

Looking Back at 2022: A Big Year For AI

Happy New Year! I'm thrilled to see that Ahead of AI has gained more than 20,000 subscribers after only 3 issues. This is a great motivator to keep writing, and I hope that everyone has a healthy and successful 2023 ahead!
It's been ten years since I first started exploring the field of machine learning, but this year has proven to be the most exciting and eventful one yet. Every day brings something new and exciting to the world of machine learning and AI, from the latest developments and breakthroughs in the field to emerging trends and challenges.
To mark the start of the new year, this month's issue will feature a review of the top ten papers I've read in 2022.
Articles & Trends
In January 2022, diffusion models caught my eye for the first time, and I suspected something big was coming. However, I never expected what followed in just a matter of months: DALLE-2, Imagen, Stable Diffusion, and many others.
Similarly, large language models have had a big year, with the recent ChatGPT putting the cherry on top and stealing the show. What a year!
However, since we already discussed those diffusion models in issue 1, various language models in issue 2, and you probably can't hear "ChatGPT" anymore, let me keep this section brief. So instead, let's jump to the December highlights and a summary of a state of AI report and industry survey by McKinsey before going over 5 noteworthy papers published this year.
December Highlights
There has been a rapid release of the milestones mentioned above that will be hard to top. However, that doesn't mean December was dull. So, keeping it brief, here are two papers that caught my eye.
What do vision transformers (ViTs) learn?
A visual exploration shows that ViTs learn inductive biases or features similar to those learned by convolutional networks (CNNs). For example, the early layers of ViTs capture edges and textures, while later layers learn more complex representations to capture broader concepts.

