

RevAIval of Ideas: From Next-Generation Convolutional Neural Networks to LLMs

I hope you had a successful start to the new year, as did AI and deep learning research. In this edition of Ahead of AI #5, I wanted to showcase recent advancements in computer vision rather than simply covering the increasing popularity of large language models. This newsletter aims to revive ideas and take convolutional neural networks to new heights.
But do not worry; I didn't forget about the large language model headlines this month ...
This issue of Ahead of AI features:
The latest advances for pretraining convolutional network architectures via self-supervised learning;
The benefits of training LLMs from scratch;
Open source highlights;
Thirteen alternatives to supervised learning when you have limited training data.
Articles & Trends
We will open this section with a discussion of self-supervised learning for convolutional neural networks and the latest GAN vs. diffusion model comparisons. After our short excursion to computer vision, we will look at some of the benefits of training large language models from scratch and close this section with the latest headlines (since ChatGPT wants the final say).
Next-Generation Convolutional Neural Networks
Self-supervised learning, which lets us leverage large unlabeled datasets for supervised pretraining, has been one of the keys to success behind language and vision transformers. However, self-supervised learning techniques like masked auto-encoding don't necessarily work well for convolutional neural networks (CNNs). At their very best, they lack behind older self-supervised learning techniques such as contrastive learning.

