readers who prefer (Python) pseudo-code, the adapter layer-modification can be written as follows:

Note that the fully connected layers of the adapters are usually relatively small and have a bottleneck structure similar to autoencoders. Each adapter block's first fully connected layer projects the input down onto a low-dimensional representation. The second fully connected layer projects the input back into the input dimension. How is this parameter efficient? For example, assume the first fully connected layer projects a 1024-dimensional input down to 24 dimensions, and the second fully connected layer projects it back into 1024 dimensions. This means we introduced 1,024 x 24 + 24 x 1,024 = 49,152 weight parameters. In contrast, a single fully connected layer that reprojects a 1024-dimensional input into a 1,024-dimensional space would have 1,024 x 1024 = 1,048,576 parameters.
According to the original adapter paper, a BERT model trained with the adapter method reaches a modeling performance comparable to a fully finetuned BERT model while only requiring the training of 3.6% of the parameters. Moreover, the researchers included a figure where they compared the adapter method to only finetung the output (top) layers of a BERT model and found that using adapters, it's possible to match the finetuning top-layer-finetuning performance with a much smaller number of parameters:

Conclusion
Finetuning pre-trained large language models (LLMs) is an effective method to tailor these models to suit specific business requirements and align them with target domain data. This process involves adjusting the model parameters using a smaller dataset relevant to the desired domain, which enables the model to learn domain-specific knowledge and vocabulary.
However, as LLMs are "large," updating multiple layers in a transformer model can be very expensive, so researchers started developing parameter-efficient alternatives.
In this article, we discussed several parameter-efficient alternatives to the conventional LLM finetuning mechanism. In particular, we discussed how to insert and finetune additional adapter layers to improve the predictive performance of an LLM compared to training the original model parameters.
Additional Experiments
Additional Code Examples and Adapter Experiment
Below are additional experiments where I implemented the adapter method and ran a comparison to finetune a DistilBERT model for sentiment classification:
finetuning only the last two layers as a performance baseline;
inserting and finetuning adapter layers;
finetuning all layers of the original model;
inserting adapter layers and finetuning all layers as a control experiment.

All code examples are available here on GitHub.
As a thanks to those who supported the newsletter in the previous months, I included a bonus section below discussing the code examples. Thanks again for your support!
1. A Finetuning Baseline
First, let's establish a performance baseline by only finetuning the last layers of a DistilBERT model on a movie review dataset. Here, we will only look at the relevant lines of code, omitting the non-finetuning specific code for brevity. However, as mentioned above, the full code examples are available here.
First, after loading the pretrained DistilBERT model, let's look at the architecture:

For this performance baseline, we only finetune the last two layers, which comprise 592,130 parameters. The simplest way to do that is to freeze all parameters and then unfreeze the last two layers via the code below:
# Freeze all layers
for param in model.parameters():
param.requires_grad = False
# Unfreeze the two output layers
for param in model.pre_classifier.parameters():
param.requires_grad = True
for param in model.classifier.parameters():
param.requires_grad = True
Then, after training this model for 3 epochs, we get the following results:
Training time: 2.89 min
Training accuracy: 86.7%
Validation accuracy: 87.2%
Test accuracy: 86.4%
2. Adding Adapter Layers
Next, let's add the adapter layers to the model. Notice that DistilBERT has 6 transformer blocks. As discussed earlier, the adapter method inserts 2 adapter modules into each of the 6 transformer blocks, as shown in the figure below:

