

State of Computer Vision 2023: From Vision Transformers to Neural Radiance Fields

Large language model development (LLM) development is still happening at a rapid pace. At the same time, leaving AI regulation debates aside, LLM news seem to be arriving at a just slightly slower rate than usual.
This is a good opportunity to give the spotlight to computer vision once in a while, discussing the current state of research and development in this field. And this theme also goes nicely with a recap of CVPR 2023 in Vancouver, which was a wonderful conference at probably the nicest conference venue I have attended so far.

PS: If the newsletter appears truncated or clipped, that's because some email providers may truncate longer email messages. In this case, you can access the full article at https://magazine.sebastianraschka.com.
Articles & Trends
This year, CVPR 2023 has accepted an impressive total of 2359 papers, resulting in a vast array of posters for participants to explore. As I navigated through the sea of posters and engaged in conversations with attendees and researchers, I found that most research focused on one of the following 4 themes:
Vision Transformers
Generative AI for Vision: Diffusion Models and GANs
NeRF: Neural Radiance Fields
Object Detection and Segmentation
Below, I will be giving a brief introduction to these four subfields. Subsequently, I will also highlight an intriguing paper selected from the conference proceedings, which relates to each field.
(Interested readers can find the full list of accepted papers here.)
1) Vision Transformers
Following in the footsteps of successful language transformers and large language models, vision transformers (ViTs) initially appeared in 2020 via An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.
The main concept behind ViTs is similar to that of language transformers: It uses the same self-attention mechanism in its multihead attention blocks. However, instead of tokenizing words, ViTs are tokenizing images.
As discussed in a previous Ahead of AI article, Understanding Encoder And Decoder LLMs, the original transformer for language modeling (via Attention Is All You Need) was an encoder-decoder architecture. And modern language transformers can be grouped into encoder-only architectures like BERT (often used for classification) and decoder-only architectures like GPT (mostly used for text generation).
The original ViT model resembles encoder-like architectures similar to BERT, encoding embedding image patches. We can then attach a classification head for an image classification task.

Note that ViTs typically have much more parameters than convolutional neural networks (CNNs), and as a rule of thumb, they require more training data to achieve good modeling performance. This is why we usually adopt pretrained ViTs instead of training them from scratch. (Unlike language transformers, ViTs are typically pretrained in supervised, rather than unsupervised or self-supervised, fashion.)
For example, as I recently showed in my CVPR talk on Accelerating PyTorch Model Training Using Mixed-Precision and Fully Sharded Data Parallelism, we can achieve much better classification performance if we start with pretrained transformers rather than training them on the target dataset from scratch.