So, how can we leverage successful pretraining techniques used in language and vision transformers to improve purely convolutional networks? The answer is sparse convolutions, a type of convolution operation that only considers a subset of input feature maps or weights to reduce computation and memory usage while still capturing essential features in the data.
Applying self-supervised learning via masked autoencoding to CNNs
What's the problem with using state-of-the-art self-supervised learning techniques in CNNs? Traditional CNNs are not well-suited for handling irregular, randomly masked input images, which we encounter using this pretraining scheme.
What are the issues with regular convolutions on masked pixels?
Computations on masked pixels are redundant (inefficient);
They disturb the data distribution of pixel values (point 2 in the figure below);
Patterns on masked maps will vanish (point 3 in the figure below).
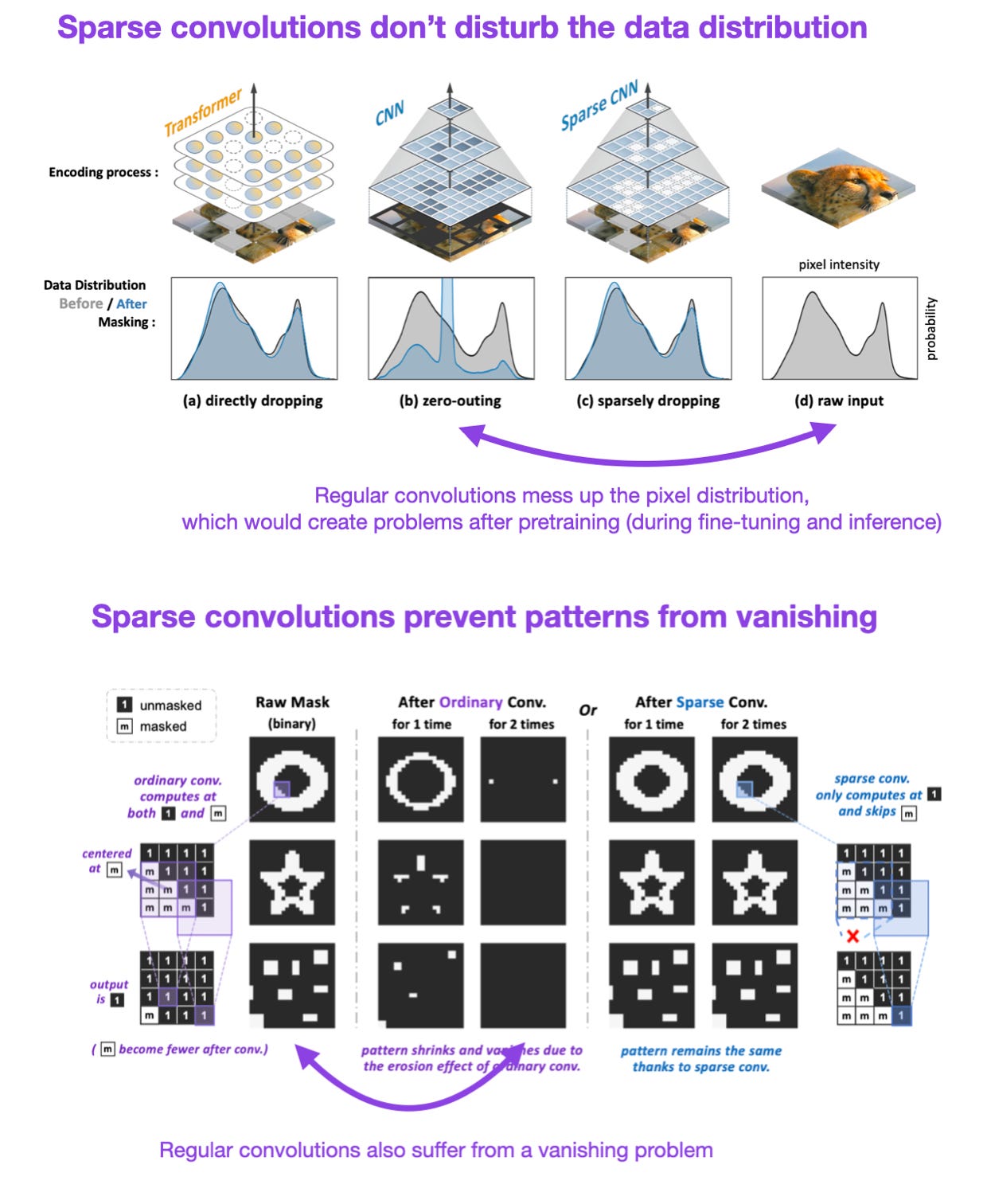
In the recent Designing BERT for convolutional networks paper, researchers proposed using sparse convolutions to address issues of CNNs with masked inputs — they proposed SparK (Sparse masKed modeling with hierarchy).
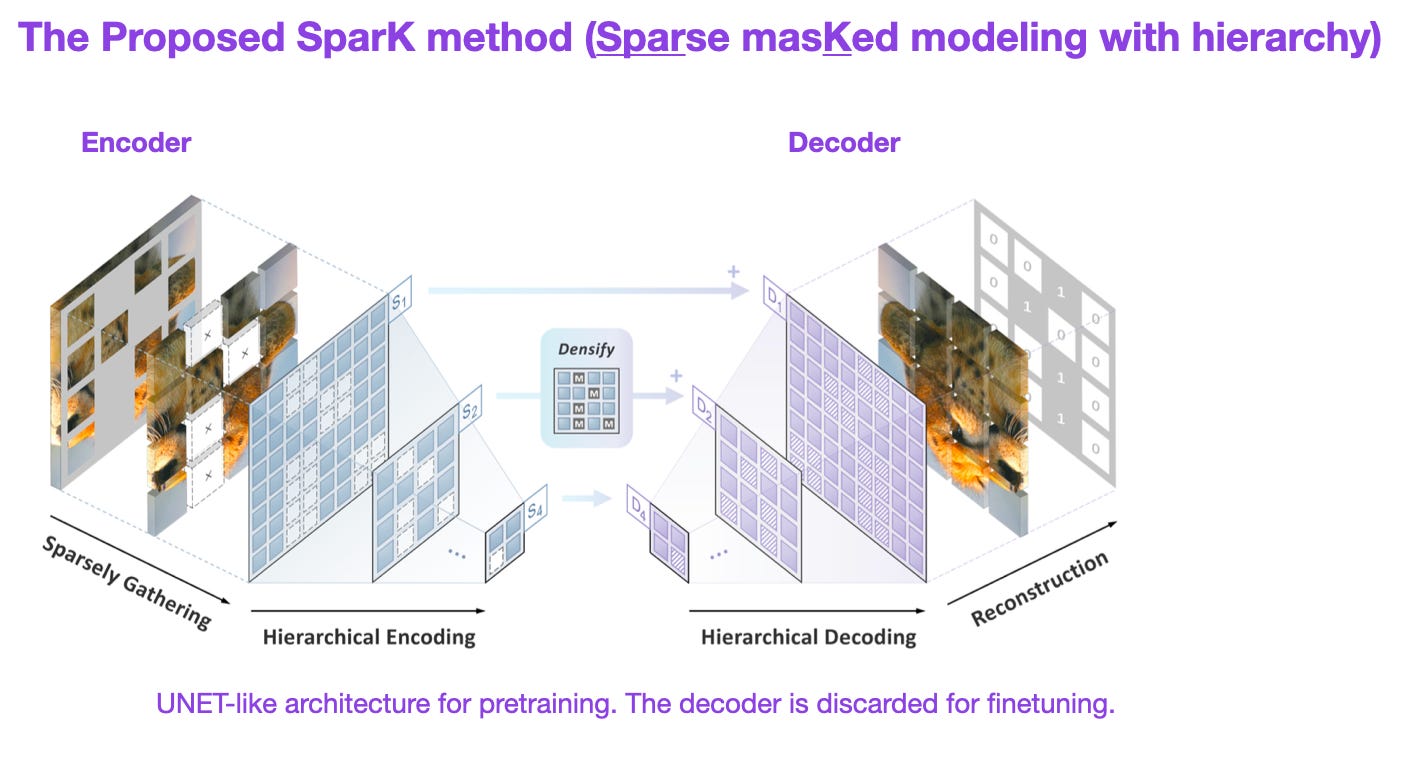
SparK can be applied to any convolutional network. For instance, it has been used with ResNet and ConvNeXt, improving predictive performance by up to 1.7% on ImageNet when those purely convolutional networks are pretrained with 1.28 million unlabeled images.

