

TrAIn Differently: Do We Need Reinforcement Learning with Human Feedback (RLHF)?

This month, deep learning and AI research efforts have been very focused on new or different training paradigms for transformers.
The first section of this newsletter will delve into integrating human feedback into large language models and other research papers that focus on enhancing the training process.
Next, we will review this month's major news headlines and then highlight noteworthy open-source libraries and announcements.
Lastly, I will share my preferred approach for reading research papers while analyzing an article that explores the scaling of vision transformers to accommodate billions of parameters.
PS: If the newsletter appears truncated or clipped, that's because some email providers may truncate longer email messages. In this case, you can access the full article at https://magazine.sebastianraschka.com.
Articles & Trends
Before we dive into some of the newly published papers, let us define the context and problem that has dominated recent research papers: improving the outputs of large language models (LLMs) using human feedback. Currently, reinforcement learning is the most popular paradigm for encoding human preferences or feedback to improve pretrained LLMs further.
Reinforcement learning is a subfield of machine learning that involves training an agent to make decisions based on the rewards it receives from the environment. In reinforcement learning, we have a policy (P) that maps a state (S) to an action (A) that an agent takes, for which we can compute a reward (R). The goal is to find an optimal policy P+ to maximize the accumulated rewards. In language model contexts, we can think of the agent as the LLM and state space containing S as the input tokens and instructions. The possible output tokens represent the action space containing A, and the reward is an alignment score from human feedback. Finally, the policy (P) is essentially a set of rules that the agent uses to determine which action to take in response to a given state.
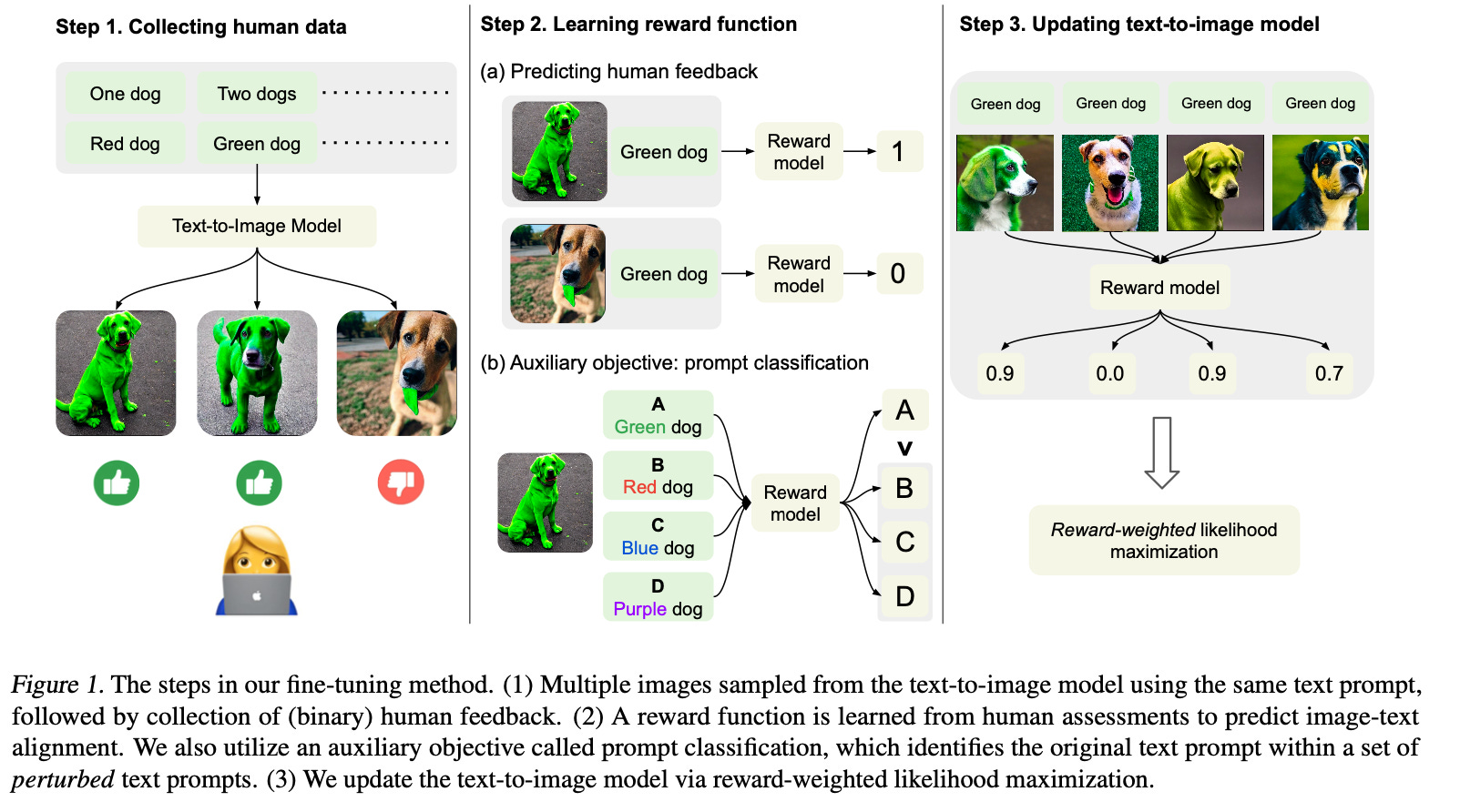
Omitting all the reinforcement jargon terms above, we can summarize the LLM finetuning process based on reinforcement learning with human feedback as shown in the figure below.