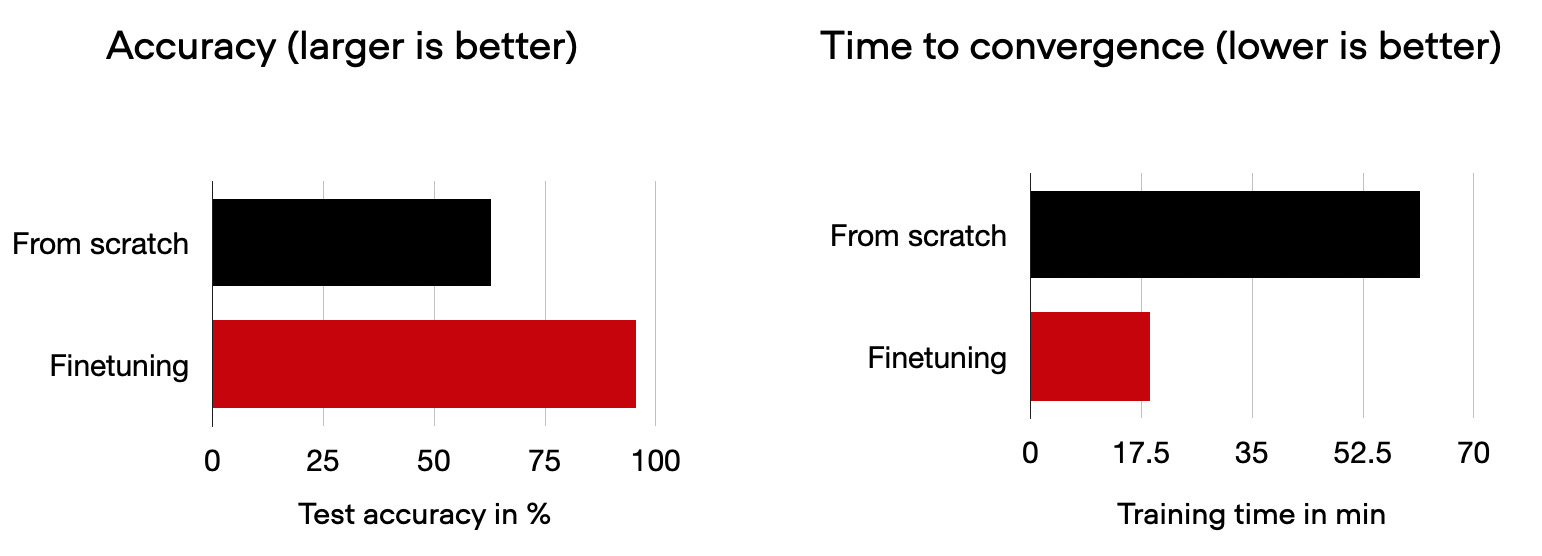
ViTs like DeiT and Swin are extremely popular architectures due to their state-of-the-art performance on computer vision tasks.
Still, one major criticism of ViTs is that they are relatively resource-intensive and less efficient than CNNs. This may be among the major contributing factors why ViTs have not seen widespread adoption in practical applications despite being among the hottest research topics in computer vision.
Efficient ViT: Memory Efficient Vision Transformer with Cascaded Group Attention
As mentioned above, ViTs are relatively resource-intensive, which holds them back from more widespread adoption in practice. In the CVPR paper Efficient ViT: Memory Efficient Vision Transformer with Cascaded Group Attention, researchers introduce a new, efficient architecture to address this limitation, making ViTs more suitable for real-time applications.

The main innovations in this paper include using
a single memory-bound multihead self-attention (MHSA) block between fully connected layers (FC layers);
cascaded group attention.
Let's start with point 1: the MHSA sandwiched between FC layers. According to other studies, memory inefficiencies are mainly caused by MHSA rather than FC layers (Ivanov et al. 2020 and Kao et al. 2021). To address this, the researchers use additional FC layers to allow more communication between feature channels. But they reduce the number of attention layers 1 in contrast to, e.g., the popular Swin Transformer. In addition, they also shrink the channel dimensions for the Q (query) and K (key) matrices in MHSA.

The cascaded group attention here is inspired by group convolutions, which were used in AlexNet, for example.
Group convolutions, also known as channel-wise or depthwise convolutions, are a variation of the standard convolution operation. In contrast to regular convolutions, group convolution divides the input channels into several groups. Each group performs its convolution operations independently. For instance, if an input has 64 channels, and the grouping parameter is set to 2, the input would be split into two groups of 32 channels each, and these groups would then be convolved independently. This approach not only reduces computational cost but can also increase model diversity by enforcing a kind of regularization, leading to potentially improved modeling performance in some tasks.

Impressively, EfficientViT does not only run up to 6x faster than a MobileViT, but it also runs 2.3 on an iPhone 11 at similar accuracy.
As a bottom line, due to their good predictive performance, ViTs are here to stay (at least as a popular research target). Now, with efficiency improvements, I think we will also see a more widespread adoption in production in the upcoming years.
2) Generative AI for Vision: Diffusion Models
Thanks to open-source models like Stable Diffusion, which reimplemented the model proposed in the High-Resolution Image Synthesis with Latent Diffusion Models paper, most are probably familiar with diffusion models by now. If not, here's a short rundown.