Does it really work?
The numbers above look pretty convincing, but sometimes results in papers don't generalize well to other architectures or problems. So, it's always nice to consider additional points of evidence.
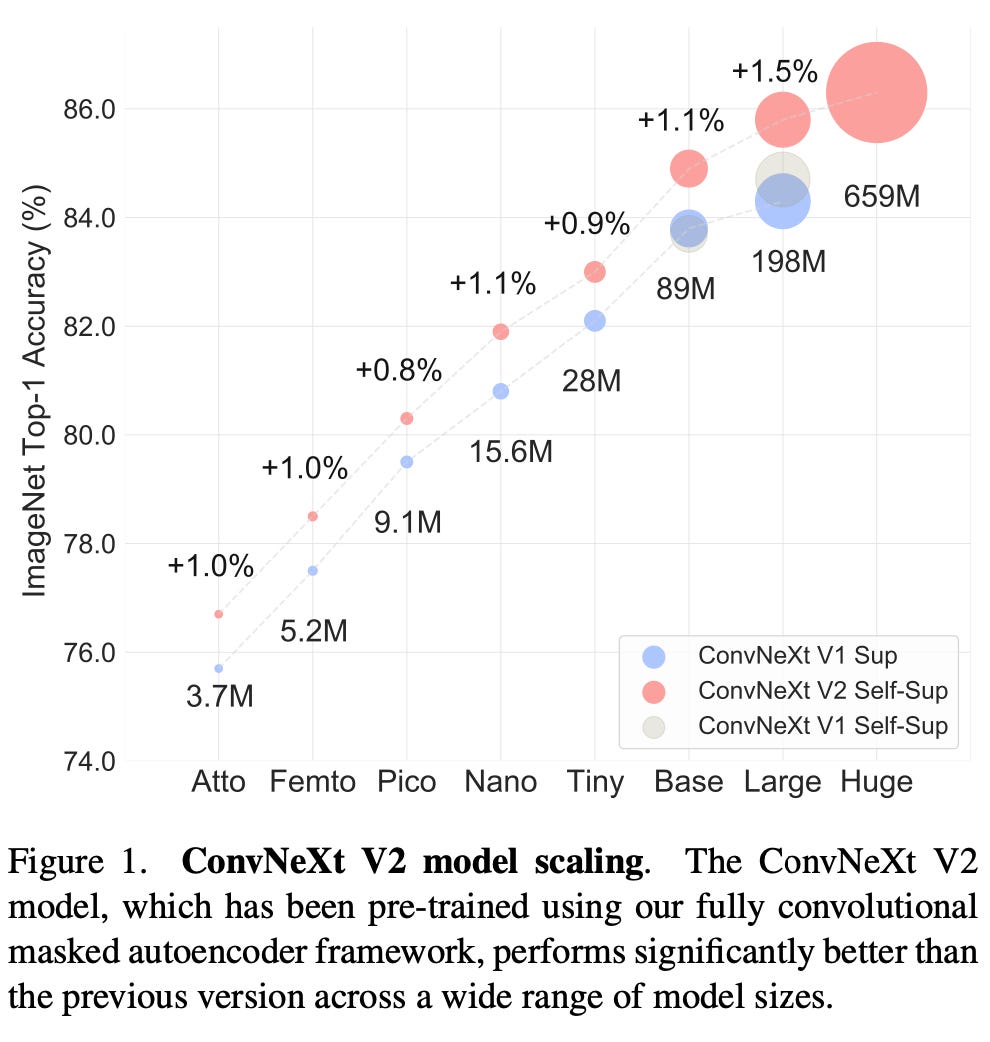
In a recent independent paper, researchers proposed modifying the popular ConvNext architecture with sparse convolutions and global response normalization: ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders.
This ConvNeXt v2 paper co-designs a pure convolutional network for self-supervised via two mechanisms:
using sparse convolutions for sparse patches with a high-mask ratio;
adding a new global response normalization layer.

(1) The use of sparse convolutions allows using high-mask ratios and boosts efficiency during training. Note that during fine-tuning, we can convert the sparse convolutional parts back into standard convolutions.
(2) The global response normalization part is a new type of normalization layer that replaces batch normalization and layer normalization. Without global response normalization, the high-mask ratio via (1) results in feature collapse. The authors found that using global response normalization promotes feature diversity. And it was necessary to achieve good predictive performance. The global response normalization layer is a general technique, and it will be interesting to see whether it can also benefit other architectures in the future.
Like its predecessor, (ConvNeXt, which we covered in Ahead of AI #4) we can use ConvNeXt v2 for image classification, object detection, and instance segmentation.
Remember GANs?
Last year, I jokingly claimed that GANs were dead, but this month, GANs made a strong comeback.
Researchers have created a GAN, StyleGAN-T, that surpasses distilled diffusion models as the leading text-to-image synthesis method in terms of quality and speed, according to the paper StyleGAN-T: Unlocking the Power of GANs for Fast Large-Scale Text-to-Image Synthesis.

I still believe that the diffusion models are the future for generative modeling in the computer vision domain, we shouldn't overlook GANs just yet. And competition is good for business anyways.
Training a Large Language Model (LLM) On A Single GPU?
Yes, that's possible! While contemporary PyTorch open-source libraries make it easy to train large models on multiple GPUs, we often don't have access to extensive hardware resources. The question is whether we (still) can train a large deep learning model on a single GPU like in the old times.
In the paper Cramming: Training a Language Model on a Single GPU in One Day, the researchers trained a masked language model / encoder-style LLM (here: BERT) for 24h on 1 GPU. For comparison, the original 2018 BERT paper trained it on 16 TPUs for four days.
The impressive outcome of this cramming project was that the researchers were able to train BERT with a 78.6 average performance (compared to 80.9) — the larger, the better.
What were some of the performance-squeezing tricks?
Using automated operator fusion & 32/16-bit mixed precision training;
disabling biases in QKV attention matrices and fully-connected layers;
Decreasing the input length from 512 -> 128 tokens;
And what didn't work?
There were no benefits in replacing the original multi-head self-attention mechanism with FLASH attention or Fourier attention;
There was no advantage after changing GELU activations to something else;
Shrinking the number of attention heads is bad; keeping the original 12 attention heads is essential to maintain finetuning performance.
From a predictive performance standpoint, they furthermore observed that
a triangular one-cycle learning rate schedules work best;
dropout was not needed during pretraining due to the extensive training dataset and 1-epoch training schedule;
increasing the vocabulary size past 32k does not improve GLUE performance (but MNLI improves).

