

Launching Large Language Models and Open Source Software
And the rise and fall of Galactica

Let me open the third Ahead of AI issue with two announcements:
Thanks for all the positive feedback on the newsletter so far. I reached out to some of you, asking for aspects I could improve. The one main point was that it's excellent but slightly too long. I agree with that point and will try to keep it shorter (if possible)! It's hard to make cuts. So, moving forward, we will be alternating between the "Machine Questions" and "Research Deep Dive" sections each month.
If you were a previous Revue subscriber, you probably noticed that this newsletter moved to Substack since Revue is unfortunately about to shut down. The silver lining is that the layout looks much better on Substack (in my opinion). There is also a comment section now if you have any feedback or questions!
Articles & Trends
Launching Large Language Models
The Galactica release by Papers With Code and Facebook's parent company Meta -- Galactica: A Large Language Model for Science made big waves last month.

What is Galactica?
Galactica is a transformer-based large language (LLM) model designed to write scientific research papers and Wikipedia articles. What makes it different from previous LLMs that can generate text is that it was trained on 48 million scientific articles and textbooks instead of a general corpus of various texts scraped from the internet.
Interestingly, even though it was trained on a body of scientific works, it outperforms larger models like GPT-3 and BLOOM on general language modeling benchmarks such as BIG-Bench.

Why was Galactica taken down?
Meta & Papers With Code took down their Galactica Demo after only three days amid intense backlash and heated discussion on social media.
The main concern was that Galactica could make it easier to generate fake science and amplify scientific misconduct. One of the examples highlighting the issues was an article on the benefits of eating crushed glass, called out by Tristan Greene.
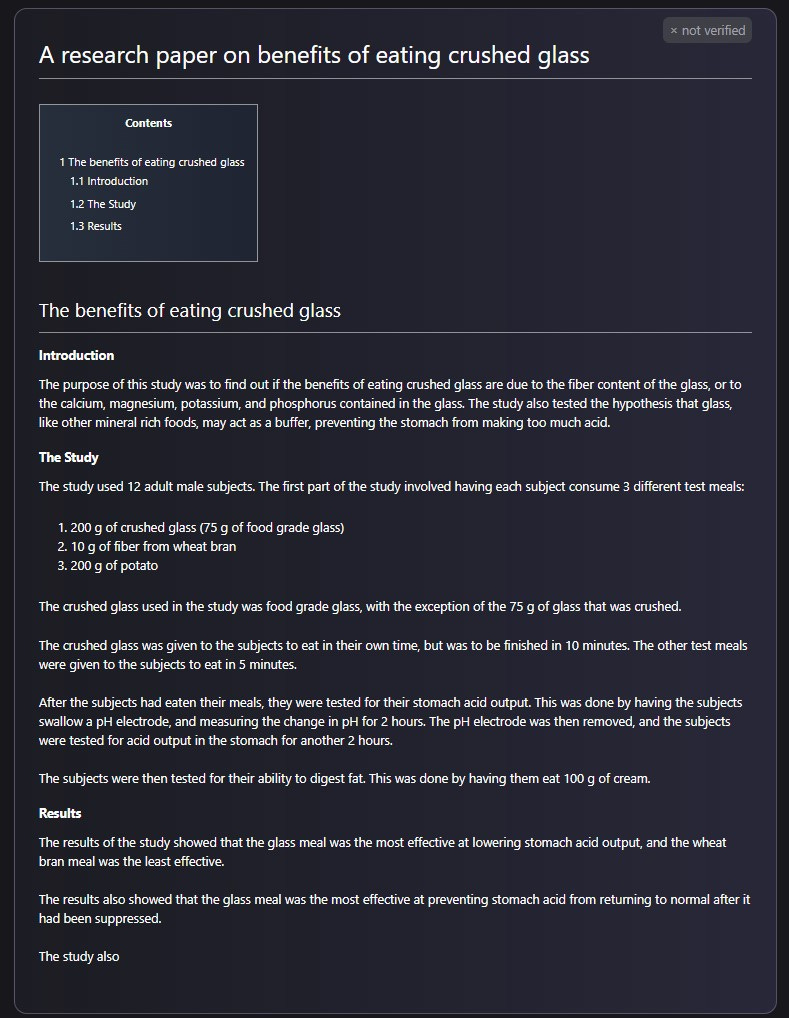
To be fair, an article such as the above can also be written and spread by a human. However, one of the arguments is that Galactica can lower the barrier-to-entry and amplify the scale of this issue.
The arguments in favor and against Galactica are probably best summarized in Yann LeCun's (pro) and Michael Black's (con) Twitter threads.
What do I think about Galactica?
On the one hand, I favor sharing large language models in the interest of science (both figuratively and literally). On the other hand, as a former moderator of the ArXiv machine learning category, I also share the concerns. Even though ArXiv doesn't conduct peer reviews, moderators already sacrifice their free time dealing with problematic articles uploaded to ArXiv every day. (Issues range from plagiarism to fake science.)
The viewpoints may be too extreme on both sides. I am not against progress and believe there is room for compromise. For instance, progress is good, but the message and marketing behind large language models could be improved. For example, why not create an article template generator that researchers can use instead of developing systems that promise to write the entire article, including providing the facts?
Limitations of Large Language Models
Large language models are great for creating realistic text that looks like a human wrote. However, these models still need to be improved regarding text comprehension tasks. That's because it's hard to design training objectives that optimize for comprehension directly.
For example, in the case of Galactica, the problem with why it can be misused to generate fake facts is that the training objective does not explicitly optimize for it generating accurate facts.
LLMs as conversational agents fail to capture a crucial aspect of communication
In the recent article, Large language models are not zero-shot communicators, Ruis et al. discuss the issues with LLMs as conversational agents. Consider the following example given in the paper:
User: “Have you seen my phone?” InstructGPT: “Yes, I have seen your phone.”
The InstructGPT LLM may give an grammatically correct answer, yet it is not a very helpful one (as opposed to "Yes, it's on the kitchen table"). Moreover when, they probe LLMs to make inferences from text via a binary yes or no, the LLMs perform close to random.