Diffusion models are fundamentally generative models. During training, random noise is added to the input data over a series of steps to perturb it. Then, in a reverse process, the model learns how to invert the noise and denoise the output to recover the original data. During inference, a diffusion model can then be used to generate new data from noise inputs.

(Of course, there are many more generative AI models besides diffusion models, as I discuss in Chapter 9 of Machine Learning Q and AI.)
Most diffusion models use CNNs and employ a U-Net based on a CNN. U-Net is known for its distinctive "U" shape, originally used for image segmentation tasks. It consists of an encoder part to capture context and a decoder that allows precise localization.
Diffusion models traditionally repurposed U-Net to model the conditional distribution at each diffusion step, providing the mapping from a noise distribution to the target data distribution. Or, in other words, a U-Net is be used to predict the noise to be added or subtracted at each step of the diffusion process. U-Nets are particularly attractive here because they can combine local and global information.
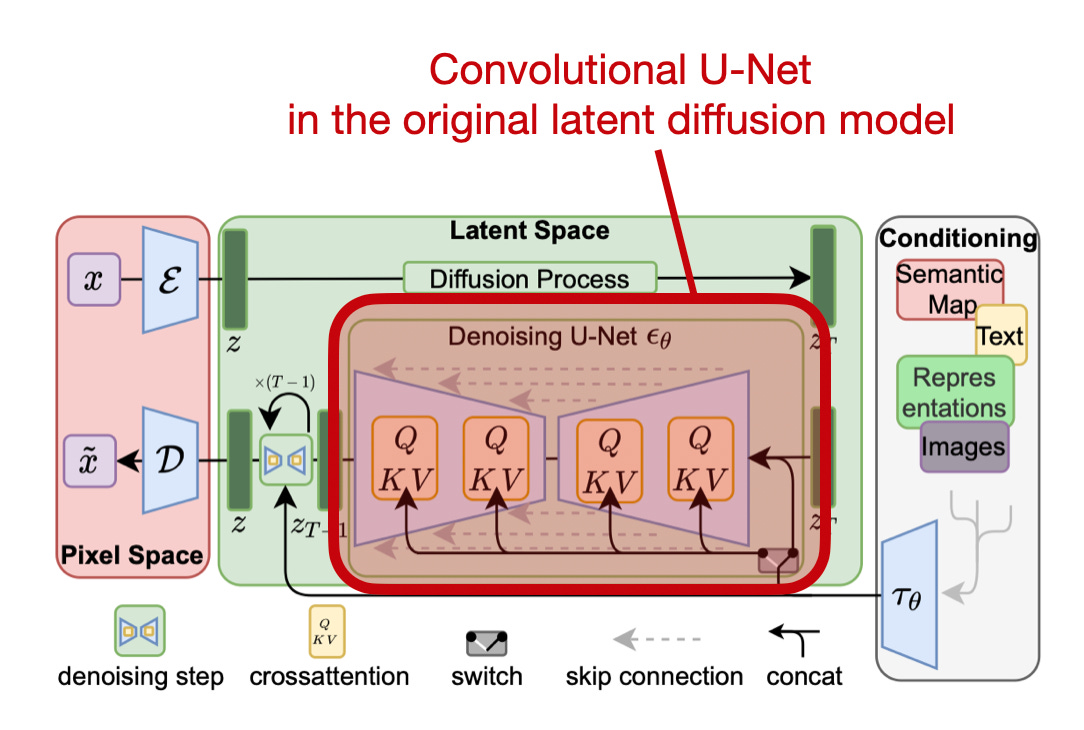
One interesting question is whether it's beneficial to swap the CNN backbone with a ViT, which is something researchers explored in the paper below.
All are Worth Words: A ViT Backbone for Diffusion Models
In this All are Worth Words: A ViT Backbone for Diffusion Models paper, researchers try to swap the convolutional U-Net backbone in a diffusion model with a ViT, which they refer to as U-ViT. Note that this is not the first attempt next to previous methods like GenViT and VQ-Diffusion, for example. However, the proposed U-ViT seems to be the best attempt so far.
The main contributions are additional "long" skip connections and an additional convolutional block before the output. Note that the "long" skip connections are in addition to the regular skip connections in the transformer blocks.