Now, all that being said, why don't we simply train smaller models if we have limited resources? To answer this question with some parting advice from this paper: while smaller models have higher throughput, smaller models also learn less efficiently. Thus, larger models do not require more time to train for reaching a specific predictive performance threshold.
Encoder-Style LLMs?
Let's talk a bit more about the encoder-style models used in the cramming paper above.
The recent buzz around large language models is entirely around decoder-style LLMs such as PalM, Chinchilla, and the GPT family that learn to generate text based on being pretrained via next-word prediction. They are sometimes also called autoregressive and unidirectional as they process text from left to right, one token at a time.
In contrast, encoder-style LLMs like BERT are pretrained via masked language modeling — we hide or mask tokens that the LLM has to predict. Since the LLM sees the complete sentence — except for the masked words, of course. This is also referred to as a bidirectional LLM.
As a rule of thumb, decoder-style LLMs are usually better for generative modeling, whereas encoder-style LLMs are better for predictive modeling (think of text classification).

While generative modeling is usually considered as more exciting and "magical," that's typically what we see on social media and in newspaper headlines.
However, I'd argue that most real-world business problems revolve around and rely upon predictive modeling.
Anyways, given that there are now hundreds of different large language transformers out there, it's sometimes easy to lose track. In this case, I highly recommend bookmarking Xavier Amatriain's comprehensive transformer model summaries and family tree: Transformer models: an introduction and catalog — 2023 Edition.
Which GPU?
By the way, if you are wondering which GPU gives you the best bang for the buck, I recommend checking out Tim Dettmer's recently updated The Best GPUs for Deep Learning in 2023 guide.
Also, to find the optimal LLM size for your compute budget, check out the handy new widget at https://howmanyparams.com.
Why do we need to train LLMs from scratch anyways?
And why do you need to pretrain LLMs, anyway, given that many pretrained models are available off the shelf? Consider research/study purposes, or you may want to adapt them to new languages or domains (e.g., think of protein or DNA sequences).
Since language is somewhat universal, the typical workflow is to take a model that was pretrained on a large, general language corpus and then fine-tune it on a target domain — for example, finance articles if the target task is sentiment classification for stock market analysis purposes. However, if large amounts of domain-specific texts exist, it may make sense to also use that data for pretraining.
For example, in a recent paper, a researcher reported that FinBERT, a BERT model that was further pretrained on a collection of 1.8M finance news articles, outperformed all other models for sentiment analysis on finance domains.
Learning the language of life
Another example of why pretraining sometimes makes sense is the recent Deep neural language modeling enables functional protein generation across families paper. Here, researchers trained a 1.2 billion parameter transformer on 280 million proteins sequence to generate new protein sequences (protein sequences consist of one-letter amino acid strings, such as "DIQMTQSPA...".

The LLM was able to generate realistic protein sequences that were not more than 30% similar to existing proteins. But what's really remarkable is that the researchers didn't just train an LLM on amino acid sequences. They went further by synthesizing complete genes and expressing the proteins in reality. These artificial proteins showed the same functionality as natural proteins.
Training LLMs from scratch
A shameless plug: if you are interested in training LLMs from scratch, we recently developed and shared a 50-lines-of-code recipe to do just that.

Headlines
Many noteworthy things happened in January since the buzz around large language models is still in full swing. Since I can't include it all, but it may still be interesting and relevant, I am adding this new Headlines section with short taglines of tech-related newsworthy highlights — my apologies if this is a bit OpenAI- and LLM-heavy this month.
Academia and research
ICLR 2023 paper decisions are out
NeurIPS call for papers announced (abstracts are due May 11)
ICML leaked ~10,000 submitted papers for people to download prior to peer-review
Springer Nature "says it has no problem with AI being used to help write research — as long as its use is properly disclosed."
Science policies state that "text generated by ChatGPT (or any other AI tools) cannot be used in the work, nor can figures, images, or graphics be the products of such tools."
ChatGPT
Microsoft extends multi-billion dollar partnership with OpenAI
Microsoft also begun integrating ChatGPT into its core products, starting with Teams Premium
ChatGPT was updated with "improved factuality and mathematical capabilities" (but as I've shown here it still struggles with basic addition and multiplication)
OpenAI releases AI Text Classifier to detect AI-generated text (I have a short blog post about other detection mechanisms here on my blog)
OpenAI introduces $20 monthly subscription service for ChatGPT
According to report by Semafor, OpenAI is training a ChatGPT model to execute mundane coding tasks (the headline reads "to replace software engineers").
"Google CEO Says Its ChatGPT Rival Coming Soon as a ‘Companion’ to Search"
Google invests $300 million in Anthropic, which is creating its LLM-based chatbot called Claude, in response to the alleged competition with ChatGPT
According to DeepMind CEO Demis Hassabis, "DeepMind is also considering releasing its own chatbot, called Sparrow, for a 'private beta' some time in 2023"
Stable Diffusion and generative image models
Getty Images bans AI-generated content and is suing Stability AI for scraping content.
Shutterstock adds text-to-image AI generation and adds a revenue share compensation plan for creators whose content was used to train AI.
Deep Learning Fundamentals, Unit 4
I am happy to share that Unit 4 of my Deep Learning Fundamentals course is now available! In Unit 4, we are finally tackling the training of multilayer neural networks using PyTorch. And we will discuss some design decisions, such as random weight initialization.