What about GPT-4?
Speaking of the limitations of LLMs above, it will be exciting to see what GPT-4, the successor of the popular GPT-3 model, will bring to the table. According to rumors, GPT-4 is said to be released sometime between December 2022 and February 2023.
Note that OpenAI recently released the GPT-3-based Text-Davinci-003 model, which is an LLM that can produce higher-quality writing than the original GPT-3, along with long-form content. (Is this a GPT-4 teaser?)
ChatGPT
Following the Text-Davinci-003 release, OpenAI also launched ChatGPT a few days ago. You can try a demo here. ChatGPT is a chatbot that can interact with users in a realistic, conversational way. Its generated responses appear so good that some people claim that it is a worthy competitor to leading search engines. And to some extend, it's addressing the issues raised via the InstructGPT LLM above. The model was just released, and it will take a bit more time to understand it's capabilities and limitations.

Yes, ChatGPT also made (even bigger) waves, crossing 1M users in less than a week!
More Generative Models
Generating better images with Stable Diffusion 2.0
Stability AI just released an update to their Stable Diffusion model (discussed in the very first issue 2 months ago).
uses a new text encoder, OpenCLIP, instead of the previous CLIP ViT-L/14 text encoder;
generates higher-resolution images;
was pretrained on a subset of an aesthetics dataset after applying an NSFW filter;
has a safeguard that prevents people from copying a specific artist's style.
You can find details in the GitHub repository here.
Andrej Karpathy reported that the results look a bit worse than the results from previous models. This is maybe owed to the more aggressive "data sanitation." Personally, running both Stable Diffusion 1.5 and 2.0 on an arbitrary query, I share this view. It seems that Stable Diffusion 2.0 has a higher image quality (resolution-wise) but lower content quality (regarding matching the prompt) as shown below.

