

Understanding Large Language Models
A Cross-Section of the Most Relevant Literature To Get Up to Speed

Large language models have taken the public attention by storm – no pun intended. In just half a decade large language models – transformers – have almost completely changed the field of natural language processing. Moreover, they have also begun to revolutionize fields such as computer vision and computational biology.
Since transformers have such a big impact on everyone’s research agenda, I wanted to flesh out a short reading list (an extended version of my comment yesterday) for machine learning researchers and practitioners getting started.
The following list below is meant to be read mostly chronologically, and I am entirely focusing on academic research papers. Of course, there are many additional resources out there that are useful. For example,
the Illustrated Transformer by Jay Alammar;
a more technical blog article by Lilian Weng;
a catalog and family tree of all major transformers to date by Xavier Amatriain;
a minimal code implementation of a generative language model for educational purposes by Andrej Karpathy;
a lecture series and book chapter by yours truly.
Understanding the Main Architecture and Tasks
If you are new to transformers / large language models, it makes the most sense to start at the beginning.
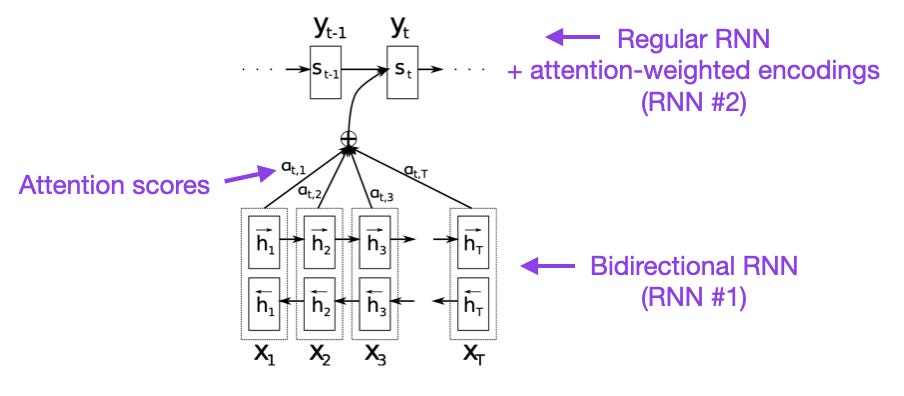
(1) Neural Machine Translation by Jointly Learning to Align and Translate (2014) by Bahdanau, Cho, and Bengio, https://arxiv.org/abs/1409.0473
I recommend beginning with the above paper if you have a few minutes to spare. It introduces an attention mechanism for recurrent neural networks (RNN) to improve long-range sequence modeling capabilities. This allows RNNs to translate longer sentences more accurately – the motivation behind developing the original transformer architecture later.
(2) Attention Is All You Need (2017) by Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin, https://arxiv.org/abs/1706.03762
The paper above introduces the original transformer architecture consisting of an encoder- and decoder part that will become relevant as separate modules later. Moreover, this paper introduces concepts such as the scaled dot product attention mechanism, multi-head attention blocks, and positional input encoding that remain the foundation of modern transformers.

(3) On Layer Normalization in the Transformer Architecture (2020) by Xiong, Yang, He, K Zheng, S Zheng, Xing, Zhang, Lan, Wang, and Liu, https://arxiv.org/abs/2002.04745
While the original transformer figure above (from Attention Is All You Need, https://arxiv.org/abs/1706.03762) is a helpful summary of the original encoder-decoder architecture, the location of the LayerNorm in this figure remains a hotly debated subject.
For instance, the Attention Is All You Need transformer figure places the layer normalization between the residual blocks, which doesn't match the official (updated) code implementation accompanying the original transformer paper. The variant shown in the Attention Is All You Need figure is known as Post-LN Transformer, and the updated code implementation defaults to the Pre-LN variant.
The Layer Normalization in the Transformer Architecture paper suggests that Pre-LN works better, addressing gradient problems, as shown below. Many architectures adopted this in practice, but it can result in representation collapse.
So, while there's still an ongoing discussion regarding using Post-LN or Pre-LN, there's also a new paper that proposes taking advantage of both worlds: ResiDual: Transformer with Dual Residual Connections (https://arxiv.org/abs/2304.14802); whether it will turn out useful in practice remains to be seen.