Open Source Highlights
CIFAR10 hyperlightspeedbench
The CIFAR10 hyperlightspeedbench repository provides rapid-experimentation-friendly PyTorch code for training convolutional neural networks on a single GPU. It enables training a model to 94% on CIFAR-10 in less than 10 seconds on a single A100.
Scaling PyTorch models with Lightning 1.9 and Fabric
Lightning 1.9 was released with many changes. One of the highlights is the new Fabric class, a more light-weight alternative to the PyTorch Trainer class and utilities.
Like the Trainer, Fabric makes it straightforward to scale a PyTorch model with just a few lines of code and run it on distributed devices. But compared to using the Trainer class, the training loop and optimization logic remain under your full control.
You can read more in the Fabric (Beta) documentation here.

nanoGPT — an educational code base for GPT
Andrej Karpathy shared nanoGPT, a rewrite for the popular minGPT codebase that aims to illustrate the inner workings of GPT-2 (the decoder-style large language models) in less than 600 lines of code for the model and training loop combined.
Ruff — an extremely fast Python linter
The Ruff linter — written in rust — is 10x-100x faster than existing linters, including the popular Flake8 package.
Code linters are helpful because they check your code for potential errors, inconsistencies, and adherence to coding standards. Code linters also enforce consistent coding styles, which can be especially helpful for projects with multiple contributors. However, working with large code bases, those linters can sometimes be a tad slow (especially if you use lower-end hardware to check GitHub submissions). In this case, Ruff is worth a try — it can be installed via pip without hassle!
Machine Learning Questions & Answers
Question: Suppose we plotted a learning curve and found that the machine learning model overfits and could benefit from more training data. Name different approaches for dealing with limited labeled data in supervised machine learning settings.
Answer:
Next to collecting more data, there are several methods more or less related to regular supervised learning that we can use in limited-labeled data regimes.
1) Label more data
Collecting additional training examples is often the best way to improve the performance of a model. However, this is often not feasible in practice. Listed below are various alternative approaches.
2) Bootstrapping the data
It can be helpful to "bootstrap" the data by generating modified (augmented) or artificial (synthetic) training examples to boost the performance of the predictive model. (Details are omitted for the sake of brevity in this newsletter.)
Of course, improving the quality of data can also lead to improved predictive performance of a model. (Details abou Data-Centric AI are again omitted for brevity.)
3) Transfer learning
Transfer learning describes training a model on a general dataset (e.g., ImageNet) and then fine-tuning the pretrained target dataset (e.g., a specific dataset consisting of different bird species). Transfer learning is usually done in the context of deep learning, where model weights can be updated. This is in contrast to tree-based methods since most decision tree algorithms are nonparametric models that do not support iterative training or parameter updates.

4) Self-supervised learning
Similar to transfer learning, self-supervised learning, the model is pretrained on a different task before it is fine-tuned to a target task for which only limited data exists. However, in contrast to transfer learning, self-supervised learning usually relies on label information that can be directly and automatically extracted from unlabeled data. Hence, self-supervised learning is also often called unsupervised pretraining. Common examples include "next word" (e.g., used in GPT) or "masked word" (e.g., used in BERT) prediction in language modeling. Or, an intuitive example from computer vision includes inpainting: predicting the missing part of an image that was randomly removed.
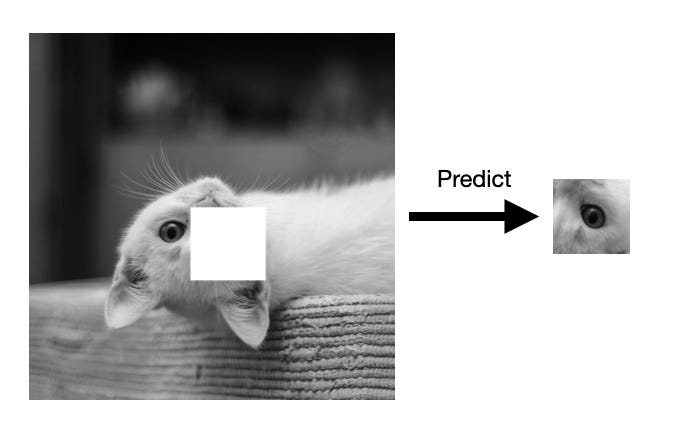
5) Active learning
In active learning, we typically involve manual labelers or users for feedback during the learning process. However, instead of labeling the entire dataset upfront, active learning includes a prioritization scheme for suggesting unlabeled data points for labeling that maximize the machine learning model's performance.
The name active learning refers to the fact that the model is actively selecting data for labeling in this process. For example, the simplest form of active learning selects data points with high prediction uncertainty for labeling by a human annotator (also referred to as an oracle).

