

Insights from Large-Scale LLM Training Runs
And the Latest Open Source LLMs and Datasets

The theme of this month's issue is to organize the almost overwhelming number of large language models (LLM) projects and datasets shared in the last couple of weeks. In addition to highlighting insights from large training runs, I will also share several curated lists to keep track of it all.
Table of Contents
Articles & Trends
With so many research papers coming out this month, it's hard to pick a few favorites for a closer discussion. I personally prefer papers that offer extra insights rather than simply presenting more powerful models. In light of this, one paper that captured my attention was Eleuther AI's Pythia paper.
Pythia — Insights from Large-Scale Training Runs
The open source Pythia suite of LLM models is a really interesting alternative to other autoregressive decoder-style (aka GPT-like) models.
The accompanying Pythia: A Suite for Analyzing Large Language Models Across Training and Scale paper recently revealed some interesting insights into the training mechanics alongside introducing various LLMs ranging from 70M to 12B parameters.
Here are some insights and takeaways from the paper:
Does training on duplicated data (i.e., training for >1 epoch) make a difference? It turns out that deduplication does not benefit or hurt performance.
Does training order influence memorization? Unfortunately, it turns out that it does not. "Unfortunately," because if this was true, we could mitigate undesirable verbatim memorization issues by reordering the training data.
Does pretrained term frequency influence task performance? Yes, few-shot accuracy tends to be higher for terms that occur more frequently.
Doubling the batch size halves the training time but doesn't hurt convergence.
The Pythia model architecture is similar to GPT-3 but includes some improvements, for example, Flash Attention (like LLaMA) and Rotary Positional Embeddings (like PaLM). Pythia was trained on the Pile dataset (an 800GB dataset of diverse texts) for 300 B tokens (~1 epoch on regular Pile, ~1.5 epochs on deduplicated Pile).
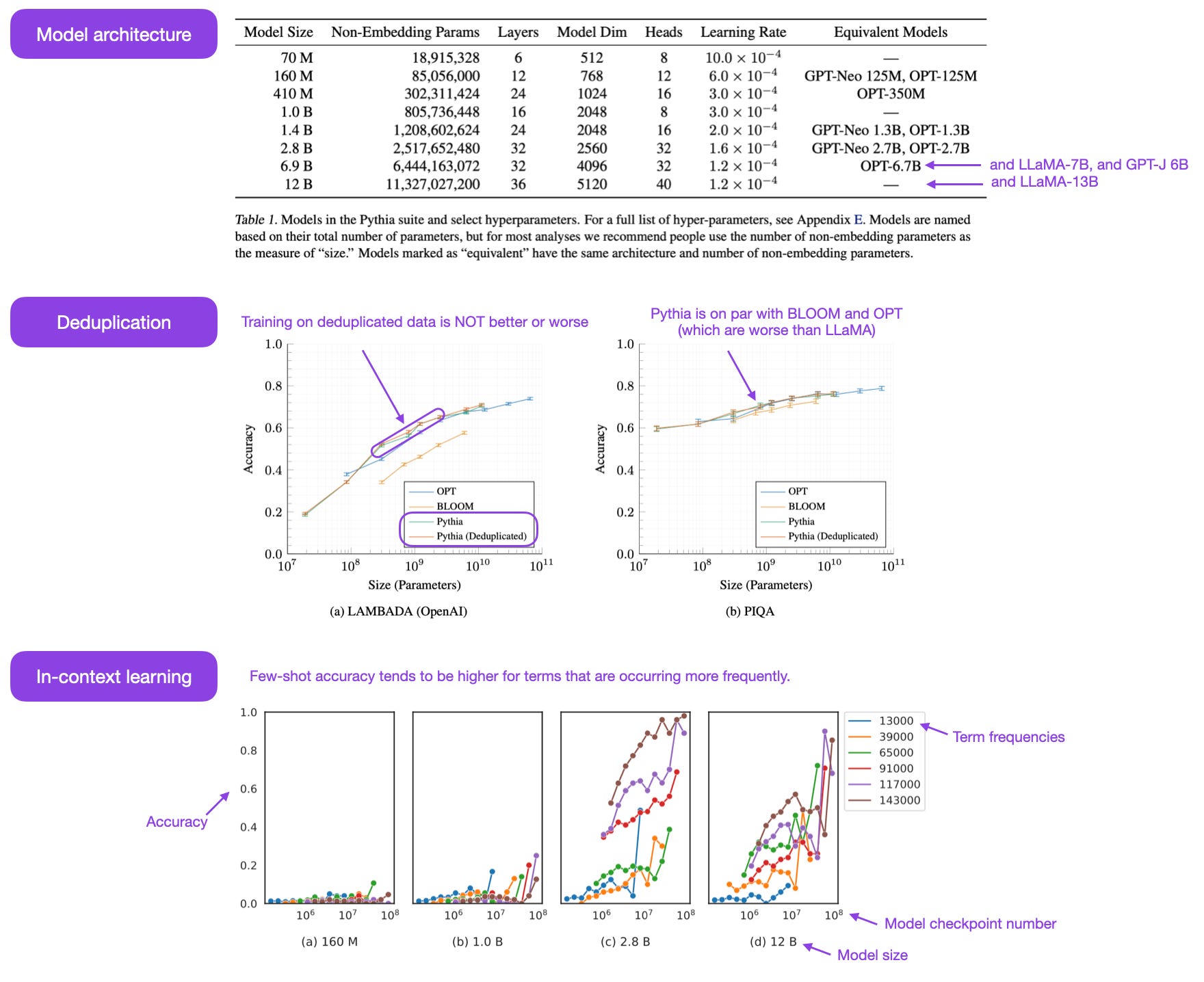
By the way, the recent instruction-finetuned open-source Dolly v2 LLM* model used Pythia as the base (foundation) model, and I expect more models building on this in the future.
(*Dolly v2 is a finetuned Pythia 12B parameter model using the databricks-dolly-15k dataset to replicate the InstructGPT paper / ChatGPT. More on this dataset below.)
Open Source Data
Last month was a particularly exciting month for open-source AI with several open-source implementations of large language models (LLMs). Now we are also seeing a big wave of open-source datasets! Databricks Dolly 15k and Open-Assistant Conversations for instruction finetuning, and RedPajama for pretraining. This is particularly commendable because data collection and cleaning make up ~90% of a real-world machine learning project, but no one likes doing this work.
RedPajama Dataset for Pretraining
The RedPajama dataset is an open-source dataset for pretraining LLMs similar to LLaMA Meta's state-of-the-art LLaMA model. The goal of this project is to create a capable open-source competitor to the most popular LLMs, which are currently closed commercial models or only partially open. (PS: The name RedPajama is inspired by the children book Llama Llama Red Pajama.)
The large bulk of the dataset consists of CommonCrawl, which is filtered for websites in English language, but the Wikipedia articles cover 20 different languages.