(4) Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks (1991) by Schmidhuber, https://www.semanticscholar.org/paper/Learning-to-Control-Fast-Weight-Memories%3A-An-to-Schmidhuber/bc22e87a26d020215afe91c751e5bdaddd8e4922
This paper is recommended for those interested in historical tidbits and early approaches fundamentally similar to modern transformers.
For instance, in 1991, which is about two-and-a-half decades before the original transformer paper above ("Attention Is All You Need"), Juergen Schmidhuber proposed an alternative to recurrent neural networks called Fast Weight Programmers (FWP). The FWP approach involves a feedforward neural network that slowly learns by gradient descent to program the changes of the fast weights of another neural network.
The analogy to modern transformers is explained in this blog post as follows:
In today's Transformer terminology, FROM and TO are called key and value, respectively. The INPUT to which the fast net is applied is called the query. Essentially, the query is processed by the fast weight matrix, which is a sum of outer products of keys and values (ignoring normalizations and projections). Since all operations of both networks are differentiable, we obtain end-to-end differentiable active control of fast weight changes through additive outer products or second order tensor products.[FWP0-3a] Hence the slow net can learn by gradient descent to rapidly modify the fast net during sequence processing. This is mathematically equivalent (apart from normalization) to what was later called Transformers with linearized self-attention (or linear Transformers).
As mentioned in the blog post excerpt above, this approach is now called "linear Transformers" or "Transformers with linearized self-attention" via the more recent papers Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention and Rethinking Attention with Performers that appeared on arXiv in 2020.
In 2021, the Linear Transformers Are Secretly Fast Weight Programmers paper then explicitly showed the equivalence between linearized self-attention and the fast weight programmers from the 1990s.

(5) Universal Language Model Fine-tuning for Text Classification (2018) by Howard and Ruder, https://arxiv.org/abs/1801.06146
This is another paper that's very interesting from a historical perspective. While it was written one year after the original Attention Is All You Need transformer was released, it doesn't involve transformers but instead focuses on recurrent neural networks. However, it's still noteworthy since it effectively proposed pretraining language models and transfer learning for downstream tasks.
While transfer learning was already established in computer vision, it wasn't yet prevalent in natural language processing (NLP). ULMFit was among the first papers to demonstrate that pretraining a language model and finetuning it on a specific task could yield state-of-the-art results in many NLP tasks.
The three-stage process for finetuning the language models suggested by ULMFit was as follows:
Train a language model on a large corpus of text.
Finetune this pretrained language model on task-specific data, allowing it to adapt to the specific style and vocabulary of the text.
Finetune a classifier on the task-specific data with gradual unfreezing of layers to avoid catastrophic forgetting.
This recipe -- training a language model on a large corpus and then finetuning it on a downstream task -- is the central approach used in transformer-based models and foundation models like BERT, GPT-2/3/4, RoBERTa, and others.
However, the gradual unfreezing, a key part of ULMFiT, is usually not routinely done in practice when working with transformer architectures, where all layers are typically finetuned at once.

(6) BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018) by Devlin, Chang, Lee, and Toutanova, https://arxiv.org/abs/1810.04805
Following the original transformer architecture, large language model research started to bifurcate in two directions: encoder-style transformers for predictive modeling tasks such as text classification and decoder-style transformers for generative modeling tasks such as translation, summarization, and other forms of text creation.
The BERT paper above introduces the original concept of masked-language modeling, and next-sentence prediction. It still is the most influential encoder-style architecture. If you are interested in this research branch, I recommend following up with RoBERTa, which simplified the pretraining objectives by removing the next-sentence prediction tasks.

