

Direct-Preference Optimization for Human Feedback and More
AI Researc

This article is a compilation of 23 AI research highlights, handpicked and summarized. A lot of exciting developments are currently happening in the fields of natural language processing and computer vision!
In addition, if you are curious about last month's highlights, you can find them here:

Large Language Models
Direct Preference Optimization: Your Language Model is Secretly a Reward Model (https://arxiv.org/abs/2305.18290, 29 May 2023)
Direct Preference Optimization (DPO) is a new alternative to reinforcement learning with human feedback (RLHF) with Proximal Policy Optimization (PPO), which is used for instruction-finetuning models like ChatGPT. Here, the researchers show that the cross-entropy loss for fitting the reward model in RLHF can be used directly to finetune the LLM. According to their benchmarks, it's more efficient to use DPO and often also preferred over RLHF/PPO in terms of response quality.

LIMA: Less Is More for Alignment (https://arxiv.org/abs/2305.11206, 18 May 2023)
Researchers carefully curated 1000 instruction pairs to finetune a 65B LLaMA model, called LIMA, in a supervised fashion. Note that other finetuned LLaMA models like Alpaca were trained on 52,000 automatically generated instruction pairs. Impressively, LIMA surpassed models that were trained with reinforcement learning with human feedback (RLHF) techniques, such as ChatGPT/GPT 3.5.

QLoRA: Efficient Finetuning of Quantized LLMs (https://arxiv.org/abs/2305.14314, 23 May 2023)
QLoRA (quantized low-rank adaptation) is the newest entry in the parameter-efficient LLM finetuning category. QLoRA reduces the memory requirements of a 65B LLaMA model such that it fits onto a single 48 GB GPU (like an A100). The resulting 65B Guanaco model, from quantized 4-bit training, maintains full 16-bit finetuning task performance, reaching 99.3% of the ChatGPT performance after only 24h of finetuning.

SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression (https://arxiv.org/abs/2306.03078, 5 Jun 2023)
Quantizing LLMs down to 4 bits is currently the only way to use these on single GPUs or laptops, but it comes at an accuracy cost. The proposed Sparse-Quantized Representation (SpQR) method offers a new near-lossless alternative. The idea is to keep certain outlier weights in higher precision, which reduces accuracy losses to less than 1% while achieving almost identical model compression as int4 quantization.

To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis (https://arxiv.org/abs/2305.13230, 22 May 2023)
It turns out that high-quality text data on the internet is growing slower than required for scaling LLMs. So, what happens if we train LLMs for multiple epochs? The result is that training for multiple epochs leads to overfitting and most regularization techniques can't help with this issue (except dropout).

DoReMi: Optimizing Data Mixtures Speeds Up Language Model Pretraining (https://arxiv.org/abs/2305.10429, 17 May 2023)
In this paper, the researchers ask the question of whether the relative proportions of Wikipedia articles, books, and websites in the pretraining data noticeably affect LLM performance. To answer this question, they train a proxy model to derive the relative domain weights for training the larger target LLM. It turns out that this can improve downstream task accuracy by 6.5%, and models can reach the baseline accuracy 2.6x faster when pretraining on reweighted The Pile dataset.

The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only (https://arxiv.org/abs/2306.01116, 1 Jun 2023)
In this paper, the researchers find that training LLMs on deduplicated web data can improve the zero-shot performance of LLMs to match models trained on curated datasets. In this case, using 100% web data for pretraining, the resulting Falcon 7B model matches the performance of the 8B PaLM model, which only has 18% web data (the rest is made up of higher-quality data, including books). The proposed RefinedWeb dataset the researchers developed here is a filtered and deduplicated version of CommonCrawl (~11% of its original size).

The False Promise of Imitating Proprietary LLMs (https://arxiv.org/abs/2305.15717, 25 May 2023)
In recent months, it's become common practice to finetune LLMs on data derived from other LLMs, such as ChatGPT. In this recent study, researchers found that crowd workers rate these so-called imitation models highly. But it turns out that these imitation models only tend to mimic the style of the upstream LLMs on whose data they were trained on, not their factuality.