Databricks-Dolly-15
Databricks-dolly-15k is a dataset for LLM finetuning that features >15,000 instruction-pairs written by thousands of DataBricks employees (similar to those used to train systems like InstructGPT and ChatGPT).
OpenAssistant Conversations
OpenAssistant Conversations is another dataset for finetuning pretraining LLMs on a collection of ChatGPT assistant-like dialogues that have been created and annotated by humans, encompassing 161,443 messages in 35 diverse languages, along with 461,292 quality assessments. These are organized in more than 10,000 thoroughly annotated conversation trees.
LongForm Dataset
The LongForm: Optimizing Instruction Tuning for Long Text Generation with Corpus Extraction paper introduces a collection of human-authored documents from established corpora like C4 and Wikipedia along with instructions for these documents to create a instruction-tuning dataset suitable for long text generation.
Alpaca Libre
The Alpaca Libre project aims to reproduce the Alpaca project with 100k+ MIT-licensed demonstrations from Anthropics HH-RLHF repo converted into an "Alpaca compatible format".
Open Data And Copyrights
Note that the data use of LLMs is still a hot topic of discussion, as summarized by the following articles below:
An MIT Technology Review article outlines how OpenAI may have been breaking data protection laws
EU lawmakers draft an AI Act document that includes requiring companies to disclose copyrighted material used for training
Lastly, an interesting tidbit about the Pile dataset that the Pythia model mentioned above was trained on: according to a Twitter thread by a researcher at Eleuther AI, the Pile is actually unlicensed but the Eleuther AI researcher says it may be compliant with copyright law within the US.
Extending Open-Source Datasets
Instruction finetuning is how we get from GPT-3-like pretrained base models to more capable LLMs like ChatGPT. And open-source human-generated instruction datasets like databricks-dolly-15k (above) can help make this possible. But how do we scale this further? Possibly without collecting additional data? One way is bootstrapping an LLM off its own generations.
While the Self-Instruct method was introduced five months ago (old by today's standards), it's still a super interesting approach to highlight since it's an almost annotation-free way to align pretrained LLMs with instructions.
How does this work? In a nutshell, it's a 4-step process:
Seed task pool with a set of human-written instructions (175 in this case) and sample instructions;
Use a pretrained LLM (like GPT-3) to determine the task category;
Given the new instruction, let a pretrained LLM generate the response;
Collect, prune, and filter the responses before adding it to the task pool.