Here, the human feedback is used to train the reward model (the training process of the reward model itself is not shown, but it is typically trained in a regular supervised fashion based on the human-assigned labels). The reward model is typically another language model that outputs a preference label, ranking, or score. The Kullback-Leibler divergence loss (KL loss) ensures that the finetuned model does not diverge too much from the original pretrained model. The reward model encodes the human preference and assigns a "content quality" label to the model output. And finally, the proximal policy optimization (the PPO algorithm) updates the pretrained LLM based on the reward signal.
Resources to Learn More About Reinforcement Learning with Human Feedback (RLHF)
While RLHF (reinforcement learning with human feedback) may not completely solve the current issues with LLMs, it is currently considered among the best options available. This is based on the quality of the outputs of current-generation LLMs such as ChatGPT compared to their underlying base models (e.g., GPT-3). And we will likely see more creative ways to apply RLHF to LLMs other domains as well.
Since RLHF will be an influential method in at least the near future I am sharing a five additional research papers below if you want to learn more about RLHF before we dive into the recent reseach developments for this month.
(1) Asynchronous Methods for Deep Reinforcement Learning (2016) introduces policy gradient methods as an alternative to Q-learning in deep learning-based RL.
(2) Proximal Policy Optimization Algorithms (2017) presents a modified proximal policy-based reinforcement learning procedure that is more data-efficient and scalable than the vanilla policy optimization algorithm above.
(3) Fine-Tuning Language Models from Human Preferences (2020) illustrates the concept of PPO and reward learning to pretrained language models including KL regularization to prevent the policy from diverging too far from natural language.
(4) Learning to Summarize from Human Feedback (2022) introduces the popular RLHF three-step procedure:
pretraining GPT-3
finetuning it in a supervised fashion, and
training a reward model also in a supervised fashion. The finetuned model is then trained using this reward model with proximal policy optimization.
This paper also shows that reinforcement learning with proximal policy optimization results in better models than just using regular supervised learning.
(5) Training Language Models to Follow Instructions with Human Feedback (2022), also known as InstructGPT paper) uses a similar three-step procedure for RLHF as above, but instead of summarizing text, it focuses on generating text based on human instructions. Also, it uses a labeler to rank the outputs from best to worst (instead of just a binary comparison between human- and AI-generated texts).
RLHF in practice
If you want to try it out in practice, the trlx repository for PyTorch appears to offer one of the most convenient solutions at the moment.
Should we Use Human Feedback Earlier?
While the InstructGPT paper (and ChatGPT model) demonstrated last year that finetuning pretrained LLMs with human feedback through a reward model improves the model, an interesting question is whether using the reward model during (as opposed to after) pretraining can be even more beneficial.
The answer is yes, it can! In Pretraining Language Models with Human Preferences (Feb 2023), researchers found that incorporating human preferences via a reward model in pretraining stage results in LLMs that produce text that better conforms to human preferences, even when subjected to adversarial attacks.

Do We Need RLHF?
But why do the latest language transformers (LLMs like ChatGPT etc.) use reinforcement learning (RL) for finetuning instead of regular supervised learning (SL) in the first place?
The question naturally arises because the RL paradigm (RLHF, RL with human feedback) involves labels to train a reward model. Why not use these labels directly with SL to finetune the model?
(1) In supervised learning, we usually minimize the difference between true label and model outputs. The labels are the ranking scores of the responses to specific prompts. So, regular SL would tune a model to predict ranks, not generate text responses to the query. In fact, that's how the reward model in InstructGPT is trained as shown below.

(2) Ok, so why don't we reformulate the task into a constrained optimization problem so that we have a combined loss consisting of an "output text loss" and a "reward score" term that we optimize jointly with SL? After all, my colleagues and I have used a similar setup when we proposed semi-adversarial neural networks and PrivacyNet, for example.

Sure, that would work if we want the model to generate correct Q & A pairs. But ChatGPT should have coherent conversations, so we also might prefer cumulative rewards.