6) Few-shot learning
In a few-shot learning scenario, we often deal with extremely small datasets where we usually only have a handful of examples per class. In research contexts, 1-shot (1 example per class) and 5-shot (5 examples per class) are very common. An extreme case of few-shot learning is zero-shot learning, where no labels are provided. A recently popular example of zero-shot learning is GPT-3 and related language models. Here, the user has to provide all the necessary information via the input prompt, as illustrated in the figure below.
7) Meta-learning
We can think of meta-learning as "learning to learn" — we develop methods that learn how machine learning algorithms can best learn from data. Over the years, the machine learning community developed several approaches for meta-learning. To further complicate matters, meta-learning can refer to different processes.
Meta-learning is one of the main subcategories of few-shot learning (mentioned above). Here, the focus is on learning a good feature extraction module. The feature extraction module converts support and query images into vector representations. These vector representations are optimized for determining the predicted class of the query example via comparisons with the training examples in the support set.
Another branch of meta-learning, unrelated to the few-shot learning approach above, is focused on extracting meta-data (also called meta-features) from datasets for supervised learning tasks. The meta-features are descriptions of the dataset itself. For example, these can include the number of features and statistics of the different features (kurtosis, range, mean, etc.).
The extracted meta-features provide information for selecting a machine learning algorithm for the given dataset at hand. Using this approach, we can narrow down the algorithm and hyperparameter search spaces, which helps reduce overfitting when the dataset is small.
8) Weakly supervised learning
Weakly supervised learning is a procedure where we use an external label source to generate labels for an unlabeled dataset. Often, the labels created by a weakly supervised labeling function are more noisy or inaccurate than those produced by a human or domain expert; hence, the term weakly supervised.
Often, we can develop or adopt a rule-based classifier to create the labels in weakly supervised learning — these rules usually only cover a subset of the unlabeled dataset.
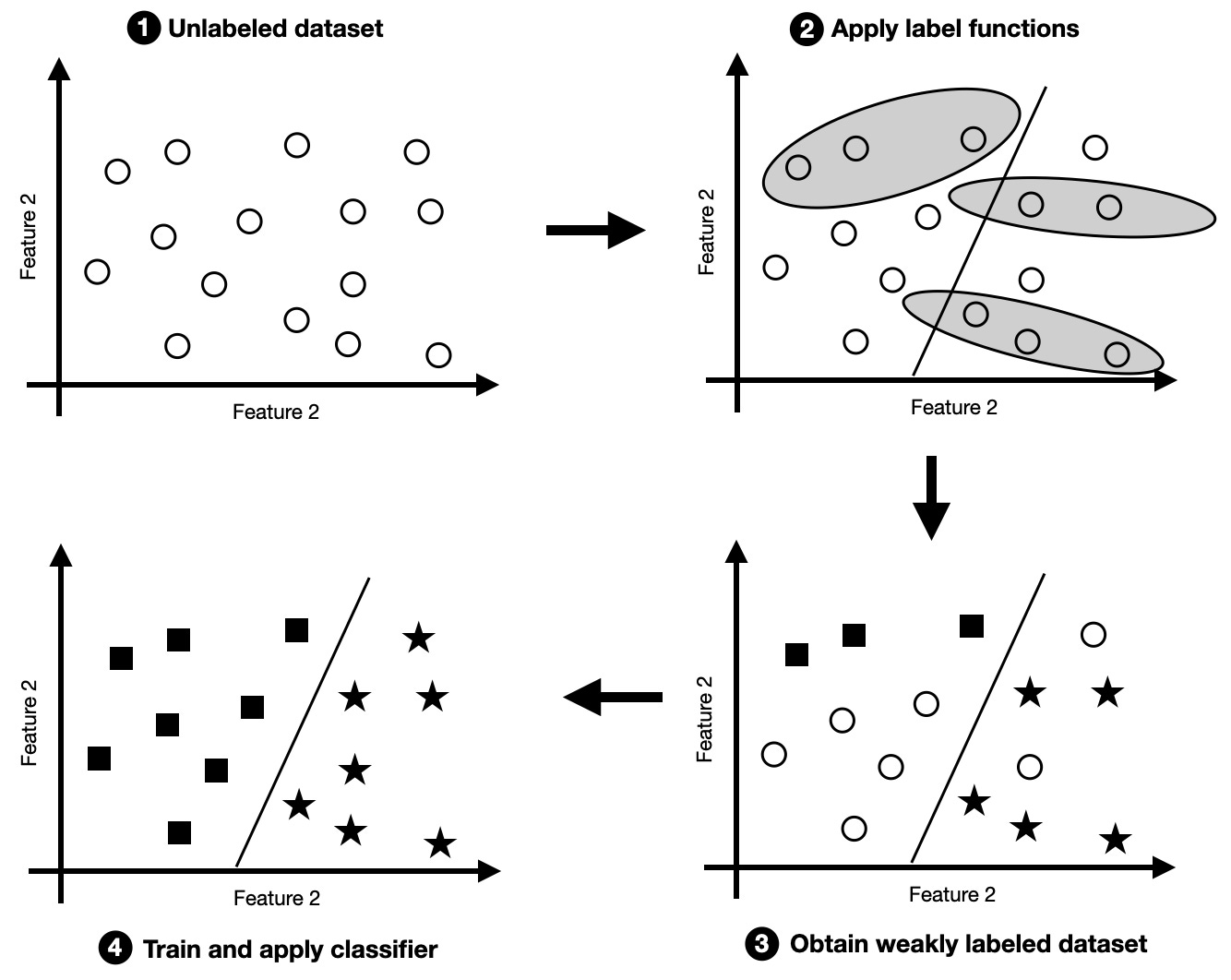
Imagine the context of email spam classification as an example of a rule-based approach for data labeling. In weak supervision, we could design a rule-based classifier based on the keyword "SALE" in the email subject header line to identify a subset of spam emails. Note that while we may use this rule to label certain emails as spam-positive, we should not apply this rule to label emails without SALE as non-spam but leave those either unlabeled or apply a different rule to these.