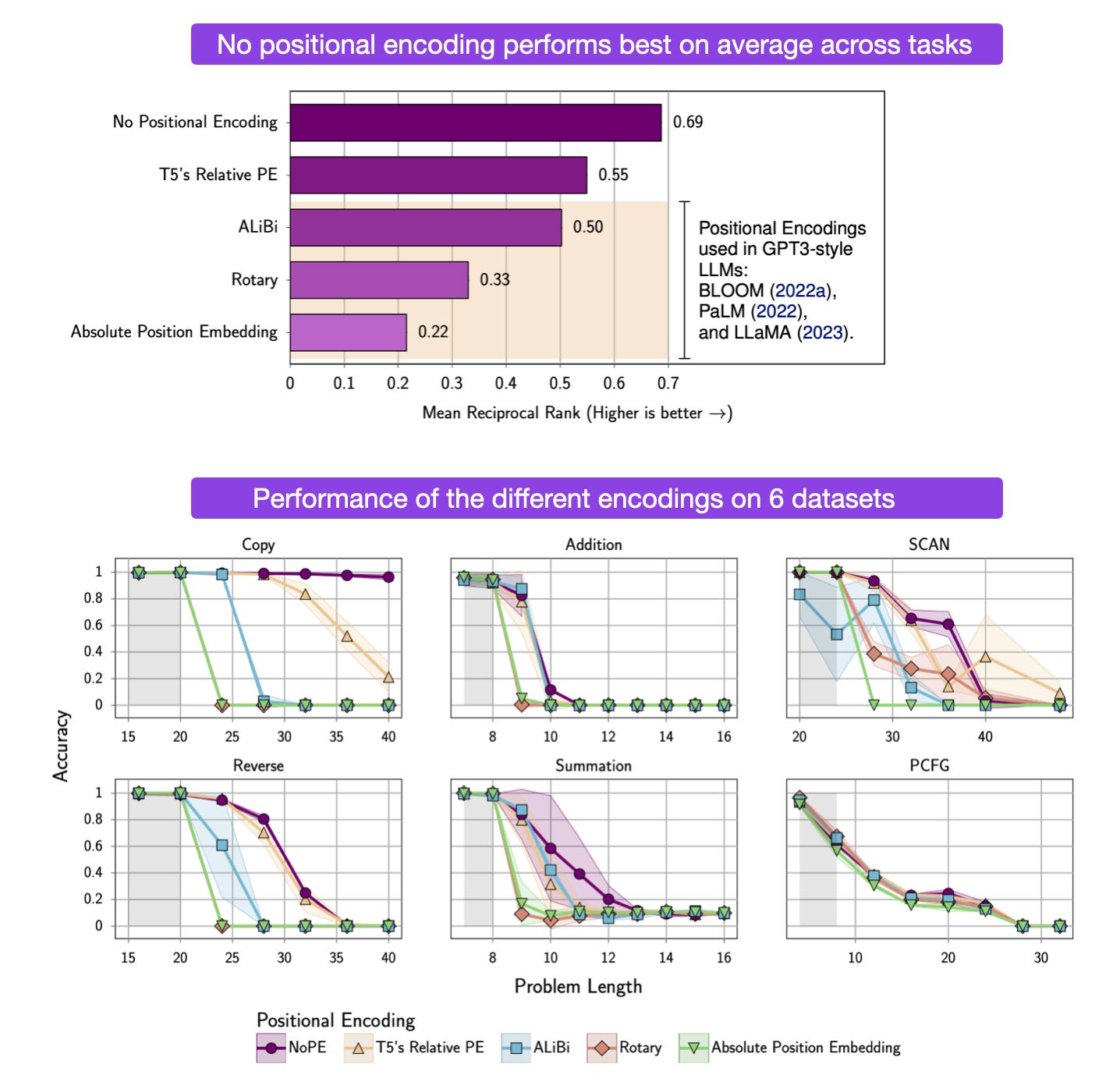
The Impact of Positional Encoding on Length Generalization in Transformers (https://arxiv.org/abs/2305.19466, 31 May 2023)
Transformers show varying performance regarding the different lengths of the training examples. This is especially a problem during finetuning, where longer instructions are relatively rare. In this paper, researchers find that removing the positional encoding outperforms all variants, like using absolute, relative, ALiBi, or rotary positional encodings in decoder-only transformers.
Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks (https://arxiv.org/abs/2305.14201, 23 May 2023)
Researchers finetuned a 7B LLaMA model, Goat, to surpass a 75x larger 540B PaLM model and GPT-4 in arithmetic tasks. Goat's success was attributed to supervised finetuning and the LLaMA tokenizer. Although calculators (and tools like Wolfram Alpha) are more appropriate for arithmetic, researchers likely chose this task for its simplicity in generating synthetic data and assessing model performance via accuracy metrics.