Regarding generative modeling, ViTs tend to generate higher-quality backgrounds than CNNs. This raises the question of how ViTs handle backgrounds and foregrounds in prediction tasks. It appears that ViTs are better at predicting the target class than CNNs when backgrounds are removed, and they also perform better when foregrounds are removed. This suggests that ViTs may be more selective in relying on certain features based on their presence or are simply more robust in general.
Paper: What do Vision Transformers Learn? A Visual Exploration
A diffusion model for generating proteins
Diffusion models have resulted in breakthrough peformance when it comes to image generation, how about generating protein structures? Researchers have developed a diffusion model, called RoseTTAFold Diffusion (RFDiffusion) for de novo protein synthesis -- proteins that are created from scratch, rather than being derived from preexisting proteins found in nature.
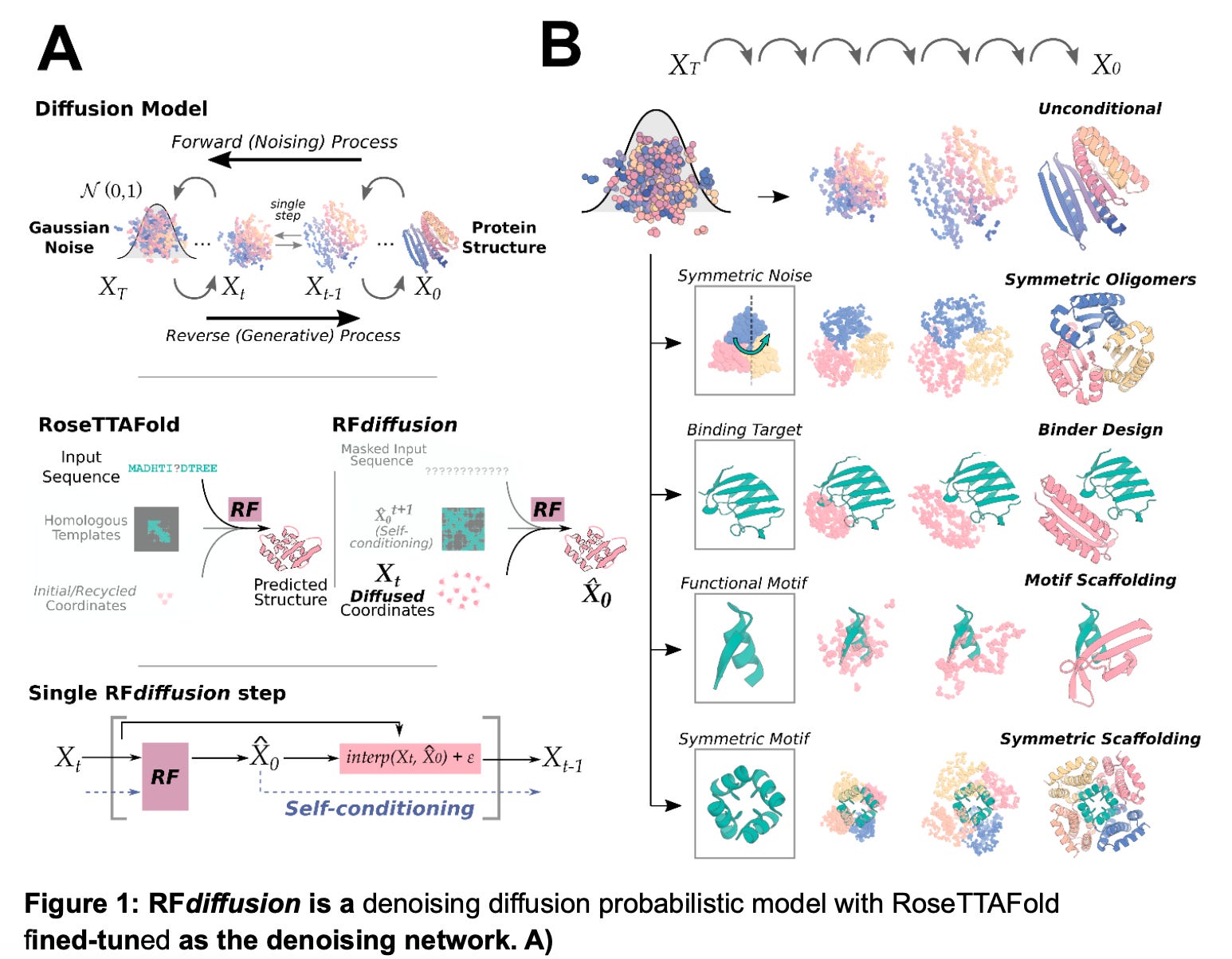
It is important to distinguish de novo proteins, which are synthesized in the laboratory using amino acid sequences that have no evolutionary history, from systems such as AlphaFold and AlphaFold2, which use existing amino acid sequence data to predict protein 3D structures. However, it is worth noting that AlphaFold2 was used to validate the results of the RDiffusion study.
Industry Trends
And as researchers, we usually (try to) work on and read about the state-of-the-art in AI. But what is actually used in industry today? According to McKinsey's recent state of AI report, it's not large language models (transformers).*
(*It is important to consider that the findings in this report may not accurately reflect the experiences of all companies due to the limitations of the sample size and representativeness.)