Each adapter module consists of 2 fully connected layers with a nonlinear activation in-between. In code, we can define a make_adapter function that creates such an adapter module as follows:
def make_adapter(in_dim, bottleneck_dim, out_dim):
adapter_layers = torch.nn.Sequential(
torch.nn.Linear(in_dim, bottleneck_dim),
torch.nn.GELU(),
torch.nn.Linear(bottleneck_dim, out_dim),
)
return adapter_layersThen, we can use the make_adapter function to insert the adapter layers into the 6 transformer blocks, as shown below:
total_size = 0
bottleneck_size = 32 # hyperparameter
for block_idx in range(6):
###################################################
# insert 1st adapter layer into transformer block
###################################################
orig_layer_1 = model.distilbert.transformer.layer[block_idx].attention.out_lin
adapter_layers_1 = make_adapter(
in_dim=orig_layer_1.out_features,
bottleneck_dim=bottleneck_size,
out_dim=orig_layer_1.out_features)
new_1 = torch.nn.Sequential(orig_layer_1, *adapter_layers_1)
model.distilbert.transformer.layer[block_idx].attention.out_lin = new_1
total_size += count_parameters(adapter_layers_1)
###################################################
# insert 2nd adapter layer into transformer block
###################################################
orig_layer_2 = model.distilbert.transformer.layer[block_idx].ffn.lin2
adapter_layers_2 = make_adapter(
in_dim=orig_layer_2.out_features,
bottleneck_dim=bottleneck_size,
out_dim=orig_layer_2.out_features)
new_2 = torch.nn.Sequential(orig_layer_2, *adapter_layers_2)
model.distilbert.transformer.layer[block_idx].ffn.lin2 = new_2
total_size += count_parameters(adapter_layers_2)
print("Number of adapter parameters added:", total_size)Number of adapter parameters added: 599,424The modified DistilBERT architecture is shown in the figure below:

Notice that using a bottleneck size of 32, we added 599,424 new parameters to the model. In comparison, the 2 fully connected layers we finetuned earlier have 592,130 parameters in total, which is approximately the same number of parameters to finetune. If we finetune this modified model, where all layers except the adapter layers are frozen, we get the following results:
Training time: 5.69 min
Training accuracy: 90.0%
Validation accuracy: 89.1%
Test accuracy: 88.4%
3. Finetuning All Layers
Now, for comparison, let's look at the results from finetuning all layers. For this, we are loading the DistilBERT model and training it as is (without freezing any layers).
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2)def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
num_param = count_parameters(model.pre_classifier) + count_parameters(model.classifier)
print("Parameters in last 2 layers:", num_param)66955010The result from finetuning all 66.9 million parameters are as follows:
Training time: 7.12 min
Training accuracy: 96.6%
Validation accuracy: 92.9%
Test accuracy: 93.0%
4. Inserting Adapter Layers and Finetuning All Layers
Lastly, let's add a control experiment, where we train the model modified with the adapter layers in Section 2, but making all parameters trainable. That's 599,424 + 66,955,010 = 67,554,434 in total.
Training time: 7.62 min
Training accuracy: 98.4%
Validation accuracy: 91.5%
Test accuracy: 91.1%
Result Analysis and Summary
Now that we gathered all the results via the experiments above, let's look at the summary plots below.
As we can see, finetuning the adapter layers outperforms finetuning only the last layers. This is a nice, positive, but not unexpected outcome, consistent with the adapter paper results.
However, finetuning the adapter layers (2) takes almost twice as finetuning the last two layers only (1). The number of trainable parameters in (1) and (2) is practically identical. However, the adapter layer model has several additional layers in the forward pass, which can explain the extra training time.
Now, looking at method (3), finetuning the whole network does still outperform the adapter method (3). Still, it is, of course, also computationally more expensive, which is expected since we have a substantially larger number of parameters (66 million versus 600 thousand).
Lastly, finetuning all layers plus adapter layers (4) performs better than only finetuning the adapter layers (2). However, (4) performs worse than finetuning all layers (3), which is surprising at first glance since (4) has 600,000 additional parameters compared to (3). If we look at the training set, we can see that method (4) overfits more, which is a possible explanation for why method (4) performs worse than (3) despite the additional parameters.

All in all, we can see that the adapter method is an attractive alternative to only finetuning the last layers, even though it increases the computational time and is not as good as finetuning all layers.
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Hi Sebastian,
Just wanted to say thank you — your work on PEFT and LoRA really inspired me to explore this space. I recently published a blog on fine-tuning Mistral-7B using LoRA and wanted to share it with you:
https://open.substack.com/pub/ankitamungalpara/p/how-to-fine-tune-mistral-7b-model?r=5hh66x&utm_campaign=post&utm_medium=web&showWelcomeOnShare=true
Appreciate your clear explanations! Thank you. 🙏