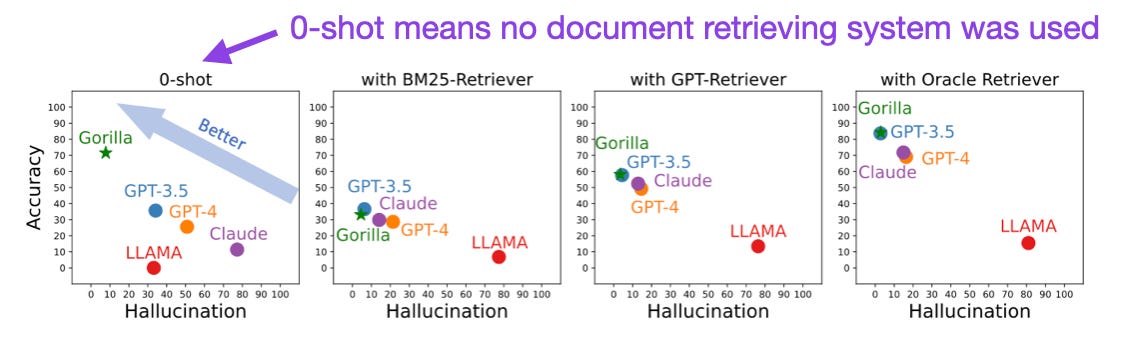
Gorilla: Large Language Model Connected with Massive APIs (https://arxiv.org/abs/2305.15334, 24 May 2023)
Gorilla is an LLM specifically finetuned to generate API calls (something GPT-4 could be better at). The researchers used a LLaMA-7B base model and finetuned it on 1,645 API calls from Torch Hub, TensorFlow Hub, and HuggingFace. The finetuned Gorilla outperformed other LLMs not finetuned on API calls.
Dynamic Masking Rate Schedules for MLM Pretraining (https://arxiv.org/abs/2305.15096, 24 May 2023)
Traditionally, the BERT LLMs were pretrained with a 15% masking rate. In this paper, researchers varied the masking rate between 15-30% during pretraining and found that it can mildly improve the accuracy on language translation benchmarks like GLUE by 0.46%. But more impressively, it was possible to achieve the original BERT accuracy 1.89x faster using the proposed varying masking rate.

