

Llama 2, Flash-Attention 2, and More

Every month is a busy month for LLM research. However, this month has been particularly interesting due to the release of new state-of-the-art base models, such as Meta's Llama 2 model suite. Double kudos: this new iteration of Llama models comes without any major restrictions and a very detailed 77-page report on arXiv!
I am still compiling all my notes and thoughts after reading through this 77-pager for the next main issue of this newsletter -- coming soon! However, in the meantime, I wanted to share some of the main takeaways in the monthly Research Highlights (next to many other interesting works) below.
Large Language Models
Llama 2: Open Foundation and Fine-Tuned Chat Models (19 Jul, https://arxiv.org/abs/2307.09288)
Researchers announced the Llama 2 model suite, the successor of Meta's popular LLaMA model, via an in-depth 77-page research report. Along with the Llama 2 base models, ranging from 7B to 70B parameters, they also released Llama 2-Chat models, which were trained similarly to InstructGPT and ChatGPT using reinforcement learning with human feedback (RLHF). The Llama 2 license is less restrictive than the license of its predecessor, now allowing commercial use (with some restrictions).

FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (17 Jul, https://arxiv.org/abs/2307.08691)
FlashAttention-2 is the successor of the popular FlashAttention algorithm, an optimized multihead self-attention implementation that results in both memory savings and runtime speed-ups (2-4x compared to the PyTorch baseline). It is important to highlight that it functions as a drop-in replacement and doesn't change or affect the modeling performance, which is super nice. The new contribution here is to parallelize the attention computation within each head and to distribute the work through shared memory to reduce communication overheads.

Retentive Network: A Successor to Transformer for Large Language Models (17 Jul, https://arxiv.org/abs/2307.08621)
This paper proposed another alternative to large language transformers, one that has linear instead of quadratic complexity with respect to the input sequence lengths. RetentionNet can be trained in a parallel mode and switched to a recurrent model to extend context lengths without increasing memory cost to achieve good inference performance. The largest model was 6.7B parameters, and it will be interesting to see future studies comparing RetNet to Llama-2 70B and others.

AlpaGasus: Training A Better Alpaca with Fewer Data (17 Jul, https://arxiv.org/abs/2307.08701)
Next to LIMA, this is another interesting paper highlighting that more data is not always better when finetuning LLMs. Using ChatGPT to identify low-quality instruction-response pairs, the authors find that the original 52k Alpaca dataset can be trimmed to 9k instruction-response pairs to improve the performance when training 7B and 13B parameter (LLaMA) LLMs.

Stack More Layers Differently: High-Rank Training Through Low-Rank Updates (11 Jul, https://arxiv.org/abs/2307.05695)
Low-rank adaptation (LoRA) is one of the most popular methods for parameter-efficient LLM finetuning -- I wrote about it in more detail here. In this paper, researchers explore whether LoRA can be used for pretraining (as opposed to finetuning) LLMs in a parameter-efficient manner, proposing a method called ReLoRA. While the researchers only pretrained models up to 350 M parameters (the smallest Llama model is 7 B parameters, for comparison), the approach appears promising.

Do Multilingual Language Models Think Better in English? (Aug 2, https://arxiv.org/abs/2308.01223)
Suppose users want to use models such as LLaMA on non-English inputs. There are three options:
Prompt the model in a non-English language.
Use an external translation system first to translate the prompt into English.
Let the LLM itself translate the prompt into English first (the proposed method).
In this paper, the authors find that models like XGLM and LLaMA work better if they first translate a prompt (3) compared to prompting in the original language (1).

How is ChatGPT's behavior changing over time? (18 Jul, https://arxiv.org/abs/2307.09009)
In this paper, researchers make an interesting observation that GPT-4's modeling performance appears to be getting worse over time. Is it due to distillation methods to save costs or guard rails to prevent certain types of misuse? It is interesting to see research efforts being diverted into studying these changes that could likely already be answered by a researcher and engineers who worked on these models.

Skill-it! A Data-Driven Skills Framework for Understanding and Training Language Models (Jul 26, https://arxiv.org/abs/2307.14430)
Researchers propose a new approach for improving LLM training efficiency with an online sampling algorithm. At first glance, it appears similar to curriculum learning, where the goal is to select training data during training. However, here the focus is to select training data by skill instead of selecting training examples by difficulty.

In-context Autoencoder for Context Compression in a Large Language Model (13 Jul, https://arxiv.org/abs/2307.06945)
The proposed method uses an in-context autoencoder model (encoder) to compress the inputs (contexts) for a target LLM (decoder). This autoencoder is an LLM trained with low-rank adaptation (LoRA) that is first pretrained on an unlabeled large corpus and then finetuned on a smaller instruction dataset. Using this auxiliary autoencoder LLM, the authors achieved 4x context compression.