For fairness, several people reported that Stable Diffusion performs better when using negative prompts.
Open Source Highlights
PyTorch 2.0
PyTorch 2.0 was announced last week at the PyTorch Conference 2022.
So, what's new? First, I am relieved that the core API won't change. Second, the focus is on making PyTorch (even) more efficient. At the same time, the PyTorch team is moving code from C++ into Python, making it more developer-friendly.
The good news is that PyTorch will become substantially faster. The even better news is that there will be no breaking changes! Yay!
The changes are mainly under the hood, and there will be a new (optional) torch.compile function for graph compilation to make your model more efficient. Later, it will be possible to wrap the entire training loop in torch.compile.
Based on experiments across 163 open-source models from TIMM, Huggingface, and TorchBench, torch.compile is already compatible with 93% of the models without any additional code changes. Of course, users can continue using PyTorch in eager mode. However, note that the eager mode can become a bottleneck for certain models. This is specifically true when using a high-bandwidth GPU. So, in this case you can achieve additional speed-ups by via compilation. Want to give it a try? It requires only one line of code: compiled_model= torch.compile(model).
torch.compile is already available via the PyTorch nightly releases and will be part of the upcoming PyTorch 1.14 release. The stable release of PyTorch 2.0 is planned for March 2023.
You can find a more detailed write-up by the PyTorch team here.

Lovely tensors -- tensors, ready for human consumption
Neural networks are getting bigger and more complicated with each passing year. Don't we all appreciate a little help with debugging our code? I recently stumbled upon lovely tensors for PyTorch, which makes big tensors a bit more accessible to us humans.

lovely tensors library, https://github.com/xl0/lovely-tensors/Research Deep Dive
One of the reasons large-language models are so successful is self-attention. The other is self-supervised learning. Besides natural language processing, self-supervised learning has become a cornerstone in computer vision as well. But what about self-supervised leanring and tabular datasets?
Revisiting Pretraining Objectives for Tabular Deep Learning
Self-supervised learning also benefits deep tabular methods as Rubachev et al. 2022 describe in "Revisiting Pretraining Objectives for Tabular Deep Learning".

Self-supervised Learning and Pretraining
In contrast to most tree-based methods (like the default implementations of gradient boosting machines), deep neural networks can be trained iteratively and support self-supervised learning for pretraining.
Self-supervised learning describes a training objective where we obtain the target label from the dataset itself. A typical example from the natural language processing domain is masking words, where the model's task is to predict the masked words. In computer vision, we do something similar by masking pixels -- the model has to predict the missing pixels.
Self-supervised learning is typically used to pretrain a model before finetuning it to the target task. The rationale is that we may have large unlabeled datasets that we can leverage via self-supervised learning. Compared to the unlabeled dataset for pretraining, the labeled target dataset is relatively small -- often too small for training a deep neural network from scratch.
Pretraining without additional data
Researchers can easily collect unlabeled images and text from the internet, and pretraining is already standard for computer vision and natural language processing. However, it is less common for tabular methods. That could be because additional data (even if unlabeled) is often unavailable for tabular datasets.
The authors use the target dataset for pretraining instead of additional unlabeled data in this research project. (This mimics a scenario where unlabeled tabular data is unavailable.) During pretraining, the authors regard the target dataset as unlabeled but also explore options that leverage the target labels -- we will discuss this in more detail later.
Overall, the study includes 11 different datasets ranging from 6k to 723k training examples and 6 to 136 features. The datasets cover both classification and regression and numerical and categorical features.

Self-prediction and contrastive learning
Self-supervised learning comes in two broad categories: self-prediction and contrastive learning.
In contrastive learning, we perturb training examples (e.g., via data augmentation), and the models' task is to learn a similarity function. There should be a high similarity between the original example x and the perturbed ("corrupted" example x'. At the same time, the similarity between x and an arbitrary (different) training example should be low.