(3) Coming back to the token-level loss for SL mentioned in the first point above: in SL, we optimize the loss via cross-entropy. Changing individual words (tokens) due to the sum rule would only have negligible effects on the overall loss of a text passage. But negating a word can totally change the meaning of the text, so cross-entropy is not the best loss function for this kind of problem.
(4) Well, it's not impossible to train the model with SL, and it's been done in the Learning to Summarize from Human Feedback (2020) paper. Based on the results so far, it just doesn't seem to perform that well compared to RL with human feedback. In other words, empirically, RLHF tends to perform better than SL. This is because SL uses a token-level loss (that can be summed or averaged over the text passage), and RL takes the entire text passage, as a whole, into account.
(5) It's not either SL or RLHF; InstructGPT & ChatGPT use both. The combination seems to be key. ChatGPT / the InstructGPT paper first finetunes the model via SL and then further updates it via RL.

Now, while RLHF seems to be a very popular way for finetune the latest large language models, thanks to the success behind ChatGPT, it's of course not the only promising solution moving forward, and SL remains always as an option as well as we just discussed above.
Finetuning LLMs With Supervised Learning
The recent The Wisdom of Hindsight makes Language Models Better Instruction Followers (Feb 2023) shows that supervised approaches to LLM finetuning can indeed work well. Here, researchers propose a relabeling-based supervised approach for finetuning that outperforms RLHF on 12 BigBench tasks.
How does the proposed HIR (Hindsight Instruction Labeling) work? In a nutshell, the method HIR consists of two steps, sampling and training. In the sampling step, prompts and instructions are fed to the LLM to collect the responses. Based on an alignment score, the instruction is relabeled where appropriate in the training phase. Then, the relabeled instructions and the original prompts are used to finetune the LLM. Using this relabeling approach, the researchers effectively turn failure cases (cases where the LLM creates outputs that don't match the original instructions) into useful training data for supervised learning.

Note that this study is not directly comparable to the RLHF work in InstructGPT, for example, since it seems to be using heuristics ("However, as most human-feedback data is hard to collect, we adopt a scripted feedback function ..."). The results of the HIR hindsight approach are still very compelling, though.
"Smaller" Large Language Models
While being "plain" GPT-3 competitors not using RLHF, it's worth mentioning Meta's new LLaMa models announced in LLaMa: Open and Efficient Foundation Language Models (Feb 2023). Since the inference code is open source and model weights are available upon request for research purposes, they could make excellent pretrained baseline models for RLHF experiments. Below are my takeaways from reading the LLaMa paper.
Inspired by Chinchilla's scaling laws paper, the LLaMA paper proposes a set of "small" large language models that outperform GPT-3 (175B) with >10x fewer parameters (13B). And a larger 65B version outperforms PaLM-540B.
In sum, the paper proposes smaller open source models trained on public data that outperform some of the proprietary LLMs created in recent years.

The LLaMA models, which outperform GPT-3, are a welcome alternative to previous open-source models like OPT and BLOOM, which are said to underperform GPT-3. What are some of the methods they used to achieve this performance? They reference (1) pre-normalization, (2) SwiGLU activations, and (3) rotary embeddings. Since these are research models, I would have loved to see ablation studies regarding how much of the performance gains can be attributed to the modifications. This appears to be a missed opportunity.
Moreover, the plots show a steep negative slope when showing the training loss versus the number of training tokens. What would happen if they trained the model for more than 1-2 epochs?

The model repo is available under a GNU GPL v3.0 license on GitHub here: https://github.com/facebookresearch/llama. While it contains the infcode only, the weights are available for research purposes upon filing a request form.
What About Image Models?
Since this section was very language model-focused, I also want to sprinkle in at least one image model. (Another one can be found in the Reading a Research Paper section below). In Aligning Text-to-Image Models using Human Feedback(Feb 2023), researchers propose a finetuning method to align generative models using (surprise, surprise) human feedback.
Overall, the approach is somewhat similar to InstructGPT, except that this is a text-to-image model generating images, not text.
As the figure below summarizes, the researchers gathered human feedback to evaluate how well the model's output aligned with various text prompts. Then, they employ the image-text dataset labeled by humans to train a reward model that can then be used to finetune the text-to-image model.
Headlines
Academia and research
CVPR 2023 decisions are out. This year, CVPR received 9155 submissions (up 12% from 2022), accepting about 25% of the papers. The list of accepted papers may appear here on OpenReview in the next couple of weeks.
The NeurIPS 2023 paper submission deadline is 17 May 2023.
Zeta Alpha compiled a list and analysis of the top 100 most cited AI papers in 2022
ChatGPT
Google announces ChatGPT rival Bard, which is based on LaMDA, the chatbot that sparked a controversy last summer when a Google engineer claimed that it was sentient.