Let me summarize some takeaways from the graphic above that I found interesting.
Natural language processing has always been popular in industry, but it was usually substantially surpassed by computer vision applications. Now, for the first time, we see that computer vision and natural language processing are almost tied.
Natural-language text understanding (which may refer to text classification*) is almost twice as popular as natural-language "generation". Note that natural-language generation typically dominates the news: GPT-3, Galactica, ChatGPT, and others.
(*Text understanding may include summarization. Summarization is also "generative," so I assume it largely refers to classification-like tasks here. On the flip side, categories can overlap.)
Transformers rank at the bottom.
It appears that many companies have not yet adopted BERT-like language model encoders for text understanding and classification (1). Instead, they may still be using bag-of-word-based classifiers or recurrent neural networks. Similarly, it seems that GPT-like model decoders are not yet being widely used for language generation, so text generation may still rely heavily on recurrent neural networks and other traditional methods.
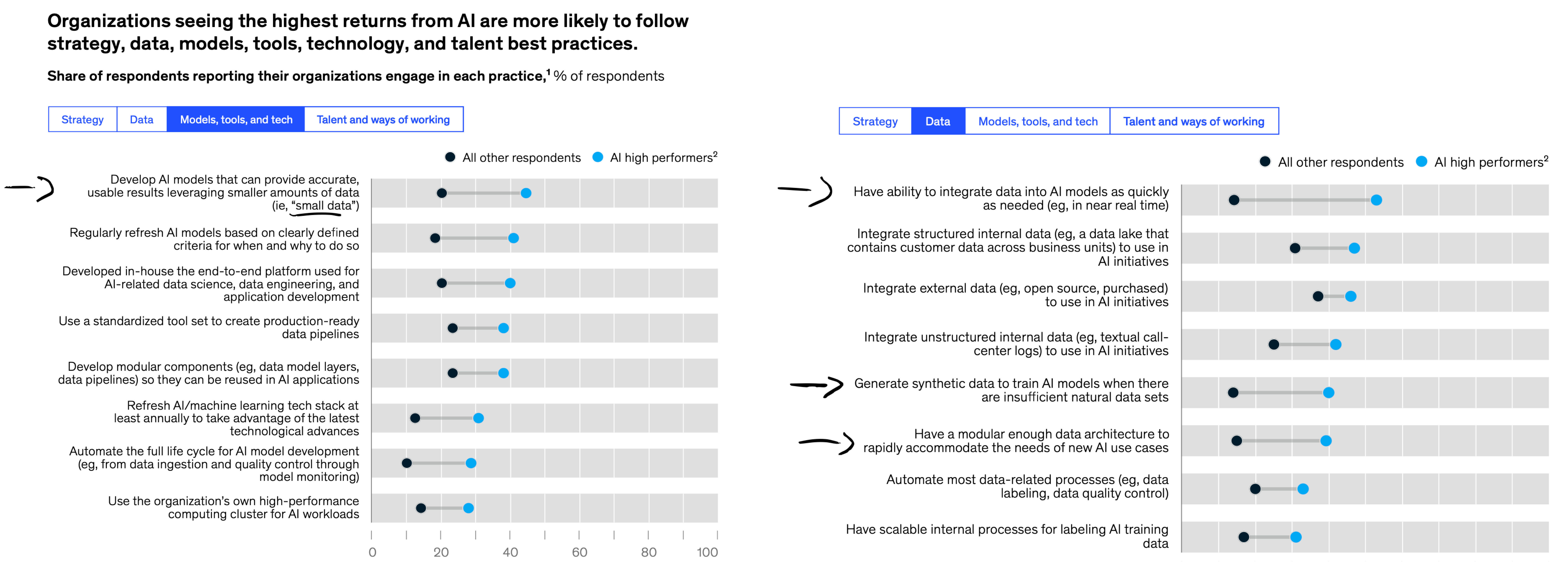
Data set sizes, getting data to production, and model explainability
Additional insights I found interesting (based on the figure below):
It's important to be able to leverage "small data" (keyword: data-centric AI). When data is not available, the ability to generate synthetic data is useful.
Having the ability to integrate data into the AI model as quickly as possible is what sets high-performers apart from the competition. A good software framework and infrastructure setup may be critical for this.
Most high-performing companies unfortunately don't care about model interpretibility (yet).