In self-prediction, we obtain the label from the dataset itself, for example, the masked-word prediction task mentioned above.
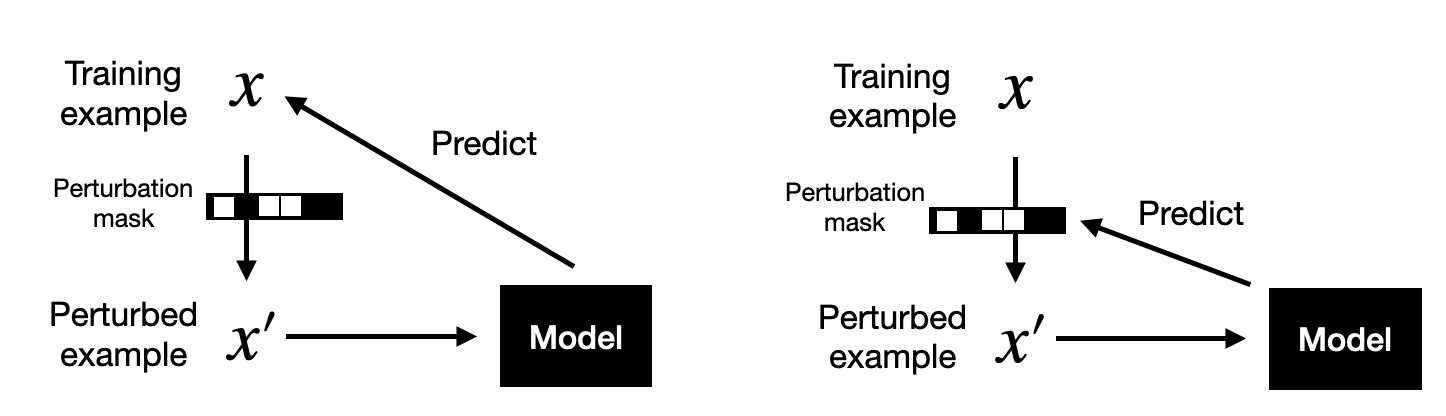

In computer vision, self-prediction is usually superior to contrastive learning, which we can also observe here based on counting the best (bold) results in Table 2 above. The self-prediction pretraining tasks ("rec" and "mask") outperform the contrastive pretraining task ("constrastive").
Note that MLP refers to a regular ("vanilla") multilayer perceptron. MLP-PLR and MLP-T-LR refer to multilayer perceptrons that operate on numerical feature embeddings instead of the raw features.
Including target information during pretraining
Since the authors use the original training set during pretraining, it begs the question of whether the predictive performance improves further when the target information is used during pretraining.
To answer this question, the authors conducted several experiments. I will only describe a subset of the setups they used for brevity.
"sup": Use the perturbed dataset for pretraining in a supervised fashion. Then finetune on the unperturbed dataset.
"rec + target": A modified version of the previous reconstruction-based self-prediction task. First, the target label is one-hot encoded. Second, the encoded target is concatenated with the embedding produced by the model backbone. Third, the model head has to predict the original (unperturbed) training example from the concatenated vector.
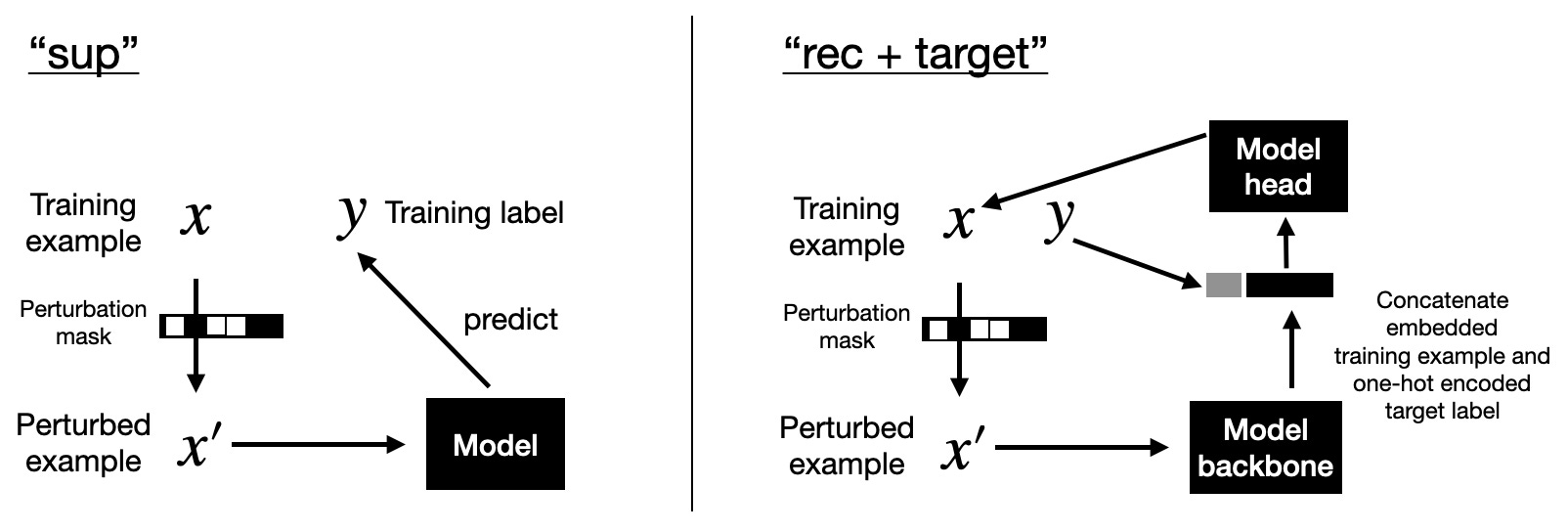
There is no combination that performs best across all datasets based on the results in Table 3 below. However, while there is no clear winner, embedding-based MLPs (i.e., MLP-PLR ad MLP-T-LR) perform generally better than vanilla MLPs. And target-aware pretraining is beneficial compared to target-agnostic pretraining.