Baidu's stock surges after affirming its release of the ChatGPT-Style "Ernie" Bot.
Microsoft integrates ChatGPT into its BING search engine
Microsoft announces that it [will let companies create their own custom versions of ChatGPT, trained on their own data.
A flood of AI-generated short stories has caused the well-known sci-fi magazine Clarkesworld to halt submissions temporarily.
OpenAI releases official ChatGPT API priced at $0.002 per 1k tokens, claiming to be a 10x reduction in cost over the first iteration of a previous, similar service.
Open Source Highlights
The Pandas 2.0 Release Candidate is Out!
I love Pandas! I've been using it ever since I started doing machine learning more than a decade ago. This month, the new Pandas 2.0 release candidate was just announced. Based on the Pandas 2.0 release notes, the good news is that the focus was mainly on bug fixes and no major API changes. Therefore, Pandas 2.0 should remain largely compatible with our existing code bases.
However, there are also a few exciting new additions next to the bug fixes. For example, there's the new Arrow backend. (Arrow is an open-source and language-agnostic columnar data format to represent data in memory and enable zero-copy sharing of data between processes.)
I took the Arrow backend for a spin, resulting in an impressive performance improvement compared to the original Pandas NumPy backend! In fact, its performance is now very close to Polars, the recently popular Rust-based DataFrame alternative for Python.
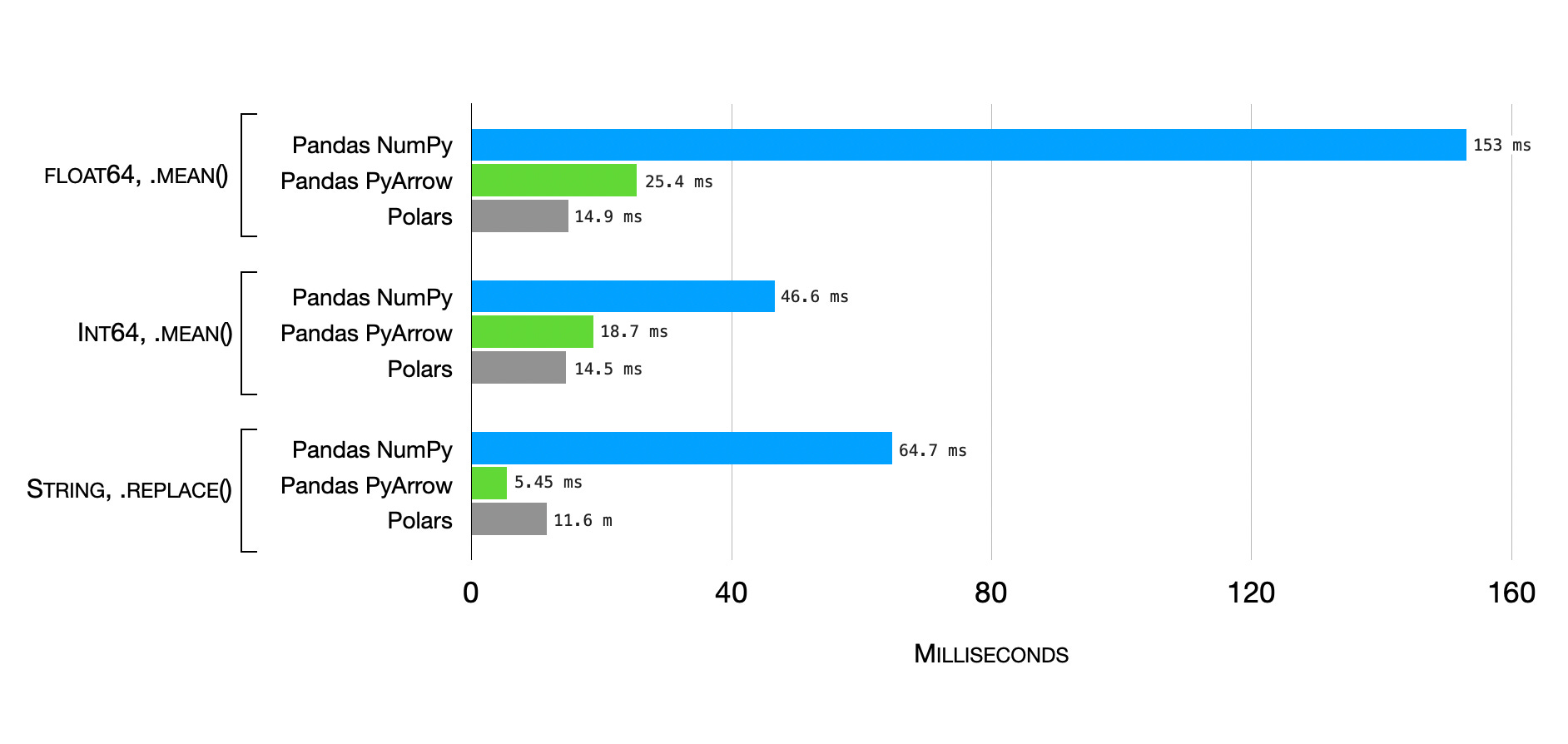
You can install the Pandas 2.0 release candidate as follows:
conda install -c conda-forge/label/pandas_rc pandas==2.0.0rc0
pip install --upgrade --pre pandas==2.0.0rc0
And if you want to try out the new Arrow backend, you can use it via the dtype attribute on a per-DataFrame basis as follows:
import numpy as np
import pandas as pd
import pyarrow as pa
numbers = np.random.rand(1_000_000, 100)
df = pd.DataFrame(numbers, dtype="float64[pyarrow]")
Alternatively, if you want to use Arrow as the backend by default, use the following command in your Python session or script:
pd.options.mode.dtype_backend = "pyarrow"
PicoGPT -- A tiny implementation of GPT in NumPy
PicoGPT is a tiny implementation of GPT in 60 lines of code using NumPy -- it's meant for educational purposes of course. Moreover, the repository contains code to load GPT-2 weights and actually use it.