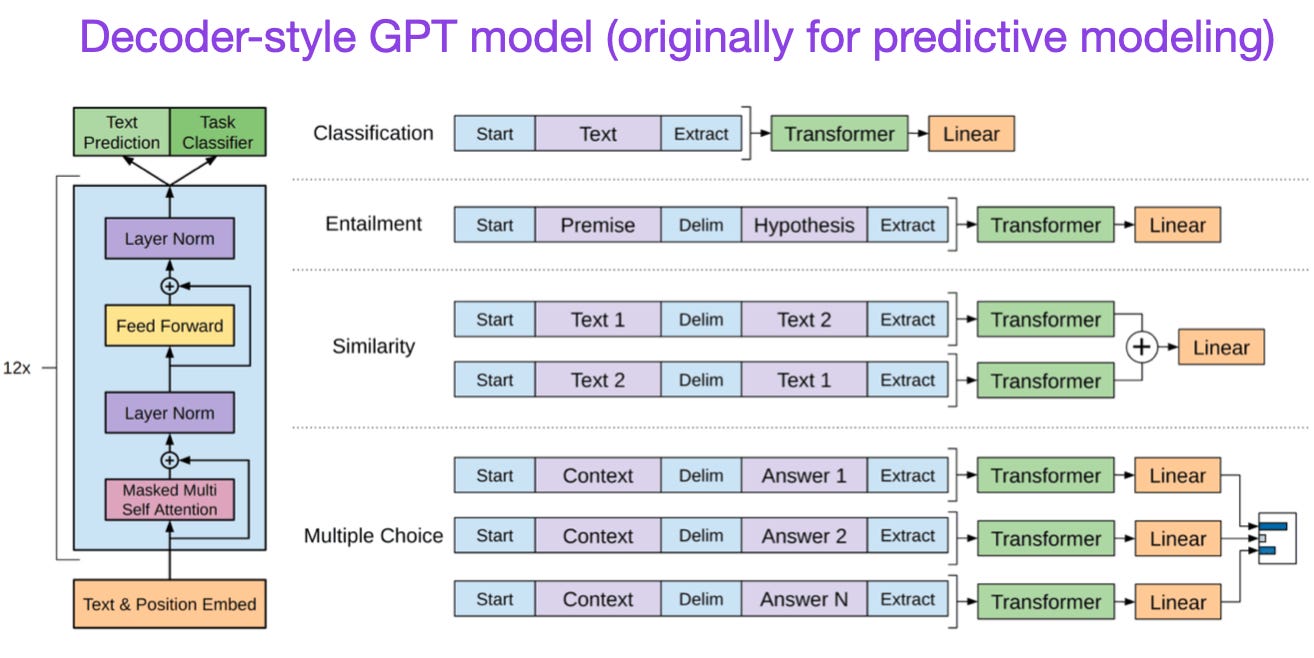
(7) Improving Language Understanding by Generative Pre-Training (2018) by Radford and Narasimhan, https://www.semanticscholar.org/paper/Improving-Language-Understanding-by-Generative-Radford-Narasimhan/cd18800a0fe0b668a1cc19f2ec95b5003d0a5035
The original GPT paper introduced the popular decoder-style architecture and pretraining via next-word prediction. Where BERT can be considered a bidirectional transformer due to its masked language model pretraining objective, GPT is a unidirectional, autoregressive model. While GPT embeddings can also be used for classification, the GPT approach is at the core of today’s most influential LLMs, such as chatGPT.
If you are interested in this research branch, I recommend following up with the GPT-2 and GPT-3papers. These two papers illustrate that LLMs are capable of zero- and few-shot learning and highlight the emergent abilities of LLMs. GPT-3 is also still a popular baseline and base model for training current-generation LLMs such as ChatGPT – we will cover the InstructGPT approach that lead to ChatGPT later as a separate entry.
(8) BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (2019) by Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov, and Zettlemoyer, https://arxiv.org/abs/1910.13461.
As mentioned earlier, BERT-type encoder-style LLMs are usually preferred for predictive modeling tasks, whereas GPT-type decoder-style LLMs are better at generating texts. To get the best of both worlds, the BART paper above combines both the encoder and decoder parts (not unlike the original transformer – the second paper in this list).

(9) Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond (2023) by Yang, Jin, Tang, Han, Feng, Jiang, Yin, and Hu, https://arxiv.org/abs/2304.13712
This is not a research paper but probably the best general architecture survey to date illustrating how the different architectures evolved. However, next to discussing BERT-style masked language models (encoders) and GPT-style autoregressive language models (decoders), it also provides useful discussions and guidance regarding pretraining and finetuning data.