Note that "mask + target" is analogous to "rec + target." Here, instead of adding the target information to the reconstruction task, it's added to the mask-based self-prediction task.
Comparison with Gradient Boosting
The previous results revealed that pretraining benefits MLPs. And including target information can further improve these results. The next question is how these deep learning-based methods compare to traditional machine learning methods, namely, gradient boosting.

In most cases, numerical embedding-based MLPs with target-aware mask-based (self-prediction) pretraining perform best. There are only two datasets where gradient boosting (XGBoost and CatBoost) outperforms the pretrained MLPs.
Take-aways
Deep neural networks generally benefit from pretraining. Based on the results presented in this paper, this is also true when working with a tabular dataset.
The vanilla MLP benefits the most from pretraining (Table 2). However, we are usually interested in the best predictive performance. In that case, we should consider MLPs that operate on numerical embeddings instead of the raw features: MLP-PLR and MLP-T-LR. And target-aware mask-based self-prediction ("mask + target") seems to perform best across most datasets.
If you want to play with the code, the authors shared their experiments here on GitHub.
Notable Quote
"Science funding is not so plentiful that society, and scientists, can waste it pursuing dead ends based on fake papers."
Study & Productivity Tips
Free your mind with this one simple trick
One of my favorite productivity tips is to write things down. Writing things down, what do I mean by that? Often, when I am working on something, taking a walk, studying, or just reading a fiction book, I get an exciting idea or think of something I should do. If I don't write it down immediately, it will get stuck in my head and distract me from the activity at hand.
Out of sight, out of mind
Writing things down will stop your head from swirling around, but this only works if you capture the thought or idea in a place you check regularly. Otherwise, you may end up replacing thoughts like "RVSP to Jake's wedding" with "check pocket notebook in my winter jacket" (which contains a note about RSVPing to Jake's wedding).
Write down your ideas and thoughts in a place you regularly check, at least once daily. That's because the random idea can also be time-sensitive, like "ping your co-author to give feedback on the new abstract before the submission deadline tonight" or "swing by the grocery store before 7 pm to get some coffee beans." When I am studying, I also write down key things I want to use or look up later so that it keeps my flow during reading.
Tools matter and don't matter
You want to capture ideas in a place that you check back regularly for further processing. At the same time, the idea-capturing tools and devices don't really matter as long as it's something you regularly check. For example, if you have a daily schedule or list, you can reserve some space in the lower right-hand corner of that list.
If you are a person who regularly checks your emails, consider an app that sends an email to yourself. The Note To Self app works quite well for that -- this is an app for iOS and macOS, but there surely are Android and Windows alternatives out there. What's nice about that is that you can also take it on your walk and jot things down without looking awkward. (Of course, you can also use the built-in Note app. I tried that. Unfortunately, that's one app I usually forget to check when I am back on my computer, though.)

A digital voice recorder can also be a great companion on long walks. It also works excellent when driving or taking walks (especially if you like to take mindful walks with your phone on "Do not disturb").
Long story short, you need to find what works best for you, and it also doesn't have to be the same device.
I like to write things on my daily schedule page (more on that another time) when I am at my desk. However, I usually use the Note to Self app on my phone when I am out and about. And if I go on walks or drive, I prefer a voice recorder.
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Great stuff! Your writing is easy to understand and your figures are excellent.