In short, weakly supervised learning is an approach for increasing the number of labeled instances in the training set. Hence, other techniques, such as semi-supervised, transfer, active, and zero-shot learning, are fully compatible with weakly supervised learning.
9) Semi-supervised learning
Semi-supervised learning is closely related to weakly supervised learning described above: we create labels for unlabeled instances in the dataset. The main difference between weakly supervised and semi-supervised learning is how we create the labels (Semi-supervised learning is sometimes referred to as a subcategory of weakly supervised learning and vice versa.)
In weak supervision, we create labels using an external labeling function that is often noisy, inaccurate or only covers a subset of the data. In semi-supervision, we do not use an external label function but leverage the structure of the data itself.
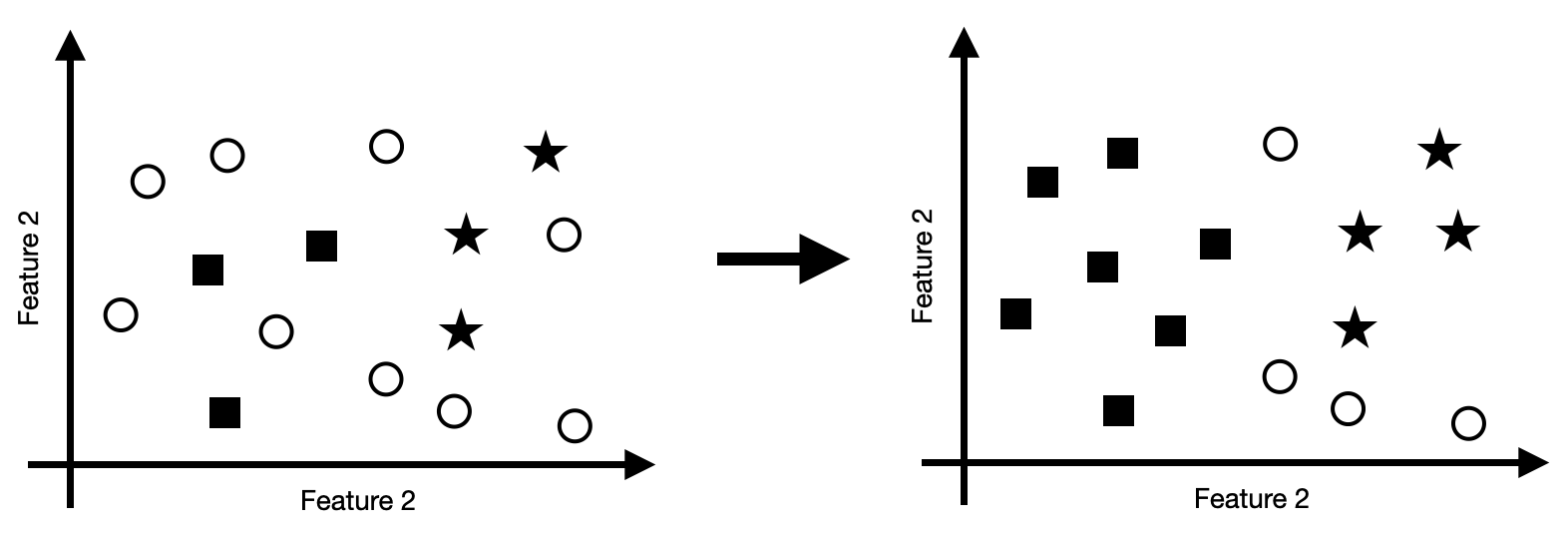
In semi-supervised learning, we can, for example, label additional data points based on the density of neighboring labeled data points, as illustrated in the figure below.
While we can apply weak supervision to an entirely unlabeled dataset, semi-supervised learning requires at least a portion of the data to be labeled. In practice, it is possible first to apply weak supervision to label a subset of the data and then use semi-supervised learning to label instances that were not captured by the labeling functions.
10) Self-training
Self-training is a category that falls somewhere between semi-supervised learning and weakly supervised learning. In self-training, we train a model or adopt an existing model to label the dataset. This model is also referred to as a pseudo-labeler.
Since the model used in self-training does not guarantee accurate labels, self-training is related to weakly supervised learning. Moreover, while we use or adopt a machine learning model for this pseudo-labeling, self-training is also related to semi-supervised learning.
11) Multi-task learning
Multi-task learning trains neural networks on multiple, ideally related tasks. For example, suppose we are training a classifier to detect spam emails; here, spam classification is the main task. In multi-task learning, we can add one or more related tasks the model has to solve. These additional tasks are also referred to as auxiliary tasks. If the main task is email spam classification, an auxiliary task could be classifying the email's topic or language.
Typically, multi-task learning is implemented via multiple loss functions that have to be optimized simultaneously — one loss function for each task. The auxiliary tasks serve as an inductive bias, guiding the model to prioritize hypotheses that can explain multiple tasks. This approach often results in models that perform better on unseen data.