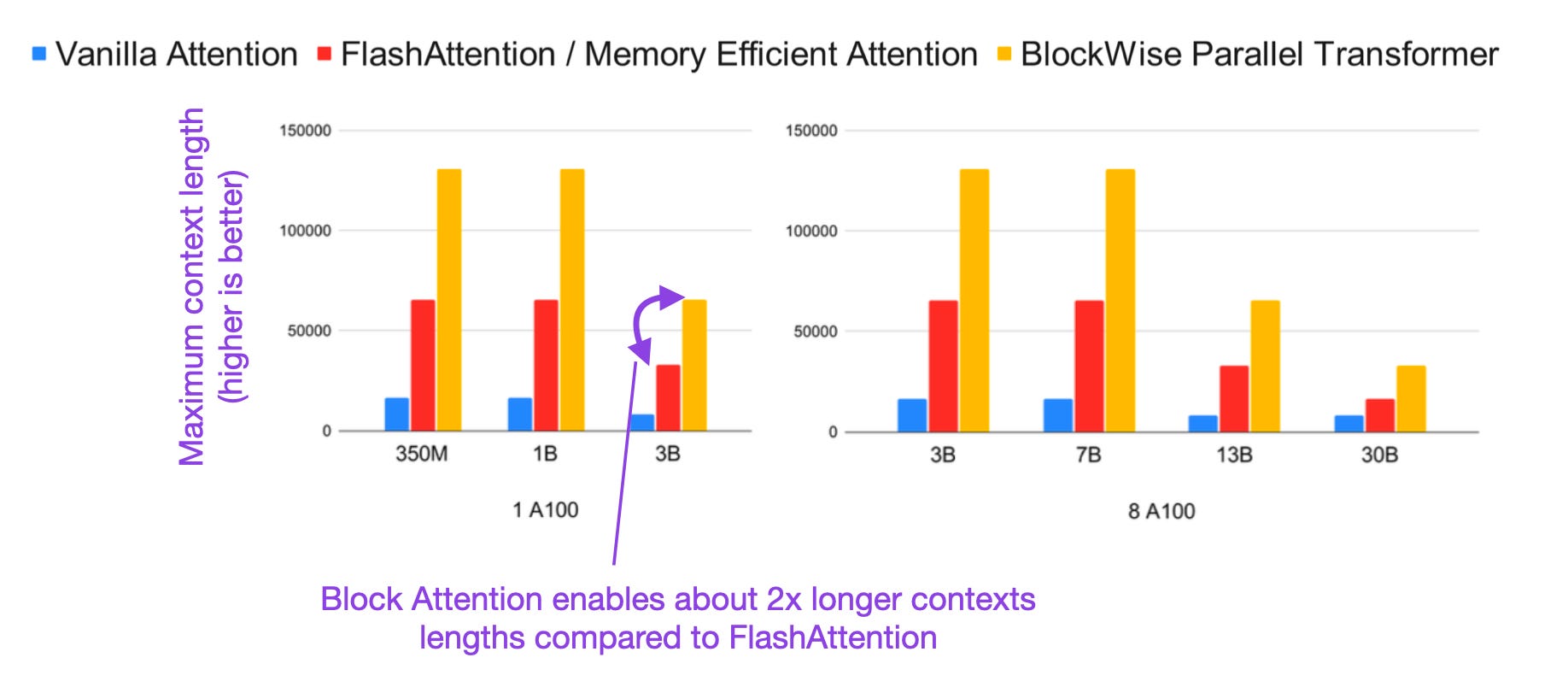
Blockwise Parallel Transformer for Long Context Large Models (https://arxiv.org/abs/2305.19370, 30 May 2023)
The optimization technique proposed in this article performs the self-attention computation blockwise to avoid doing the forward step on the entire sequence. The memory-savings allow training transformers with up to 32 longer contexts than using the original self-attention implementation and approximately 2 times longer than FlashAttention. Like FlashAttention, it's an optimization that doesn't modify the architecture and thus shouldn't impact predictive results.
RWKV: Reinventing RNNs for the Transformer Era (https://arxiv.org/abs/2305.13048, 22 May 2023)
After sharing the code of the RWKV language model last year, it was almost forgotten again until the researchers finally released the research this month. RWKV is a recurrent neural network with transformer-level LLM performance. What's remarkable about RWKV is that its modeling performance is comparable to some LLMs like Pythia but comes with substantially less computational costs.

SEAHORSE: A Multilingual, Multifaceted Dataset for Summarization Evaluation (https://arxiv.org/abs/2305.13194, 22 May 2023)
Most LLMs are trained on English instruction datasets and evaluated on English language benchmarks. Seahorse provides a new dataset of 96K summaries covering 6 languages for multilingual and multifaceted summarization evaluation. The dataset is released under a permissible Creative Commons Attribution 4.0 International license; however, the dataset collection procedure is not very clearn, and I am hoping that it doesn't contain any copyrighted texts.

Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision (https://arxiv.org/abs/2305.03047, 4 May 2023)
Researchers propose Self-Align to develop Dromedary, which is a finetuned 65B LLaMA model. Self-Align is alternative to supervised finetuning and reinforcement learning from human feedback (RLHF) to align LLMs to human intentions. This is done in four steps: (1) use an LLM to generate prompts; (2) devise human-written principles and guide the LLM via in-context learning to write responses; (3) train the LLM on the self-aligned responses, and (4) refine the overly brief or indirect responses.

Computer Vision
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention (https://arxiv.org/abs/2305.07027, 11 May 2023)
EfficientViT is a new vision transformer that provides a good trade-off between speed and accuracy. It outperforms other efficient architectures like MobileNetV3 and MobileViT while being substantially faster. The researchers achieve this with cascaded group attention, which reduces redundancy in the multi-head self-attention layers by feeding each attention head with different splits of the full features (analogous to group convolutions).

Parallel Sampling of Diffusion Models (https://arxiv.org/abs/2305.16317, 25 May 2023)
Diffusion models generate high-quality images via a sequence of hundreds to thousands of denoising diffusion steps, which is computationally expensive. In this paper, instead of reducing the number of diffusion steps and trading off quality, the researchers propose to run the diffusion steps in parallel to some extent. The proposed method can improve the sampling speed by 2-4x while maintaining similar image quality.

Getting ViT in Shape: Scaling Laws for Compute-Optimal Model Design (https://arxiv.org/abs/2305.13035, 22 May 2023)
Previously, studies have focused on the optimal dataset sizes and model sizes in terms of parameter numbers. Here, researchers propose methods to infer compute-optimal model shapes, for example, width and depth. The result is a vision transformer that outperforms models twice its size. Moreover, while the smaller compute-optimal model was trained using the same compute resource budget, it achieved less than half the inference cost of its larger counterpart.

Audio and Speech
Scaling Speech Technology to 1,000+ Languages (https://arxiv.org/abs/2305.13516, 22 May 2023)
Meta AI develops a speech-to-text model for ~1,100 different languages (for comparison, OpenAI's Whisper model supports 99) called MMS. Meta's MMS model outperforms Whisper on all 54 languages in the FLEURS benchmark that are covered by both MMS and Whisper. The model is released under a permissible CC-BY-NC 4.0 license.

General Methods
Sophia: A Scalable Stochastic Second-order Optimizer for Language Model Pre-training (https://arxiv.org/abs/2305.14342, 23 May 2023)
Sophia is a second-order optimization algorithm that promises to be particularly attractive for LLMs where Adam and AdamW are usually the dominant ones. Compared to Adam, Sophia is 2x faster, and models trained with Sophia can achieve better modeling performance. In a nutshell, Sophia normalizes the gradients by gradient curvature instead of gradient variance, as in Adam.