In practice, this works relatively well based on the ROUGE scores. For example, a Self-Instruct-finetuned LLM outperforms the GPT-3 base LLM (1) and can compete with an LLM pretrained on a large human-written instruction set (2). And self-instruct can also benefit LLMs that were already finetuned on human instructions (3).
But of course, the gold standard for evaluating LLMs is to ask human raters. Based on human evaluation, Self-Instruct outperforms base LLM, and LLMs trained on human instruction datasets in supervised fashion (SuperNI, T0 Trainer). But interestingly, Self-Instruct does not outperform methods trained via reinforcement learning with human feedback (RLHF)
Human-generated vs synthetic training data
Which is more promising, human-generated instruction datasets or self-instruct datasets? I vote for both. Why not start with a human-generated instruction dataset like the 15k instructions from databricks-dolly-15k and then scale this with self-instruct? For example, the recent Synthetic Data from Diffusion Models Improves ImageNet Classification paper showed that combining real image training sets with AI-generated images can improve model performance. Wouldn't be interesting to investigate whether this is true for text data?
A recent example that goes in this direction is the Better Language Models of Code through Self-Improvement paper. The researchers found that a pretrained LLM can improve code-generation tasks if it utilizes its own generated data.
Less is more?
Also, in addition to pretraining and finetuning models on increasingly larger datasets, how about improving efficiency on smaller datasets? In the just-released Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes paper, researchers propose a distillation mechanism to curate task-specific smaller models that exceed the performance of standard finetuning with less training data.