No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-based Language Models (12 Jul, https://arxiv.org/abs/2307.06440)
In this paper, the authors evaluate three categories of efficient training methods for transformers:
Dynamic architectures (layer stacking, layer dropping)
Batch selection (selective backprop, RHO loss)
Efficient optimizers (Lion, Sophia)
Somewhat consistent with my (more limited) anecdotal experience, the gains are negligible compared to regular training (baseline). Note that the paper only focuses on encoder-style and encoder-decoder-style LLMs (BERT, T5) and doesn't investigate parameter-efficient finetuning methods such as LoRA or Adapters.

Computer Vision and Multimodal Models
Substance or Style: What Does Your Image Embedding Know? (10 Jul, https://arxiv.org/abs/2307.05610)
So-called probing methods are small models that are applied to text embeddings to analyze the properties of LLMs (see Probing Classifiers: Promises, Shortcomings, and Advances) and convolutional neural networks. In this work, the authors apply probing techniques to transformer-based vision models. Interestingly, the pretraining task (supervised, contrastive, masking, etc.) determines the type of non-semantic information the embeddings contain.

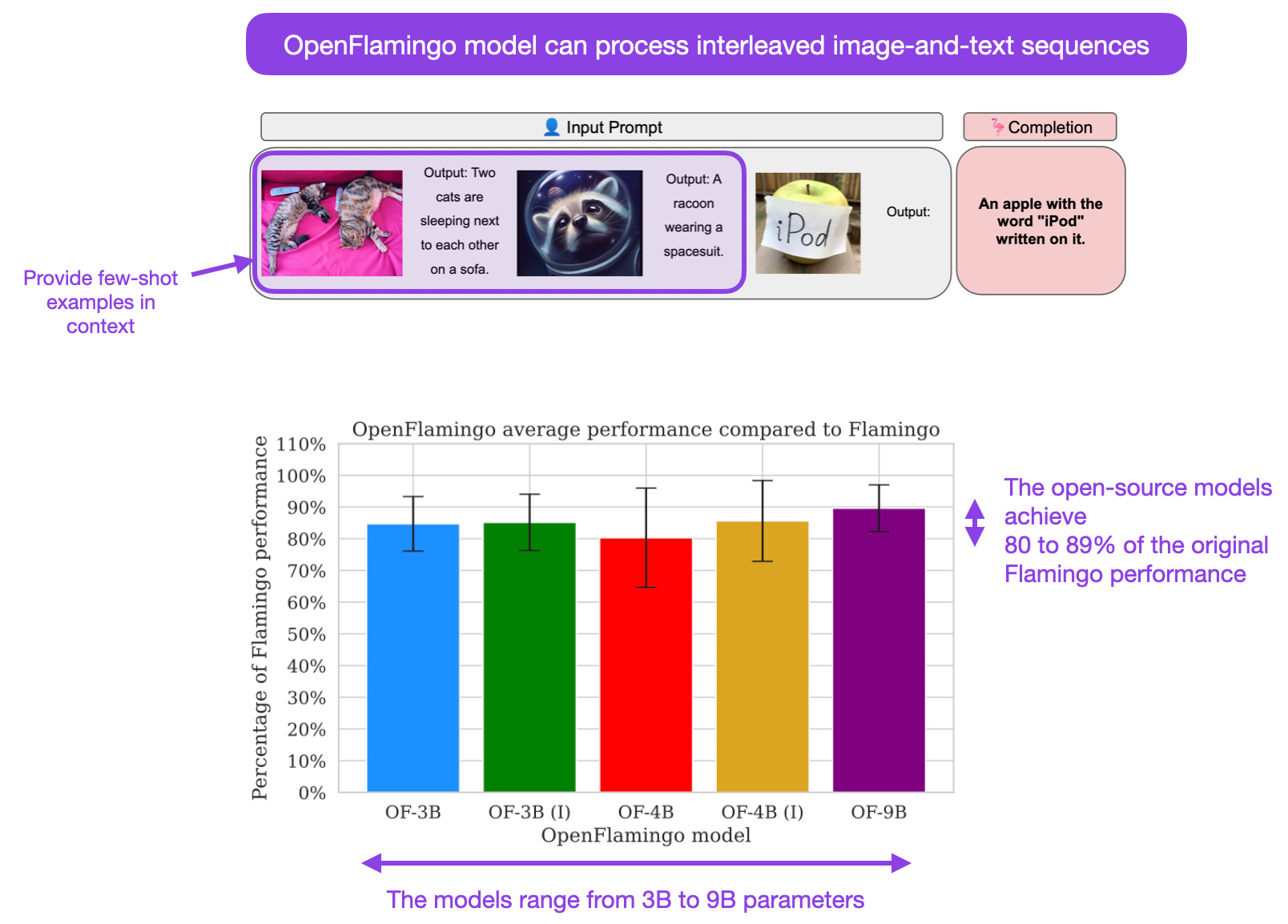
OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models (2 Aug, https://arxiv.org/abs/2308.01390)
OpenFlamingo is an open-source replication of DeepMind's Flamingo models, a suite of autoregressive vision-language models. This paper is a thorough technical report that describes the training pipeline to replicate the Flamingo models with 80 to 89% of the original Flamingo performance (on average).