Scaling Laws and Improving Efficiency
If you want to learn more about the various techniques to improve the efficiency of transformers, I recommend the 2020 Efficient Transformers: A Survey paper followed by the 2023 A Survey on Efficient Training of Transformers paper.
In addition, below are papers that I found particularly interesting and worth reading.
(10) FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (2022), by Dao, Fu, Ermon, Rudra, and Ré, https://arxiv.org/abs/2205.14135.
While most transformer papers don’t bother about replacing the original scaled dot product mechanism for implementing self-attention, FlashAttention is one mechanism I have seen most often referenced lately.

(11) Cramming: Training a Language Model on a Single GPU in One Day (2022) by Geiping and Goldstein, https://arxiv.org/abs/2212.14034.
In this paper, the researchers trained a masked language model / encoder-style LLM (here: BERT) for 24h on a single GPU. For comparison, the original 2018 BERT paper trained it on 16 TPUs for four days. An interesting insight is that while smaller models have higher throughput, smaller models also learn less efficiently. Thus, larger models do not require more training time to reach a specific predictive performance threshold.

(12) LoRA: Low-Rank Adaptation of Large Language Models (2021) by Hu, Shen, Wallis, Allen-Zhu, Li, L Wang, S Wang, and Chen, https://arxiv.org/abs/2106.09685.
Modern large language models that are pretrained on large datasets show emergent abilities and perform well on various tasks, including language translation, summarization, coding, and Q&A. However, if we want to improve the ability of transformers on domain-specific data and specialized tasks, it’s worthwhile to finetune transformers.
Low-rank adaptation (LoRA) is one of the most influential approaches for finetuning large language models in a parameter-efficient manner. While other methods for parameter-efficient finetuning exist (see the survey below), LoRA is particularly worth highlighting as it is both an elegant and very general method that can be applied to other types of models as well.
While the weights of a pretrained model have full rank on the pretrained tasks, the LoRA authors point out that pretrained large language models have a low “intrinsic dimension” when they are adapted to a new task. So, the main idea behind LoRA is to decompose the weight changes, ΔW, into a lower-rank representation, which is more parameter efficient.

(13) Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning (2022) by Lialin, Deshpande, and Rumshisky, https://arxiv.org/abs/2303.15647.
Modern large language models that are pretrained on large datasets show emergent abilities and perform well on various tasks, including language translation, summarization, coding, and Q&A. However, if we want to improve the ability of transformers on domain-specific data and specialized tasks, it’s worthwhile to finetune transformers. This survey reviews more than 40 papers on parameter-efficient finetuning methods (including popular techniques such as prefix tuning, adapters, and low-rank adaptation) to make finetuning (very) computationally efficient.

(14) Scaling Language Models: Methods, Analysis & Insights from Training Gopher (2022) by Rae and colleagues (78 co-authors!), https://arxiv.org/abs/2112.11446
Gopher is a particularly nice paper including tons of analysis to understand LLM training. Here, the researchers trained a 280 billion parameter model with 80 layers on 300 billions tokens. This includes interesting architecture modifications such as using RMSNorm (Root Mean Square Normalization) instead of LayerNorm (Layer Normalization). Both LayerNorm and RMSNorm are preferred over BatchNorm since they don't depend on the batch size and doesn't require synchronization, which is an advantage in distributed settings with smaller batch sizes. However, RMSNorm is generally said to stabilize the training in deeper architectures.
Besides interesting tidbits such the ones above, the main focus of this paper is the analysis of task performance for different scales. The evaluation on 152 diverse tasks reveal that increasing model sizes benefits tasks like comprehension, fact-checking, and the identification of toxic language the most. However, tasks related to logical and mathematical reasoning benefit less from architecture scaling.

(15) Training Compute-Optimal Large Language Models (2022) by Hoffmann, Borgeaud, Mensch, Buchatskaya, Cai, Rutherford, de Las Casas, Hendricks, Welbl, Clark, Hennigan, Noland, Millican, van den Driessche, Damoc, Guy, Osindero, Simonyan, Elsen, Rae, Vinyals, and Sifre, https://arxiv.org/abs/2203.15556.
This paper introduces the 70-billion parameter Chinchilla model that outperforms the popular 175-billion parameter GPT-3 model on generative modeling tasks. However, its main punchline is that contemporary large language models are “significantly undertrained.”
The paper defines the linear scaling law for large language model training. For example, while Chinchilla is only half the size of GPT-3, it outperformed GPT-3 because it was trained on 1.4 trillion (instead of just 300 billion) tokens. In other words, the number of training tokens is as vital as the model size.