Source: McKinsey State of AI Report 2022

Papers of the Year
The following are the top three papers that I read in 2022, along with a short discussion of each. Of course, there are many, many more exciting and potentially timeless and influential papers that were published this year.
Keeping it to "only" top-3 was particularly challenging this year, so there is also an extended list below featuring seven additional papers from my top-10 list.
1) ConvNeXt
The A ConvNet for the 2020s paper is a highlight for me because the authors were able to design a purely convolutional architecture that outperformed popular vision transformers such as Swin Transformer (and all convolutional neural networks that came before it, of course).

This so-called ConvNeXt architecture may well be the new default when it comes to using convolutional neural networks not only for classification, but also object detection and instance segmentation -- it can be used as a backbone for Mask R-CNN, for example.
As the authors stated in the paper, they were inspired by modern vision transformer training regimes as well as the fact that the Swin Transformer hybrid architecture showed that convolutional layers are still relevant. That's because pure vision transformer architectures lack useful inductive biases such as translation equivariance and parameter-sharing (i.e., the "sliding window" in convolutions).
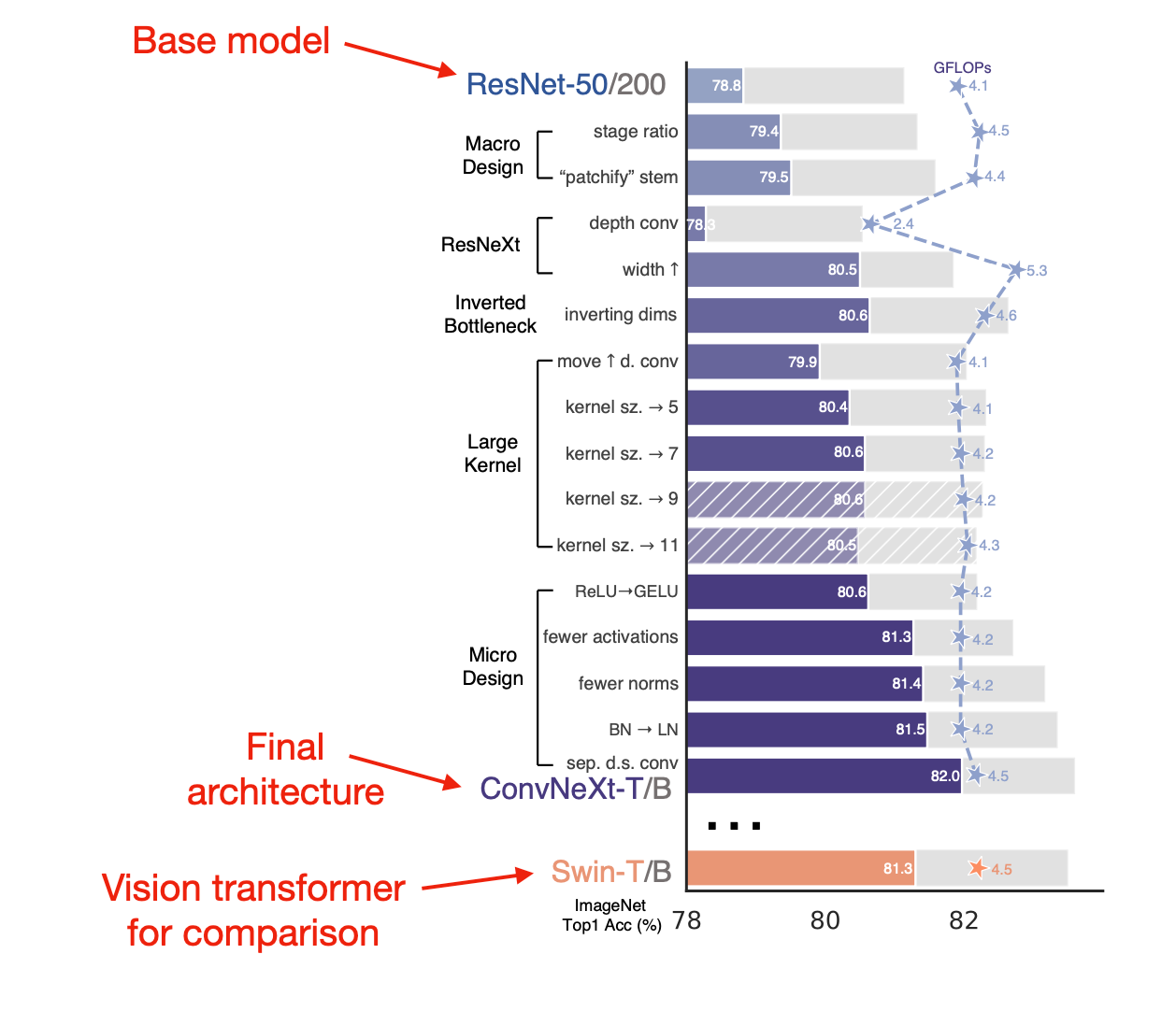
To develop ConvNeXt, the authors started out with a ResNet-50 base architecture and adopted architecture modifications and training regimes adopted from modern vision transformer training regimes. Note that these were not new, even in the context of convolutional neural networks. However, the novelty here is that the authors used, analyzed, and combined these techniques effectively.
Which techniques did they adopt? It's a long list, including depthwise convolutions, inverted bottleneck layer designs, AdamW, LayerNorm, and many more. You can find a summary in the figure below. In addition, the authors also used modern data augmentation techniques such as Mixup, Cutmix, and others.
2) MaxViT
Despite convolutional neural networks making quite the comeback with ConvNeXt above, vision transformers are currently getting all the attention (no pun intended).
MaxViT: Multi-axis Vision Transformer highlights how far vision transformers have come in recent years. While early vision transformers suffered from quadratic complexity, many tricks have been implemented to apply vision transformers to larger images with linear scaling complexity.

In MaxViT, this is achieved by decomposing an attention block into two parts with local-global interaction:
local attention ("block attention");
global attention ("grid attention").
It's worth mentioning that MaxViT is a convolutional transformer hybrid featuring convolutional layers as well.
And it can be used for predictive modeling (incl. classification, object detection, and instance segmentation) as well as generative modeling.