Open source implementation for LLaMA-based ChatGPT training
As mentioned earlier, Meta recently released LLaMA, a collection of "small" large language models (up to 65 billion parameters) that outperform GPT-3. ChatLLaMA adds an Reinforcement Learning with Human Feedback (RLHF) component for these models based on pre-trained LLaMA models.
JupyterLab 3.6 was released
The JupyterLab 3.6 release features performance improvements for rendering times and tab switching. There is also a notification popup window now, notifying you about new JupyterLab updates in the future. And the highlight of this release is a rework of the real-time collaboration feature.
Lazy Predict
Not a new library, but something fun I discovered this month: Lazy predict runs all major classification (or regression) implemented in scikit-learn on a given target dataset in 2 lines of code. This is very useful when working with tabular datasets and you want to get a quick predictive performance baseline.

Notable Quote
"Choose the evaluation metric before making modeling choices. Don’t use metrics like AIC or BIC that are based on model assumptions."
— Christoph Molnar
I like this quote because an evaluation metric doesn't need, or shouldn't, equal the optimization metric. Moreover, we can think of our machine learning algorithms and models as replaceable parts in a (machine learning) system. Therefore, it makes sense to define evaluation metrics in a model-agnostic way to allow model comparisons and upgrades.
The Akaike information criterion (AIC) and Bayesian information criterion (BIC) are applied to models with a countable number of parameters and a likelihood function. So, if we use an XGBoost classifier, this becomes a bit tricky. What is the number of parameters in XGBoost? Furthermore, in XGBoost, our primary objective may be to maximize the accuracy of the predictions on new data rather than to obtain a statistical model that accurately represents the underlying data-generating process.
Study & Productivity Tips: Reading A Research Paper
Since I started Ahead of AI, several people have asked for tips for reading research papers. Since reaching a critical threshold of requests, I thought sharing my approach would be a good idea.
But a few disclaimers first. There isn't a universally best approach to reading papers. It all depends on our knowledge level and expertise in the given field and what we want to get out of an article. For example, we want to read papers differently when reviewing a paper versus skimming a paper to get recommendations for hyperparameter settings.
Another important tip is don't be a completionist! I usually start by reading the abstract first since a well-written abstract offers a concise summary of what the paper is about, what problem it solves, and its main takeaways. If the abstract doesn't sound promising and indicates that reading the article isn't worth the time commitment, it's okay to skip it and read something else instead.
My approach in short
First, as I mentioned above, I start with the abstract.
Then, I go over all the figures -- looking at the figures and reading the captions.
Next, I do the same thing with the tables.
After getting this brief overview, I skim through the conclusion section.
The four steps above help me to become aware of a paper's scope and structure and the main contents and takeaways. Only some figures and tables may make sense at this point, but I have a rough mental model of what to look out for when reading the paper in more detail.
After familiarizing myself with the rough structure of the paper as described above, I would proceed by reading the article sequentially. I annotate and underline critical aspects, but I force myself to finish reading the paper before getting distracted by following up on references and looking up information online.
After this first pass-through, I usually summarize the paper based on my underlined phrases and notes. If I wanted to get more out of the article, I would also look up things I needed clarification on. I would follow up on or bookmark individual interesting and important references, and I would read through the appendix.
A concrete example
Since this newsletter was already very large language model-heavy, let us pick a computer vision paper and illustrate my approach described above using a concrete example: Scaling Vision Transformers to 22 Billion Parameters (Feb 2023).