Similar to regular ViTs, explained in the previous section, the inputs are the "patchified" images, plus an additional time token (for the diffusion step) and condition token (for class-conditional generation).

The figure below shows an ablation study to justify these various design choices (nice!).
The researchers evaluated the new architecture on all three main tasks:
Unconditional image generation;
Class-conditional image generation;
Text-to-image generation.
On unconditional image generation, the new U-ViT diffusion model is competitive but worse than other diffusion models. On conditional image generation tasks, the new U-ViT diffusion model rivals the best GAN and outperforms other diffusion models. And on Text-to-image generation, it outperforms other models (GANs and diffusion models) trained on the same dataset.

It's refreshing to see that the paper was accepted even though the model did not outperform all other models on several tasks. It's a new model with new architectural ideas, and it will be interesting to see where ViTs take diffusion models in the upcoming years.
(As a very small caveat, the text-to-image training and evaluation datasets were relatively small compared to some other models. And it's unclear how the computational performance of this architecture compares to previous CNN-based diffusion models. However, I assume the main motivation behind smaller datasets is that it's an academic project (versus a major project at a big tech company) so it might be resource related. Even with using the smaller, more established benchmark MS-COCO dataset, there is nothing wrong.
3) Neural Radiance Fields (NeRF)
In short, Neural Radiance Fields (NeRF) is a relatively new method (initially proposed in 2020) for synthesizing novel views of complex 3D scenes from a set of 2D images: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. This is accomplished by modeling the scenes as volumetric fields of neural network-generated colors and densities. The NeRF model, trained on a small set of images taken from different viewpoints, learns to output the color and opacity of a point in 3D space given its 3D coordinates and viewing direction.

Since there's a lot of technical jargon in Neural Radiance Fields, let's take a brief step back and derive where these terms come from.
First, we need to define neural fields, a fancy term for describing a neural network that serves as a trainable (or parameterizable) function that generates a "field" of output values across the input space, for example, a 3D scene.
The idea is to get the network to overfit to a specific 3D scene, which can then be used to generate novel views of the scene with high accuracy. This is somewhat similar to the concept of spline interpolation in numerical analysis, where a curve is "overfit" to a set of data points to generate a smooth and precise representation of the underlying function.
The algorithm is summarized in the figure below, taken from the excellent Neural Fields in Visual Computing and Beyond paper by Xie et al.

In the case of NeRF, the network learns to output color and opacity values for a given point in space, conditioned on the viewing direction, which allows for creating a realistic 3D scene representation. Since NeRF predicts the color and intensity of light at every point along a specific viewing direction in 3D space, it essentially models a field of radiance values, hence the term Radiance Field. By the way, note that we technically refer to a NeRF representation as 5D because it considers three spatial dimensions (x, y, z coordinates in 3D space) and two additional dimensions representing the viewing direction defined by two angles, theta and phi.
NeRFs are interesting because they have many potential applications, basically everything related to high-quality 3D reconstructions. This includes 3D scanning, virtual and augmented reality, and 3D modeling and motion capturing in movies and video games.
ABLE-NeRF: Attention-Based Rendering with Learnable Embeddings for Neural Radiance Field
As described above, the basic idea behind NeRF is to model a 3D scene as a continuous volume of radiance values. Instead of storing explicit 3D objects or voxel grids, the 3D scene is stored as a function (a neural network) that maps 3D coordinates to colors (RGB values) and densities.
This network is trained using a set of 2D images of the scene taken from different viewpoints. And then, when rendering a scene, NeRF takes as input a 3D coordinate and a viewing direction (a camera ray or beam), and it outputs the RGB color value and the volume density at that location.
This way, NeRFs can generate novel views of objects with photo-realistic qualities. However, one of the shortcomings of NeRFs is that glossy objects often look blurry, and the colors of translucent objects are often murky.