Keeping Track of Open Source LLMs
The number of open-source LLMs is exploding, which is, on the one hand, a very nice development (versus gating the models via paid APIs). On the other hand, however, it can sometimes be tricky to keep track of it all. Below are four resources that provide different summaries of the most relevant models, including their relationship, the underlying datasets, and the various licensing information.
(On an interesting side note, LAION and other prominent researchers shared an open letter ("A Call To Protect Open-Source AI In Europe") intended for the European Parliament.)
Let's start with the Ecosystems Graphs website based on the paper Ecosystem Graphs: The Social Footprint of Foundation Models, which features a table (screenshot below) and an interactive dependency graph (not shown).
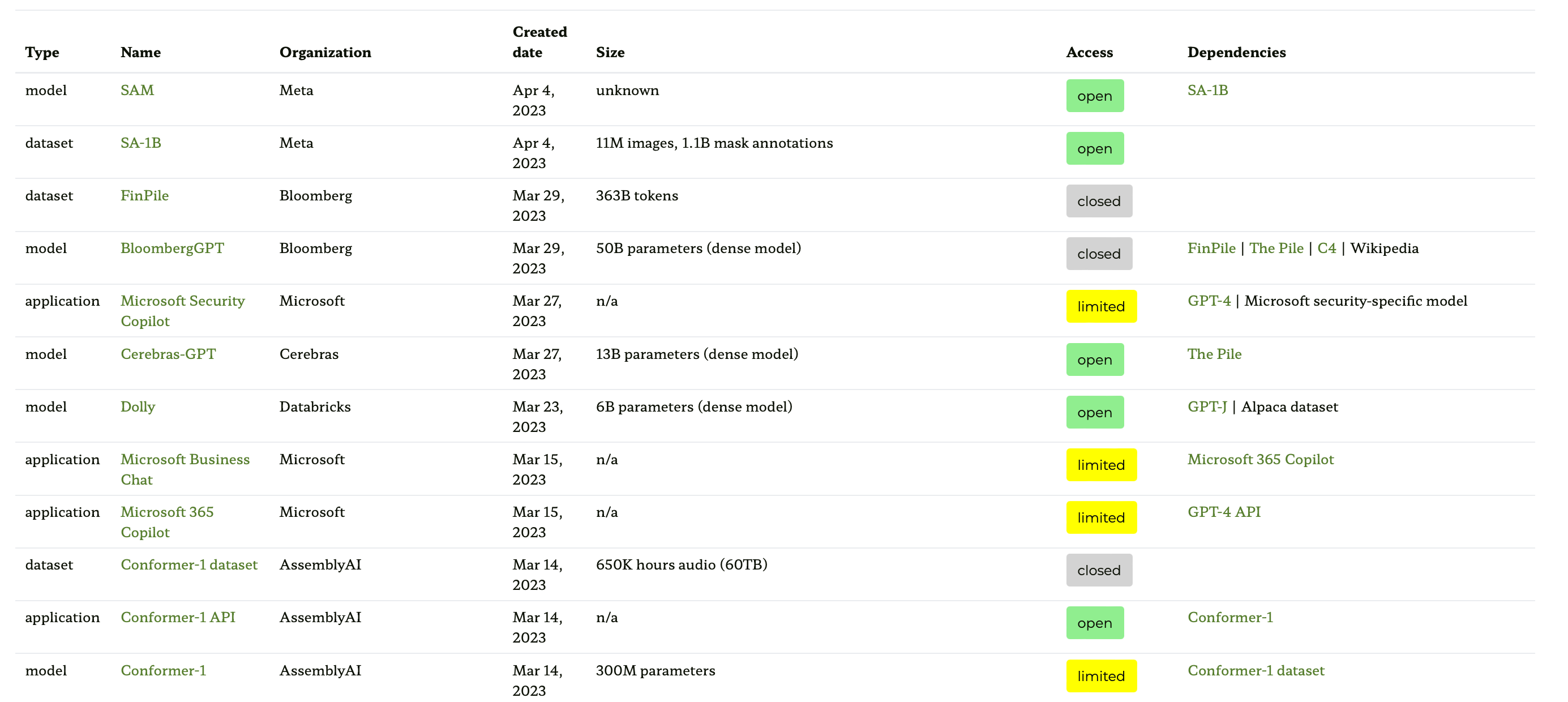
This ecosystems graph has the most comprehensive listing I've seen so far. But since many less popular LLMs are included, it can appear a bit cluttered. Also, based on checking the accompanying GitHub repo, it has been updated for at least a month. Also, it is unclear if newer models will be added (but this is true for the two more recent resources below as well).
The second resource is the beautifully drawn evolutionary tree from the recent Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond paper, which focuses on the most popular LLMs and their relationship.
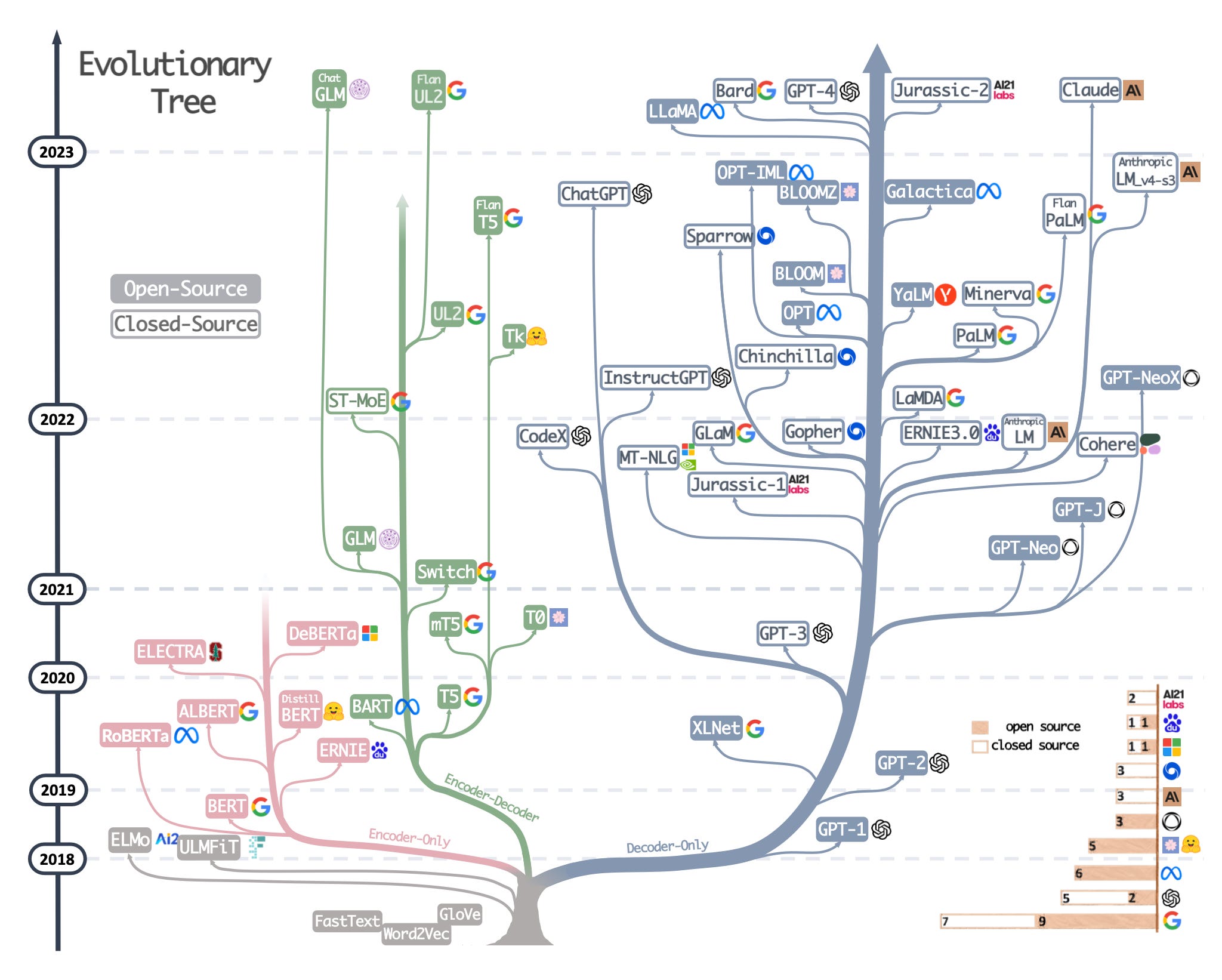
While the LLM evolutionary is a very nice and very clear visualization, there are a few small caveats. For example, it's unclear why the root doesn't start with the original transformer architecture from Attention Is All You Need. Also, the "open source" labels are not super accurate. For example, LLaMA is listed as open source, but the weights are unavailable under an open-source license (only the inference code is).
The third resource is a table by my colleague Daniela Dapena from the blog post The Ultimate Battle of Language Models: Lit-LLaMA vs GPT3.5 vs Bloom vs …