The figure above illustrates the difference between hard and soft parameter sharing. In hard parameter sharing, only the output layers are task-specific, while all tasks share the same hidden layers and neural network backbone architecture. In contrast, soft parameter sharing uses separate neural networks for each task, but regularization techniques such as distance minimization between parameter layers are applied to encourage similarity among the networks.
12) Multi-modal learning
While multi-task learning involves training a model with multiple tasks and loss functions, multi-modal learning focuses on incorporating multiple types of input data.
Common examples of multi-modal learning are architectures that take both image and text data as input. Depending on the task, we may employ a matching loss that forces the embedding vectors between related images and text to be similar, as shown in the figure below.

The figure above shows image and text encoders as separate components. The image encoder can be a convolutional backbone or a vision transformer, and the language encoder can be a recurrent neural network or language transformer. However, it's common nowadays to use a single transformer-based module that can simultaneously process image and text data.
Optimizing a matching loss, as shown in the previous figure, can be useful for learning embeddings that can be applied to various tasks, such as image classification or summarization. However, it is also possible to directly optimize the target loss, like classification or regression, as the figure below illustrates.

Intuitively, models that combine data from different modalities generally perform better than uni-modal models because they can leverage more information. Moreover, recent research suggests that the key to the success of multi-modal learning is the improved quality of the latent space representation.
13) Inductive biases
Choosing models with stronger inductive biases can help to lower data requirements by making assumptions about the structure of the data. For example, due to their inductive biases, convolutional networks require less data than vision transformers as discussed in Q13.
Which techniques should we use?
Now that we covered several techniques for lowering the data requirements, which ones should we use?
Collecting more data and techniques such as data augmentation and feature engineering are compatible with all the methods discussed above. Also, multi-task learning and multi-modal inputs can be used with the other learning strategies outlined above. If the model suffers from overfitting, techniques from other Q & As (Reducing overfitting via model modifications, and Reducing overfitting via dataset modifications) should also be included.
How about active learning, few-shot learning, transfer learning, self-supervised learning, semi-supervised learning, and weakly supervised learning? Which technique(s) to try highly depends on the context, and the figure below provides an overview that can be used for guidance.

The black boxes are not terminal nodes but arch back to "Evaluate model performance" (the arrows were omitted to avoid visual clutter).
Machine Learning Q & AI
If you liked the Q&A above and want to read more of these, this was actually an excerpt from my new book, Machine Learning Q & AI, which is available on Leanpub!

There is a temporary ahead-of-ai coupon code for readers of Ahead of AI to get 33% off: https://leanpub.com/machine-learning-q-and-ai/c/ahead-of-ai (the coupon is valid until February 15).
Notable Quote
The best analogy that I‘ve found for AI is that it’s like a calculator for reading and writing. — Naval
This quote appeals to me, similar to the notion of "a computer as a bicycle for the mind." However, upon further reflection, the analogy falls short. Calculators are deterministic and precise, unlike today's AI models. A better comparison would be to view large language models as a thesaurus, but for entire sentences and paragraphs instead of just individual words.
Study & Productivity Tips
One of the best time commitments when working through textbooks or courses is to do the exercises and quizzes! Sure, often, it feels more productive when we read along — because it's much quicker. But these activities are important for several reasons:
We are assessing our understanding by identifying knowledge gaps. Sometimes, when we struggle with quizzes and exercises, we may have to review the material several times until it sinks in. While it sometimes feels less satisfying than completing the next chapter or unit, it's important if we want to ensure that we get the most out of the material. Learning is a marathon, not a sprint.
Active learning. Doing exercises and quizzes actively engages us more, and it promotes a deeper understanding of the material compared to reading or listening passively.
Motivation! Above, I mentioned that doing exercises and quizzes can sometimes feel less satisfying than progressing to the next chapter or unit. I suspect that's because we are constantly trained to try to do more and more things. And getting through a book or course quicker may mean we can check it off sooner — who doesn't have an endless pile of things to do? However, completing exercises and quizzes can give us a better sense of accomplishment and motivate us to continue our studies.
Real-world readiness. Exercises and quizzes sometimes simulate real-world scenarios helping us to put the learned material into action — often, that's why we are learning the material in the first place!
Making good exercises and quizzes is not easy, and I always tell my students that
making the exam is harder than taking the exam.
I will try my best to add those to any future courses and books I create.
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Very clear explanations throughout the article. Thank you
One interesting approach that I have come across for Active Learning is Label Dispersion. It's a good way of quantifying model uncertainity. TL;DR- Have a model predict an input's class a bunch of times. If it gets different outputs each time, your model is unsure. Turns out this works a lot better than using confidence.
The original paper introduced this idea in their paper- When Deep Learners Change Their Mind: Learning Dynamics for Active Learning- https://arxiv.org/abs/2107.14707
My breakdown of the paper- https://medium.com/mlearning-ai/evaluating-label-dispersion-is-it-the-best-metric-for-evaluating-model-uncertainty-e4a2b52c7fa1
This idea works for classification, but I've had success expanding it for regression as well. The process is simple- use an ensemble of diverse models, and their spread is the uncertainity of your prediction. You can take it a step further, and use probabilistic models + multiple inferences for more thoroughness.