(16) Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling (2023) by Biderman, Schoelkopf, Anthony, Bradley, O'Brien, Hallahan, Khan, Purohit, Prashanth, Raff, Skowron, Sutawika, and van der Wal, https://arxiv.org/abs/2304.01373
Pythia is a suite of open-source LLMs (70M to 12B parameters) to study how LLMs evolve over the course of training.
The architecture is similar to GPT-3 but includes some improvements, for example, Flash Attention (like LLaMA) and Rotary Positional Embeddings (like PaLM). Pythia was trained on The Pile dataset (825 Gb) for 300 B tokens (~1 epoch on regular PILE, ~1.5 epochs on deduplicated PILE.

The main insights of the Pythia study are as follows:
Training on duplicated data (due to how LLMs are trained, this means training for more than one epoch) does not benefit or hurt performance.
Training order does not influence memorization. This is unfortunate because if the opposite were true, we could mitigate undesirable verbatim memorization issues by reordering the training data.
Pretrained term frequency influences task performance. For instance, few-shot accuracy tends to be higher for more frequent terms.
Doubling the batch size halves the training time but doesn't hurt convergence.
Alignment – Steering Large Language Models to Intended Goals and Interests
In recent years, we have seen many relatively capable large language models that can generate realistic texts (for example, GPT-3 and Chinchilla, among others). It seems that we have reached a ceiling in terms of what we can achieve with the commonly used pretraining paradigms.
To make language models more helpful and reduce misinformation and harmful language, researchers designed additional training paradigms to fine-tune the pretrained base models.
(17) Training Language Models to Follow Instructions with Human Feedback (2022) by Ouyang, Wu, Jiang, Almeida, Wainwright, Mishkin, Zhang, Agarwal, Slama, Ray, Schulman, Hilton, Kelton, Miller, Simens, Askell, Welinder, Christiano, Leike, and Lowe, https://arxiv.org/abs/2203.02155.
In this so-called InstructGPT paper, the researchers use a reinforcement learning mechanism with humans in the loop (RLHF). They start with a pretrained GPT-3 base model and fine-tune it further using supervised learning on prompt-response pairs generated by humans (Step 1). Next, they ask humans to rank model outputs to train a reward model (step 2). Finally, they use the reward model to update the pretrained and fine-tuned GPT-3 model using reinforcement learning via proximal policy optimization (step 3).
As a sidenote, this paper is also known as the paper describing the idea behind ChatGPT – according to the recent rumors, ChatGPT is a scaled-up version of InstructGPT that has been fine-tuned on a larger dataset.

(18) Constitutional AI: Harmlessness from AI Feedback (2022) by Yuntao, Saurav, Sandipan, Amanda, Jackson, Jones, Chen, Anna, Mirhoseini, McKinnon, Chen, Olsson, Olah, Hernandez, Drain, Ganguli, Li, Tran-Johnson, Perez, Kerr, Mueller, Ladish, Landau, Ndousse, Lukosuite, Lovitt, Sellitto, Elhage, Schiefer, Mercado, DasSarma, Lasenby, Larson, Ringer, Johnston, Kravec, El Showk, Fort, Lanham, Telleen-Lawton, Conerly, Henighan, Hume, Bowman, Hatfield-Dodds, Mann, Amodei, Joseph, McCandlish, Brown, Kaplan, https://arxiv.org/abs/2212.08073.
In this paper, the researchers are taking the alignment idea one step further, proposing a training mechanism for creating a “harmless” AI system. Instead of direct human supervision, the researchers propose a self-training mechanism that is based on a list of rules (which are provided by a human). Similar to the InstructGPT paper mentioned above, the proposed method uses a reinforcement learning approach.