While this table is a bit smaller than the other resources, what's nice about this resource is that it includes the model sizes and licensing information, which has useful practical implications if you plan to adopt these models for any of your projects.
Fourth, the LLaMA-Cult-and-More overview table provides additional information about the finetuning methods as well as hardware costs.

Next, it would be nice to somehow include modeling performance information in these tables somehow, but this is a whole other can of worms, since evaluating LLMs efficiently is not very straightforward ...
Finetuning Multimodal LLMs with LLaMA-Adapter V2
Remember LLaMA-Adapter as a nice parameter-efficient finetuning technique for large language models (LLMs) last month? Since I also predicted that we'd be seeing more multi-modal LLM models this month, we have to talk about the freshly released "LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model"!
As a brief recap, what's LLaMA-Adapter, and how does it work? LLaMA-Adapter is a parameter-efficient LLM finetuning technique that modifies the first few transformer blocks and introduces a gating mechanism to stabilize the training.
Using the LLaMA-Adapter approach, researchers were able to finetune a 7 billion parameter LLaMA model in only 1 hour (using eight A100 GPUs) on 52k instruction pairs. Although only the newly added 1.2 M parameters (the adapter layers) were tuned, the 7B LLaMA model remains frozen.
The focus of LLaMA-Adapter V2 is multimodality, that is, building a visual instruction model that can also talk about image inputs. (The original V1 could also receive image tokens (together with text tokens), but this aspect remained underexplored.)
They added three main tricks from V1 to V2 to improve their adapter approach.
Early fusion of visual knowledge: Instead of fusing visual and adapted prompts in each adapted layer, they now concatenate the visual tokens with the word tokens in the first transformer block.
Using more parameters: they unfreeze all normalization layers, and they add both bias units and scale factors to each linear layer in the transformer blocks.
Joint training with disjoined parameters: for image-text captioning data, they only train the visual projection layers; for instruction-following data, they only train the adaption layers (and newly added parameters mentioned above)
LLaMA V2 (14 M) comes with a few more parameters than LLaMA V1 (1.2 M), but it is still lightweight, comprising only 0.02% of the total parameters of 65 B LLaMA model size.
What's particularly impressive is that by finetuning only 14 M parameters of the 65B LLaMA model, the finetuned LLaMA-Adapter V2 model matches ChatGPT in performance (using a GPT-4 model for the evaluation). It also outperforms the 13B Vicuna model, which uses a full-finetuning approach (updating all 13B parameters).
Unfortunately, the V2 paper omits the computational performance benchmarks included in the V1 paper, but we can assume that V2 is still much faster than full finetuning.