As a side note, a search for "vision transformer" on Google Scholar yields over 5,000 results for 2022 alone. This high number of results, while potentially including false positives, demonstrates the widespread popularity and interest in vision transformers.

But no worries, vision transformers won't entirely replace our beloved convolutional neural networks. Instead, as MaxViT highlights, the current trend goes towards combining vision transformers and convolutional networks into hybrid architectures.
3) Stable Diffusion
Before ChatGPT became the state of the show, it was not too long ago since Stable Diffusion was all over the internet and social media. Stable Diffusion is based on the paper High-Resolution Image Synthesis with Latent Diffusion Models, which was uploaded in December 2021. But since it was presented at CVPR 2022 and got the spotlight with the Stable Diffusion in August 2022, I think it's fair to include it in this 2022 list.
Diffusion models (the topic of the first Ahead of AI issue), are a type of probabilistic model that are designed to learn the distribution of a dataset by gradually denoising a normally distributed variable. This process corresponds to learning the reverse process of a fixed Markov Chain over a length of T.

Unlike GANs, which are trained using a minimax game between a generator and a discriminator, diffusion models are likelihood-based models trained using maximum likelihood estimation (MLE). This can help to avoid mode collapse and other training instabilities.
Diffusion models have been around for some time (see Deep Unsupervised Learning using Nonequilibrium Thermodynamics, 2015) but were notoriously expensive to sample from during training and inference. The authors of the 2022 paper above mentioned a runtime of 5 days to sample 50k images.
The High-Resolution Image Synthesis with Latent Diffusion Models paper's novelty is in applying diffusion in latent space using pretrained autoencoders instead of using the full-resolution raw pixel input space of the original images directly.

The training process can be described in two phases: First, pretrain an autoencoder to encode input images into a lower-dimensional latent space to reduce complexity. Second, train diffusion models on the latent representations of the pretrained autoencoder.
Operating in latent space reduces the computational costs and complexity of diffusion models for training and inference and can generate high-quality results.
Another contribution of this paper is the cross-attention mechanism for general conditioning. So, next to unconditional image generation, the proposed latent diffusion model can be capable of inpainting, class-conditional image synthesis, super-resolution, and text-to-image synthesis -- the latter is what made DALLE-2 and Stable Diffusion so famous.
Seven Other Paper Highlights of 2022
Here are short summaries of seven other papers that I had on my original top-10 list:
A Generalist Agent. In this paper, the researchers introduce Gato, which is capable of performing over 600 tasks, ranging from playing games to controlling robots.
Training Compute-Optimal Large Language Models. To achieve optimal computation during training, the researchers found that it's necessary to scale both the model size and the number of training tokens by the same factor. They created a model called Chinchilla that, for example, outperformed Gopher using 4 times fewer parameters and 4 times more data.
PaLM: Scaling Language Modeling with Pathways: The proposed PaLM model shows impressive natural language understanding and generation capabilities on various BIG-bench tasks. To some extent, it can even identify cause-and-effect relationships.
Robust Speech Recognition via Large-Scale Weak Supervision. This paper introduces the Whisper model, which was trained for 680,000 hours on multilingual tasks and exhibits robust generalization to various benchmarks. I was very impressed with the Whisper model introduced in this paper. I used it for generating the subtitles for my Deep Learning Fundamentals – Learning Deep Learning With a Modern Open Source Stack and Introduction to Deep Learning classes.
Revisiting Pretraining Objectives for Tabular Deep Learning. I enjoined reading quite a lot of deep-learning-for-tabular-data papers. I particularly liked this paper because it highlights and reminds us how important it is to pretrain models on additional (typically unlabeled) data. (You can't easily do this with tree-based models like XGBoost.)
Why do tree-based models still outperform deep learning on tabular data? The main takeaway is that tree-based models (random forests and XGBoost) outperform deep learning methods for tabular data on medium-sized datasets (10k training examples). But the gap between tree-based models and deep learning becomes narrower as the dataset size increases (here: 10k -> 50k). Unfortunately, this paper doesn't include many state-of-the-art deep tabular networks, but it features a robust analysis and an interesting discussion. It is definitely worth reading.
Evolutionary-scale prediction of atomic level protein structure with a language model. The paper proposed the largest language model for predicting the three-dimensional structure of proteins to date. It's also faster than previous methods while maintaining the same accuracy. This model has created the ESM Metagenomic Atlas, the first large-scale structural characterization of metagenomic proteins, featuring over 617 million structures.
Open Source Highlights
Scikit-learn 1.2
The new version of my favorite machine learning library, scikit-learn came out in December. My highlights are around the HistGradientBoostingClassifier. (The HistGradientBoostingClassifier is an implementation of the LightGBM.)
The HistGradientBoostingClassifier now supports
interaction constraints (in trees, features that appear along a particular path are considered as "interacting");
class weights;
feature names for categorical features.
PaLM + RLHF - Pytorch (WIP)
PaLM + RLHF - Pytorch is an implementation of RLHF (Reinforcement Learning with Human Feedback) on top of the PaLM architecture mentioned in the top-10 paper list above. It may be the first open-source equivalent of ChatGPT. The big caveat is that it doesn't come with pretrained weights (yet).
Echo
Remember OpenAI's Whisper model from Ahead of AI Issue #1? Whisper (also included in the top-10 paper liset above) is a large language model for generating high-quality subtitles.
I've tried many subtitle generators over the years, and I am genuinely impressed by the quality of the subtitles it generates. In fact, I was so impressed that I used it to generate the subtitles for the Deep Learning Fundamentals course as well! (PS: it's also one of the few models that handle non-native accents well!)
Last month we released the Echo app, which provides a user-friendly interface around Whisper that lets you drag & drop videos directly from your computer. Like Muse, which runs Stable Diffusion, Echo is another example of putting a large model into production and scaling it to multiple users using the Lightning AI framework.