In the paper ABLE-NeRF: Attention-Based Rendering with Learnable Embeddings for Neural Radiance Field, researchers address these shortcomings and improve the visual quality of translucent and glossy surfaces by introducing a self-attention-based framework and learnable embeddings.
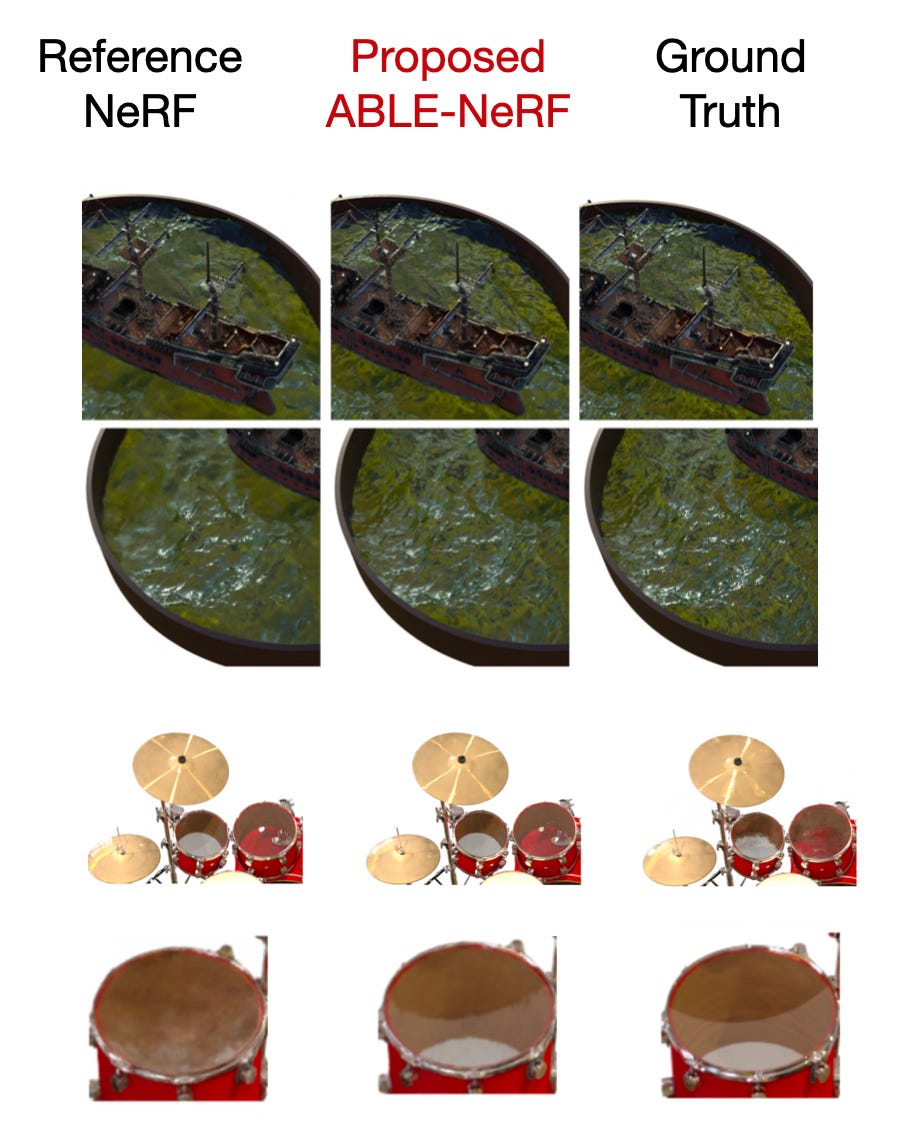
One additional detail worth mentioning about regular NeRFs is that they use a volumetric rendering equation derived from the physics of light transport. The basic idea in volumetric rendering is to integrate the contributions of all points along a ray of light as it travels through a 3D scene. The rendering process involves sampling points along each ray, querying the neural network for the radiance and density values at each point, and then integrating these to compute the final color of the pixel.