1. The abstract
Based on the abstract, we learn that this is a paper about a 22B-parameter vision transformer ViT -- the previous ViTs for dense tasks were only up to 4 billion parameters in size. (What does "dense" mean? Something we can annotate and research later.) Furthermore, next to proposing the architecture, one of the big takeaways of this paper is that scaling the size of the ViT improves predictive performance (even if we train a linear model on top of the output embeddings) and alignment to human perception and fairness.
2. The figures
Next, let's look at the figures.
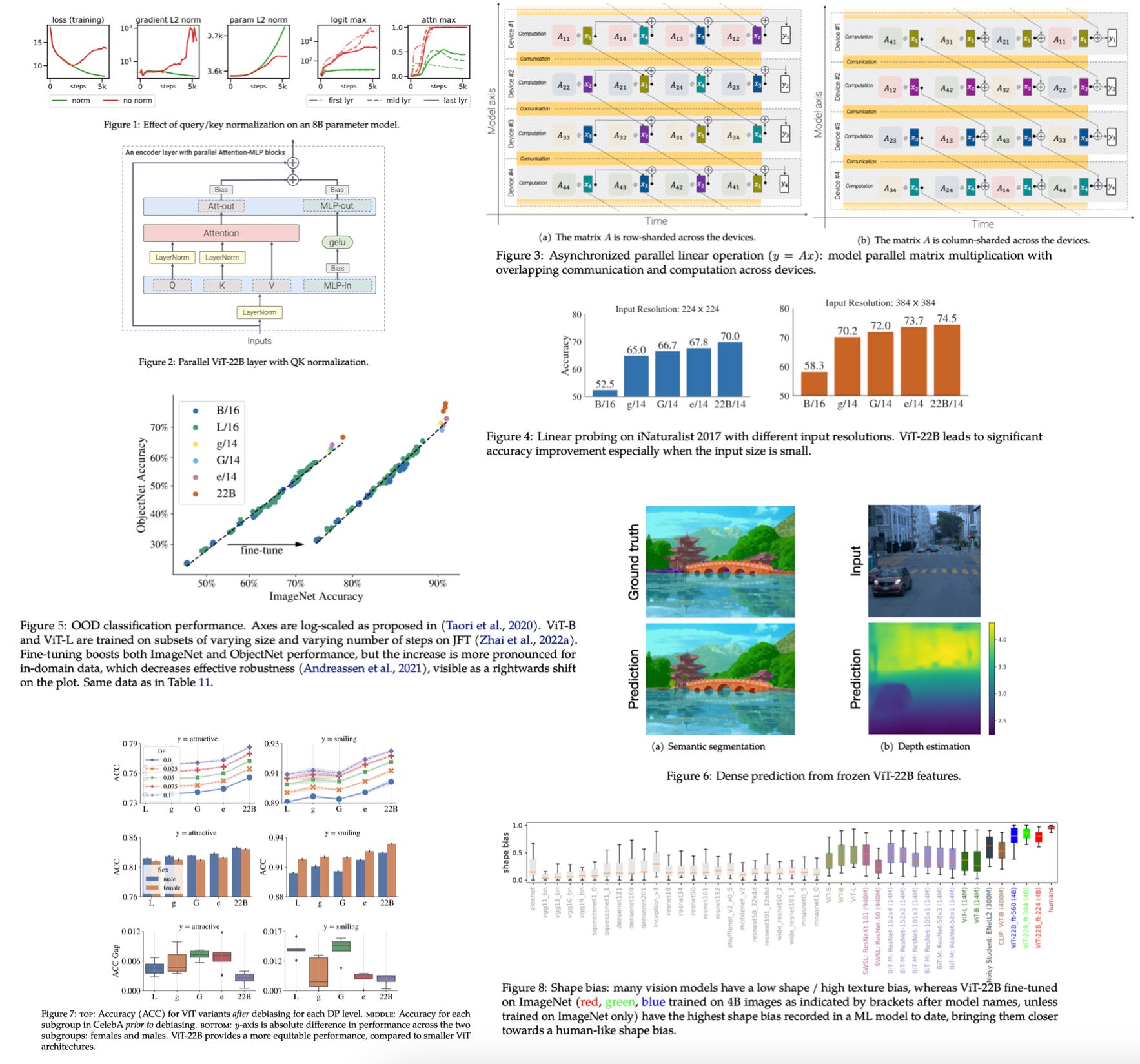
Figure 1 shows that the researchers applied a "trick" to improve the training, namely normalizing the keys and queries.
If we are familiar with regular ViTs, Figure 2 reveals that the researchers propose a slightly new architecture design where the attention and multilayer perceptron (MLP) layers seem to be fused -- another trick to improve predictive or computational performance?