Of course, Echo is fully open-source. Check out the Deploy OpenAI Whisper as a Cloud Product tutorial to learn how this was built.
Notable Quote
If you devote yourself to anything diligently for ten years, that will make you an expert. (That is the time that it would take to earn two master's degrees and a doctorate.)
-- Elizabeth Gilbert
Announcement: Deep Learning Fundamentals, Unit 3
I have been heads-down working on Deep Learning Fundamentals -- Learn Deep Learning With a Modern Open-Source Stack!
This free course teaches you deep learning from the ground up, from machine learning basics to training state-of-the-art deep neural networks on multiple GPUs in PyTorch.
I am happy to share that Unit 3 is out now. In Unit 2, we introduced PyTorch as a tensor/array library. In Unit 3, we take it a step further and talk about automatic differentiation!
I would love to hear your feedback! Please reach out on social media or the forum. I'd love to hear what you think!
Study & Productivity Tips
A Yearly Review
One of the things to keep me sane is to do a weekly review (more on that in another newsletter). Since it's the end of the year, let me take this opportunity to write about my yearly review routine, which I usually do around New Year's Eve.
It's an exercise to reflect on your accomplishments (which hopefully serves as motivation) and what you want to accomplish next (to keep you focused).
Step 1: Looking Back
First, I collect stats, like reviewing my overall financials (expenses, income, savings), citations, website visits, etc., and compare them to last year's. I also look at the books I read and the courses I've taken.
Second, I am going through my calendar and project folders (a topic for another newsletter, but I also wrote about it here) and writing down 2-4 highlights for each month.
Third, I go through all the pictures I took this year and pick 1-2 for each month to create a little diary/album I print out (highlighting key events, trips, etc.) to keep a nice and concise summary.
Fourth, I take some time to reflect and think about everything that went well and didn't go so well. And I write down a key lesson for the new year ahead.
Step 2: Looking Forward
After the review has commenced, I take some time to reflect on the main things I want to accomplish this year. This is the most challenging part of the yearly review, and I recommend taking time for that.
Naming 2-3 big things you want to accomplish this year is an excellent exercise for me to stay focused. Over the year, I accumulate a lot of small but interesting projects and responsibilities. This could include maintaining small hobby open-source projects. It's hard to let things go, but sometimes it's important to let things go. Letting things go is the only way to make room for something new.
In that process, I am also planning my curriculum for the year. This usually includes textbooks I want to read and courses I want to take. I am often way too optimistic in terms of what I can actually finish, but it's always good to have a plan.
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Awesome summary for 2022! I really enjoyed you inputing your thoughts for each paper! Already looking forward to 2023 summary 😁
Many thanks for the post, insightful as always. Could you comment on developments in time-series modelling and prediction? Do you think this field has matured? I am especially interested in multivariate time-series modelling but I don't see many progress updates in this field.