Research Highlights in Two Sentences
Due to the length of this newsletter article, I decided to move the 17 articles that I hand-picked and summarized for this section I summarized to a separate post, scheduled to go out next week instead. And maybe I’ll even add a few more until then. Stay tuned!
Open Source Highlights
Lit-LLaMA improvements
At Lightning AI, we are maintaining the Lit-LLaMA repository that offers a simpler, more readable open-source reimplementation of the popular LLaMA model along with several finetuning methods such as low-rank adaptation and LLaMA-Adapter, quantization, and more.
The recent additions to this repository include the following:
A pretraining script for the abovementioned RedPajama dataset, leveraging a new optimized
PackedDatasetformat -- this gets up to 2.6k tokens/sec/GPU on an A100 GPU.Lit-LLaMA can now optionally load the OpenLLaMA weights that have been recently released under an Apache 2.0 (trained on 300B tokens so far).
Integration of the EleutherAI LM Evaluation Harness for model evaluation mentioned earlier.
A new related repository, Lit-StableLM to load both Stability AI's StableLM models as well as the EleutherAI Pythia models discussed at the beginning of this newsletter.
Other open-source LLMs
It's impossible to list them all, but some of the notable open-source LLMs and chatbots launched this month include Open-Assistant, Baize, StableVicuna, ColossalChat, Mosaic's MPT, and more. Moreover, below are two multimodal LLMs that are particularly interesting.
OpenFlamingo
OpenFlamingo is an open-source reproduction of Google Deepmind's Flamingo model released last year. OpenFlamingo aims to offer multimodal image-reasoning capabilities for LLMs where people are able to interleave text and image inputs.
MiniGPT-4
MiniGPT-4 is another open-source model with vision-langauge capabilities. It's based on a frozen visual encoder from BLIP-27with a frozen Vicuna LLM.

NeMo Guardrails
With all these new LLMs coming up, a lot of companies are wondering about how and if to deploy them. Especially when it comes to safety. There is no good solution, yet, but there's at least one more promising bandaid: Nvidia open-sourced a toolkit to address the hallucination issue of LLMs.
In a nutshell, how it works is that this method uses a database linking to hardcoded prompts, which have to be manually curated. Then, if a user enters a prompt, the prompt is first matched to the most similar entry in that database. And the Database then returns a hardcoded prompt, which is, in turn, passed on to the LLM. So, if someone carefully tests the hardcoded prompts, one can ensure that the interaction does not diverge from permissible topics and so on.

It is an interesting but not groundbreaking approach as it does not give the LLM better or new capabilities. It merely restricts how far a user can interact with an LLM. Still, it might be a viable approach before researchers find alternative ways to mitigate hallucination issues and toxic behavior in LLMs.
The guardrails approach could also be combined with other alignment techniques, such as the popular Reinforcement Learning with Human Feedback training paradigm that I covered in a previous issue of Ahead of AI.
Consistency Models
Wouldn't it be nice to talk about interesting models other than LLMs? OpenAI finally open-sourced the code for their consistency models: https://github.com/openai/consistency_models.
Consistency models are considered to be a viable, efficient alternative to diffusion models. More info in the Consistency Models paper.
New Deep Learning Fundamentals Units on Computer Vision and Large Language Models
Two new units of my free Deep Learning Fundamentals course just went live in the last couple of weeks.
Unit 7 covers computer vision models: how to work with image data, train convolutional networks, use transfer learning, and pretrain models with self-supervised learning.
Unit 8 covers large language models and natural language processing:
how to encode text data
understanding self-attention from the ground up
and finetuning large language models.
Of course, both lectures include many code examples and walkthroughs using PyTorch. The course is entirely free, and the videos are relatively short and bite-sized. I hope you find them useful!

Notable Quote
"I think we're at the end of the era where it's going to be these, like, giant, giant models. [...] We'll make them better in other ways."
-- Sam Altman (CEO of OpenAI) in a Wired interview
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Thank you Sebastian for the curated list. I am getting started on LLM fine tuning and this is a great way to get overview of available datasets. Your summarization helps a ton.
Cheers
Thank you very much Sebastian. It was a great recap. I've taken lots of notes and saved many links from this article to dig even deeper.