Figure 3 shows that they used tensor sharding to improve computational performance and avoid memory bottlenecks. If you are curious, I covered this in the multi-GPU paradigm question in my Machine Learning Q and AI book -- it's included in the free preview.
Figure 4 refers to linear probing, which likely means training a linear layer on the output embeddings. Again, we can see that ViTs perform better with increasing model sizes. Interestingly, this is more so for smaller images (224x224 pixels) than larger images (384x384 pixels) -- why?
Figure 5 shows that large ViTs are better at image classification and object detection. Also, finetuning benefits these models.
Figure 6 refers to "dense prediction" -- remember this term from the Abstract? Based on the pictures in this figure, we learn that dense prediction refers to a pixel-wise prediction, for example, semantic segmentation and depth estimation.
Figure 7 talks about "debiasing" for different DP levels. We have yet to find out what DP levels are, yet. But based on the plots, all ViTs show inequitable performance between the two sexes they analyzed (male and female). However, the larger 22B ViT seems less inequitable than the smaller ViTs.
Figure 8 shows that the 22B ViT has the highest shape bias among all ViTs analyzed. However, the researchers also mention that the shape bias is closest to the ones of humans, so we may assume a high shape bias is a good thing.
Finally, Figure 9 shows different ViTs in an accuracy vs. calibration ECE plot, telling us that the 22B ViTs improve Pareto frontiers without temperature rescaling. Pareto frontiers and ECEs may be something to look up and learn about later.
As we can see, we can already learn a lot about the proposed method, the experiments, and the takeaways of this paper just from skimming over the figures.
3. Tables
Next, I would repeat the same procedure with the tables: I briefly skim over the tables and table captions from beginning to end. In this case, Table 1 gives us more information about the hyperparameters and exact sizes of the different models being proposed and compared.
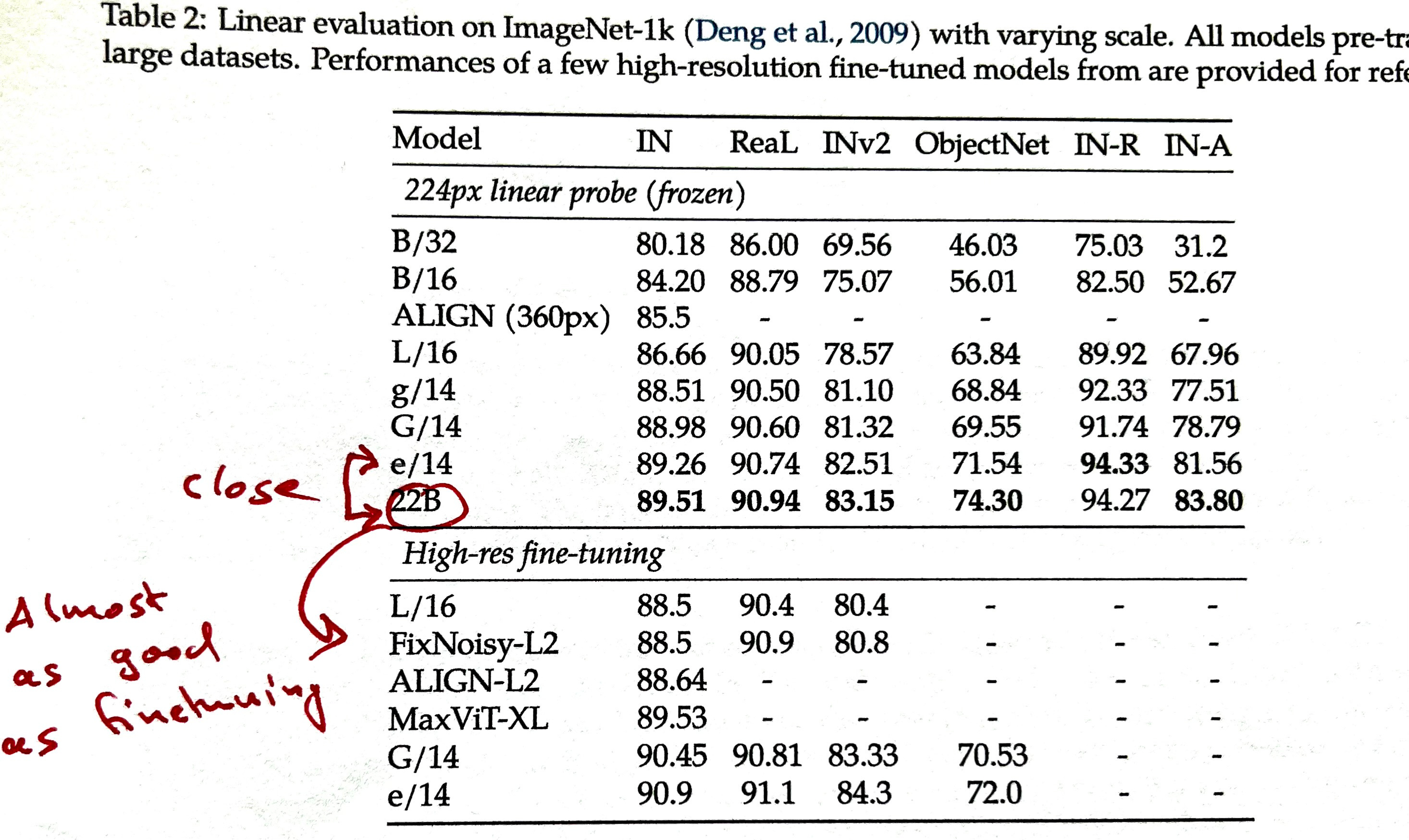
Table 2 gives us some interesting insights: it tells us that there are diminishing returns when training a linear layer on the embeddings of a pretrained model. But the performance of the linear layer is almost as good as the performance of other finetuned models (note that using a linear layer on a pretrained, frozen model is typically much cheaper than finetuning a model.)