(19) Self-Instruct: Aligning Language Model with Self Generated Instruction (2022) by Wang, Kordi, Mishra, Liu, Smith, Khashabi, and Hajishirzi, https://arxiv.org/abs/2212.10560
Instruction finetuning is how we get from GPT-3-like pretrained base models to more capable LLMs like ChatGPT. And open-source human-generated instruction datasets like databricks-dolly-15k can help make this possible. But how do we scale this? One way is bootstrapping an LLM off its own generations.
Self-Instruct is one (almost annotation-free) way to align pretrained LLMs with instructions.
How does this work? In a nutshell, it's a 4-step process:
Seed task pool with a set of human-written instructions (175 in this case) and sample instructions.
Use a pretrained LLM (like GPT-3) to determine the task category.
Given the new instruction, let a pretrained LLM generate the response.
Collect, prune, and filter the responses before adding them to the task pool.

In practice, this works relatively well based on the ROUGE scores.
For example, a Self-Instruct-finetuned LLM outperforms the GPT-3 base LLM (1) and can compete with an LLM pretrained on a large human-written instruction set (2). And self-instruct can also benefit LLMs that were already finetuned on human instructions (3).
But of course, the gold standard for evaluating LLMs is to ask human raters. Based on human evaluation, Self-Instruct outperforms base LLM, and LLMs trained on human instruction datasets in supervised fashion (SuperNI, T0 Trainer). But interestingly, Self-Instruct does not outperform methods trained via reinforcement learning with human feedback (RLHF)
Which is more promising, human-generated instruction datasets or self-instruct-datasets? I vote for both. Why not start with a human-generated instruction dataset like the 15k instructions from databricks-dolly-15k and then scale this with self-instruct?
Reinforcement Learning with Human Feedback (RLHF)
For additional explanations of Reinforcement Learning with Human Feedback (RLHF), plus papers on proximal policy optimization for implementing RLHF, please see my more detailed article below:
LLM Training: RLHF and Its Alternatives

I frequently reference a process called Reinforcement Learning with Human Feedback (RLHF) when discussing LLMs, whether in the research news or tutorials. RLHF is an integral part of the modern LLM training pipeline due to its ability to incorporate human preferences into the optimization landscape, which can improve the model's helpfulness and safety.
Conclusion and Further Reading
I tried to keep the list above nice and concise, focusing on the top-10 papers (plus 3 bonus papers on RLHF) to understand the design, constraints, and evolution behind contemporary large language models.
For further reading, I suggest following the references in the papers mentioned above. Or, to give you some additional pointers, here are some additional resources (these lists are not comprehensive):
Open-source alternatives to GPT
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model (2022), https://arxiv.org/abs/2211.05100
OPT: Open Pre-trained Transformer Language Models (2022), https://arxiv.org/abs/2205.01068
UL2: Unifying Language Learning Paradigms (2022), https://arxiv.org/abs/2205.05131
ChatGPT alternatives
LaMDA: Language Models for Dialog Applications (2022), https://arxiv.org/abs/2201.08239
(Bloomz) Crosslingual Generalization through Multitask Finetuning (2022), https://arxiv.org/abs/2211.01786
(Sparrow) Improving Alignment of Dialogue Agents via Targeted Human Judgements (2022), https://arxiv.org/abs/2209.14375
BlenderBot 3: A Deployed Conversational Agent that Continually Learns to Responsibly Engage, https://arxiv.org/abs/2208.03188
Large language models in computational biology
ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Deep Learning and High Performance Computing (2021), https://arxiv.org/abs/2007.06225
Highly Accurate Protein Structure Prediction with AlphaFold (2021), https://www.nature.com/articles/s41586-021-03819-2
Large Language Models Generate Functional Protein Sequences Across Diverse Families (2023), https://www.nature.com/articles/s41587-022-01618-2
This magazine is a personal passion project. For those who wish to support me, please consider purchasing a copy of my Build a Large Language Model (From Scratch) book. (I am confident that you'll get lots out of this book as it explains how LLMs work in a level of detail that is not found anywhere else.)

If you read the book and have a few minutes to spare, I'd really appreciate a brief review. It helps us authors a lot!
Alternatively, I also recently enabled the paid subscription option on Substack to support this magazine directly.
This is fantastic. Really looking forward to going through each of these papers. The rate of progress is so fast that collections like these are essential so that people who are not at the core of the field can keep up with the key insights.
I'd love to read additional ML & AI articles from you, outside of your existing newsletter format! So you've got my vote ✅