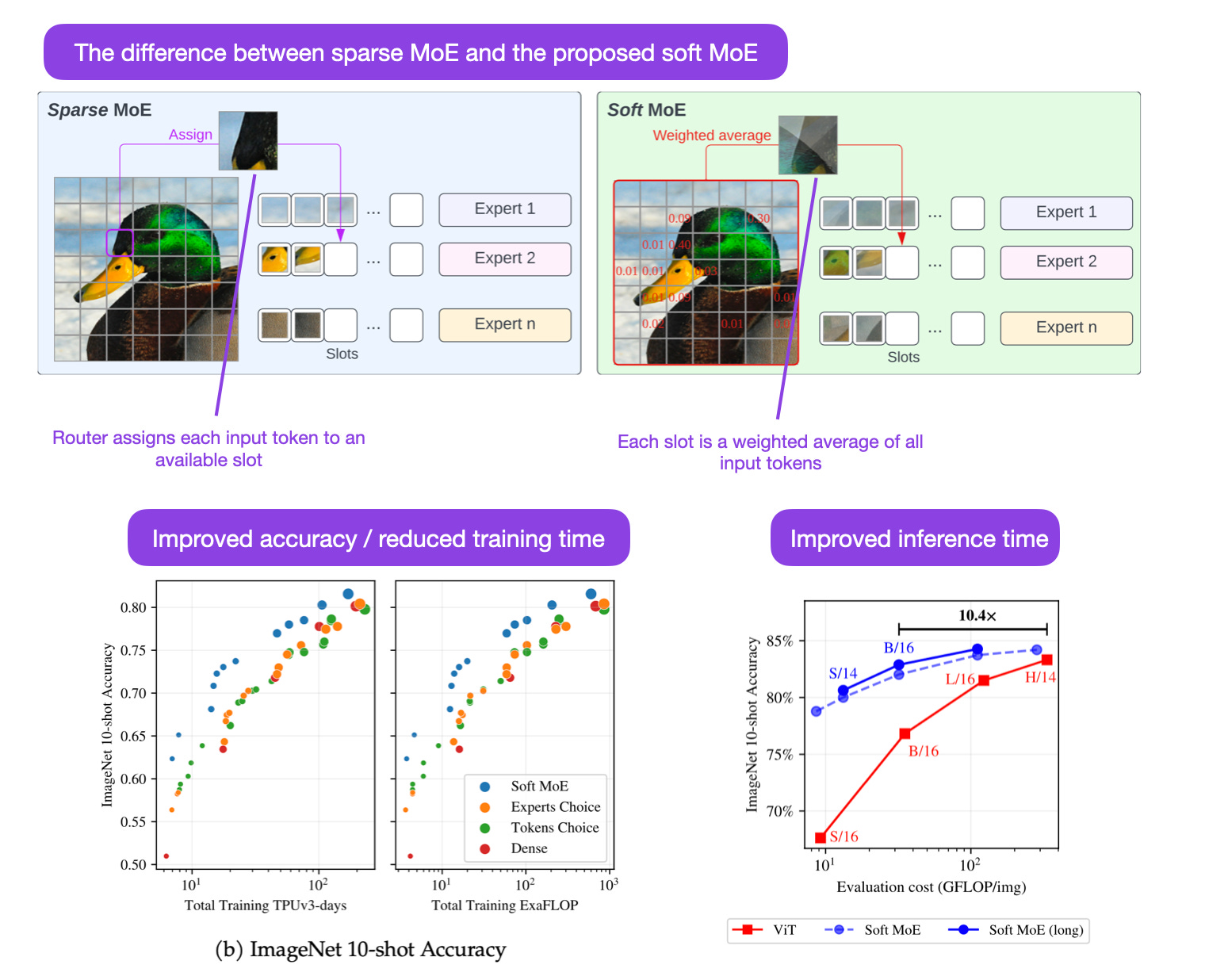
From Sparse to Soft Mixtures of Experts (2 Aug, https://arxiv.org/abs/2308.00951)
Sparse mixture of experts (MoEs) are models trained for different tasks on subsets of the data before they are combined via an input routing mechanism. Here, the researchers propose a fully-differentiable sparse vision transformer (ViT) that addresses challenges such as training instability, token dropping, and inefficient finetuning. The resulting model has 10x lower inference cost compared to a standard ViT while matching its modeling performance.
Meta-Transformer: A Unified Framework for Multimodal Learning (20 Jul, https://arxiv.org/abs/2307.10802)
Similar to ImageBind or Perceiver a few years ago, this transformer can use multiple modalities, such as images, text, audio, and many more. Here, each input modality is processed by a different, learnable data preprocessor. Then, after preprocessing the inputs into a shared token space, a shared encoder is used to produce the embeddings.

This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Thank you! It's getting very hard to keep up with the papers but we can rely on you to share the most important and interesting ones with us.
Sebastian, if you had to pick just one of these as being the most important, what would you pick? In the deluge of news, I really value the expertise and experience of folks like you.