From Table 3, we learn that the proposed model is also great in a zero-shot transfer context. Tables 4 and 5 tell us that the 22B ViT also outperforms other methods on few-shot semantic segmentation and monocular depth estimation. Table 6 tells us that the model performs better on video classification, and Table 7 tells us that the ViT scores best on a reliability benchmark. Lastly, Table 8 shows that we can also distill the 22B model into a smaller model while still outperforming distilled references (later, the text reveals that we are talking about a slightly smaller 16B version).
The tables mostly reveal all the tasks the proposed 22B ViT model can do. And the proposed model outperforms smaller ViTs across the bench. Hence, a takeaway from this paper so far is: the larger the ViT, the better.
4. Conclusions
Now that we are familiar with the main structure of the paper, I find it helpful to read over the conclusions section, which is usually short. In this case, the conclusion summarizes what we've just learned from looking at the figures and tables. Namely, the larger ViT performs better than the smaller predecessors on a variety of tasks. Also, they applied a few tricks to improve computational performance.
5. A full read-through
Now it's time for a complete read-through. I usually read the paper from beginning to end at this point to learn more about the details of how they implemented the model and designed the experiments. For example, we learn that they implemented three techniques to improve training efficiency and stability: (1) parallel layers, (2) query/key normalization, and (3) omission of bias vectors. For example, in the context of the parallel layers, they fused the matrix multiplication in the attention heads with the linear layer of the multilayer perceptron part, which improved the computational performance by 15% during training without impacting the modeling performance, and so forth. (I am skipping a detailed discussion of the paper for space reasons.)
6. Wrapping and following up
After reading the paper in detail, I would go through my notes and underlines key points to write a short summary of the paper that I keep in my note collection. I usually rarely refer back to these notes, but writing a summary is a good brain exercise to improve long-term recall. Also, I sometimes make a few entries in Anki about general things I want to remember.

This is also an excellent stage to follow up on confusing or unclear aspects. For example, we may want to do some background research on what the researchers mean by shape bias. For example, a web search reveals, "Shape bias is the fraction of correct decisions based on object shape." I.e., shape bias is the ability of a model to predict by relying only on the object's shape. And to check for shape bias, we have to design experiments to remove other information carefully, for example, color and texture, from the images.
Finally, if we are really interested in understanding all the aspects of the paper and answering some open questions looming in our heads. In that case, it's a good idea to read the appendix now. (I usually skim over the appendix at least, but since it is almost 20 pages long, I am skipping it in the discussion here for brevity.)
Preferred paper-reading formats
When I want to read papers very carefully and soak up all the details, I usually print the paper so that I can read it away from my computer, which allows me to focus better. I do this only for ~5% of the papers I read. For 70% of the papers, I export the PDF to my e-reader, which I love -- unfortunately, it doesn't have color, though, which can sometimes (but rarely) be annoying for specific figures. Then, 25% of the time, when I quickly read through a paper, I read the PDF on my computer.
I hope this was helpful, and please feel free to ask questions in the comments section!
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Thanks for the post. I do the same with most of my note taking. I rarely revisit my notes but taking them is so helpful for organizing my thoughts and understanding of the topics.
Hi Dr. Raschka,
Do you read on an ipad with an apple pencil? According to me , it is not harmful because reading on an ipad is leading to unconcentration. Reading on macbook and taking notes on a txt file is another way, which may be better than reading on an ipad. But, i still not give a decision for where should I store all my notes for reading later ? I think the best is reading on a printed paper directly