The proposed ABLE-NeRF diverges from such physics-based volumetric rendering and uses an attention-based network instead, which is responsible for determining a ray's color. Further, they added masked attention so that specific points can't attend occluded points to incorporate the physical restrictions of the real world. Lastly, they also add another transformer module for learnable embeddings to capture the view-dependent appearance caused by indirect illumination. (Ablations studies show that the learnable embeddings are important for enhancing visual quality.) The big picture of the proposed method is summarized in the annotated figure below.

Based on the renderings comparing ABLE-NeRF to a reference NeRF (shown above/earlier), the results look truly impressive. Of course, the results are not perfect, as one can see when comparing the renderings to the ground truth, but ABLE-NeRF is roughly 90% there. It's pretty impressive how far we have come regarding 3D scene reconstruction from images.
4) Object Detection and Segmentation
Object detection and segmentation are classic computer vision tasks, so it probably doesn't require a lengthy introduction. However, to briefly highlight the difference between these two tasks: object detection about predicting bounding boxes and the associated labels; segmentation classifies each pixel to distinguish between foreground and background objects.

Furthermore, we can distinguish between three segmentation categories, which I outlined below.
1. Semantic segmentation. This technique labels each pixel in an image with a class of objects (e.g., car, dog, or house). However, it doesn't distinguish between different instances of an object. For example, if there are three cars in an image, all of them would be labeled as "car" without distinguishing between car 1, car 2, and car 3.