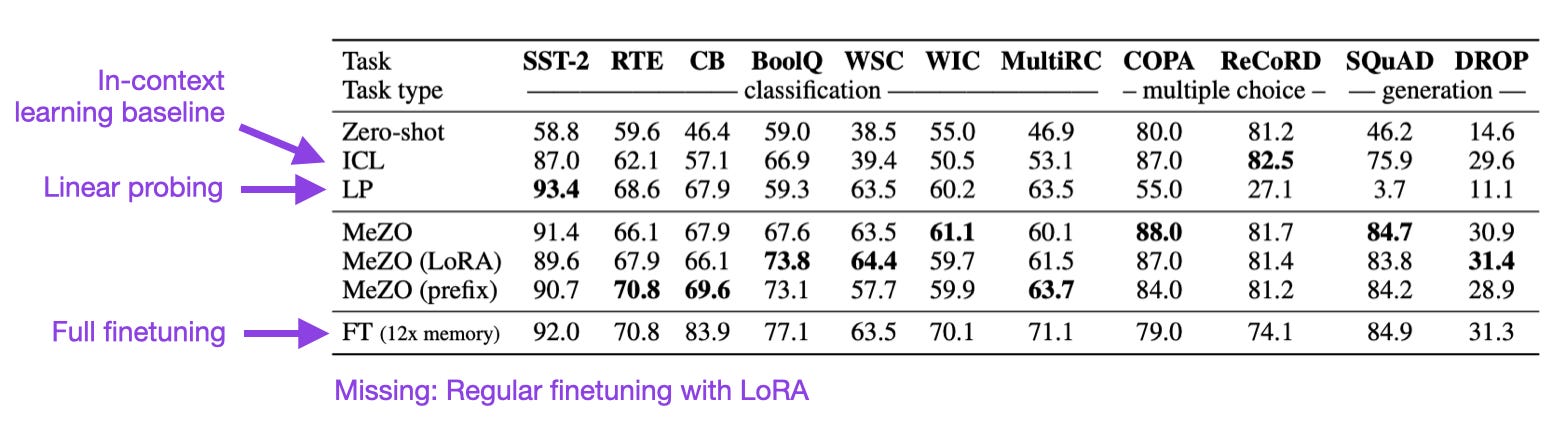
Fine-Tuning Language Models with Just Forward Passes (https://arxiv.org/abs/2305.17333, 27 May 2023)
Researchers propose a memory-efficient zeroth-order optimizer (MeZO) to finetune LLMs with the same memory footprint as required during inference. Note that zero-th order methods only require forward passes and no gradient information, which is in contrast to first-order methods (like SGD and Adam, which use gradient information) and second-order methods (which additionally use curvature or Hessian matrix information). In benchmarks, LLMs finetuned with this method outperform in-context learning baselines and seems to outperform full finetuning.
Dropout Drops Double Descent (https://arxiv.org/abs/2305.16179, 25 May 2023)
Double descent is a phenomenon observed where the test error of a model first decreases, then increases, and then decreases again as the model complexity increases. The new "Dropout Drops Double Descent" paper, with a fun tongue-twister in the title, sheds some light on why we might not see double descent that often in practice: "previous deep learning models do not encounter double-descent scenarios—because we already apply a usual regularization approach like the dropout in our models."

This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Thanks love these monthly articles highlighting new advancements. Although I do my best to keep up, there was one paper here that totally fell off my radar. Please keep it up!
Rewritten by GPT-4:
Drawing inspiration from the Goldilocks principle, these mid-month updates featuring 20-25 summaries strike the perfect balance. These concise overviews are easily recommendable to all my friends, even those who lack the patience for lengthier, more detailed analyses or a greater number of summaries.
In an implicit nod to the Pareto principle, these summaries effectively capture the crucial points without being too few, too numerous, too lengthy, or too brief. Although I personally enjoy a more extensive and in-depth collection of summaries, I must admit that sharing such a comprehensive weekly newsletter with my friends would be futile, as they simply wouldn't read it.
Rewritten by Bard:
The mid-month updates with 20-25 summaries are just right, like Goldilocks' porridge. They are not too long, not too short, and not too many. This makes them perfect for sharing with friends who may not have the patience for longer or more in-depth summaries.
In a way, these updates are a tribute to Pareto's principle, which states that 80% of the results come from 20% of the effort. The updates focus on the most important news and developments, so they are a valuable way to stay informed without having to read through a lot of unnecessary information.
Personally, I would prefer more in-depth summaries, but I know that my friends would not be interested in reading them. So, I appreciate the balance that the mid-month updates strike. They are just right for me and my friends.
Rewritten by Claude (not Claude-instant):
Applying the Goldilocks principle, these biweekly updates with 20-25 summary points strike the right balance. Compared to extensive AI research reports, these digestible summaries are what I can recommend to all my friends, even those with little patience for lengthy, in-depth analysis or an overload of summaries.
In an unintentional nod to Pareto's principle, you capture the essential insights without being too sparse, excessive, long-winded or cursory. Personally, I prefer far more comprehensive and in-depth summaries...but I couldn't share that particular type of weekly newsletter with any of my friends. They would simply ignore such a publication.
My comment on the rewrites:
Claude missed it on the frequency of your updates. For my money, GPT-4 performed the best. YMMV.