2. Instance segmentation. This technique takes semantic segmentation a step further by differentiating between individual instances of an object. So, in the same scenario of an image with three cars, instance segmentation would separately identify each one (e.g., car 1, car 2, and car 3). So, this technique not only classifies each pixel but also identifies distinct object instances, giving it a distinct object ID.
3. Panoptic segmentation. This technique combines both semantic segmentation and instance segmentation. In panoptic segmentation, each pixel is assigned a semantic label as well as an instance ID. To differentiate panoptic segmentation a bit better from instance segmentation, the latter focuses on identifying each instance of each recognized object in the scene. I.e., instance segmentation is concerned primarily with "things" - identifiable objects like cars, people, or animals. On the other hand, panoptic segmentation aims to provide a comprehensive understanding of the scene by labeling every pixel with either a class label (for "stuff", uncountable regions like sky, grass, etc.) or an instance label (for "things", countable objects like cars, people, etc.).
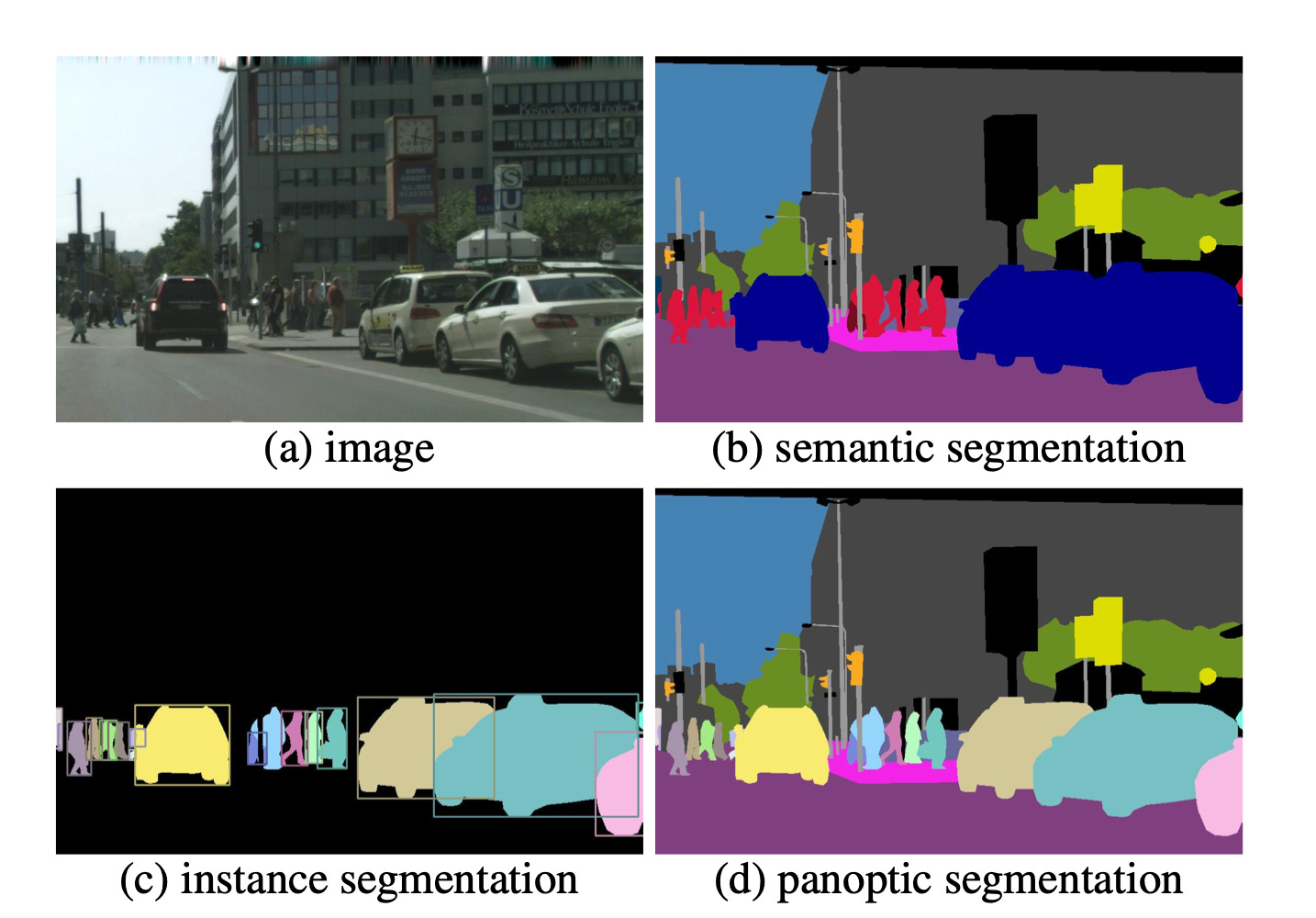
Some popular algorithms for object detection include R-CNN and its variants (Fast R-CNN, Faster R-CNN), YOLO (You Only Look Once), and SSD (Single Shot MultiBox Detector).
Models for segmentation include U-Net (discussed in the diffusion model section earlier), Mask R-CNN (a variant of Faster R-CNN with segmentation capabilities), and DeepLab, among others.
Both object detection and segmentation are important for applications like self-driving cars, medical imaging, and, of course, video surveillance. Note that object detection and segmentation are also often used together, where object detection can provide a coarse localization of objects, which segmentation algorithms can then be finetuned for more precise boundary and shape analysis.
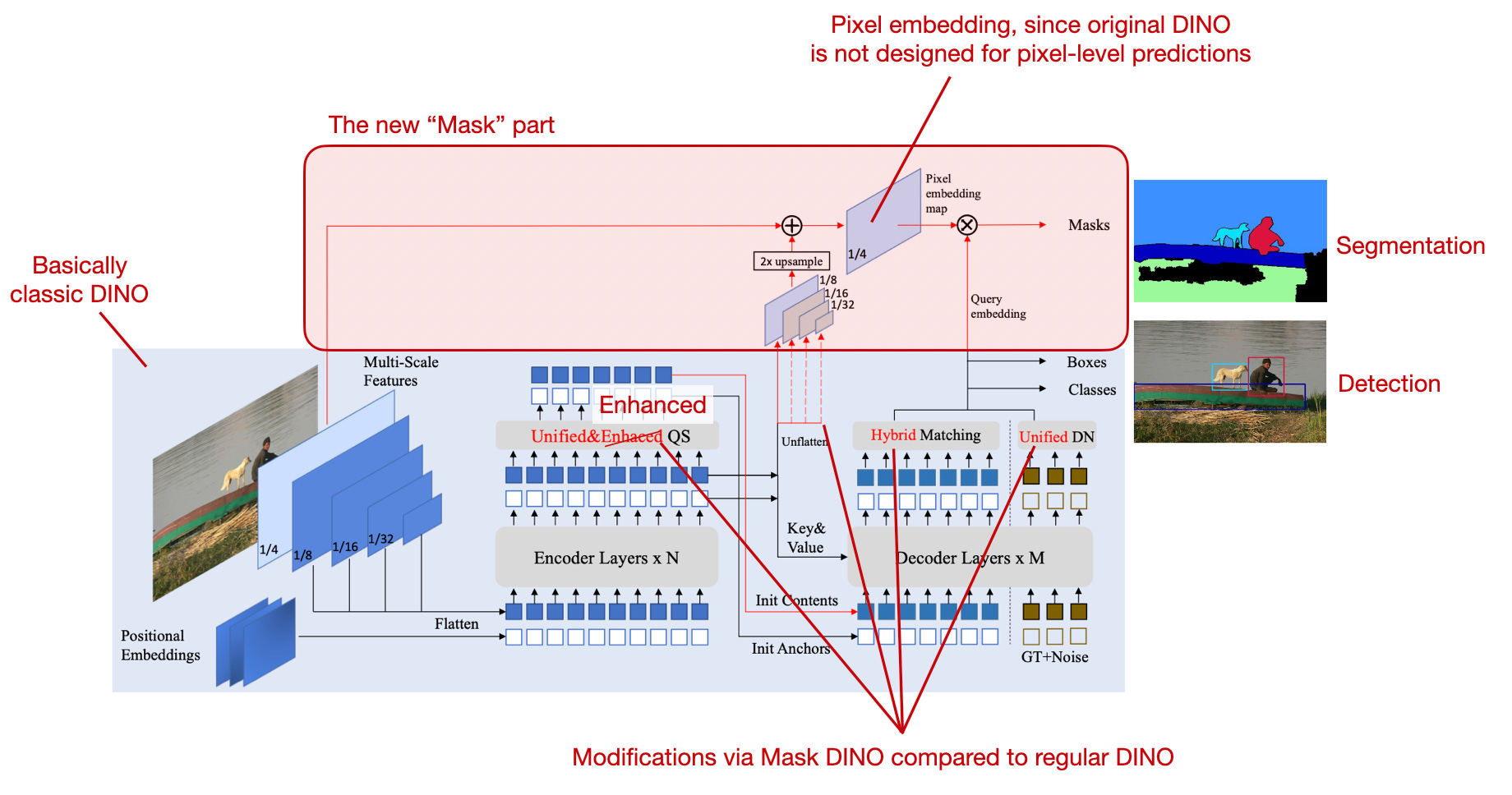
Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation
The Mask DINO: Towards A Unified Transformer-based Framework for Object Detection and Segmentation paper is an extension of the DINO method (DETR with Improved deNoising anchOr boxes).
And DETR (DEtection TRansformer) is an end-to-end object detection model introduced by Facebook AI in the paper End-to-End Object Detection with Transformers, which (surprise, surprise) uses a transformer architecture. Unlike traditional object detection models, DETR treats object detection as a direct set prediction problem, eliminating the need for handcrafted anchor boxes and non-maximum suppression procedures and providing a simpler and more flexible approach to object detection.
While CNN-based methods nowadays unify object detection (a region-specific task) and segmentation (a pixel-level task) to improve the overall performance on both tasks (basically a form of multitask learning), this is not the case for transformer-based object detection and segmentation systems.
However, this is what the proposed Mask DINO system aims to address. By extending DINO, Mask DINO outperforms all existing object detection and segmentation systems. The idea behind Mask DINO is summarized in the annotated figure below.
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Nicely written, learned a lot. Thanks for sharing
Looking forward to the next "Research Highlights in Three Sentences or Less."
As I have little interest in computer vision, I didn't get anything out of this issue. Frankly, I have only a passing interest in generative art -- broadly defined -- as well. Multimodal is great, but multimodal doesn't necessarily have anything to do with generative art, CV, ...