

Long Contexts and Scaling Transformers to 1,000,000,000 Tokens

In this article, I compiled and annotated 24 AI research highlights form June to July 2023. A lot of exciting developments are currently happening, once again, in the fields of natural language processing and computer vision!
In addition, if you are curious about last month's highlights, you can find them here:

Large Language Models
Lost in the Middle: How Language Models Use Long Contexts (6 Jul, https://arxiv.org/abs/2307.03172)
In this paper, researchers investigated how well LLMs like ChatGPT perform in retrieving relevant information from different parts of its input context. It turns out that ChatGPT performs less well in terms of retrieving information if it's contained in the middle of a document. Other LLMs like Claude perform slightly better.

LongNet: Scaling Transformers to 1,000,000,000 Tokens (5 Jul, https://arxiv.org/abs/2307.02486)
We have recently seen a couple of attempts to scale LLMs to longer context lengths, including the RMT paper on scaling transformer LLMs to 1M tokens and 2) the convolutional Hyena LLM for 1M tokens. In this paper, the authors propose LongNet to scale transformer LLMs to 1,000,000,000 (1B) tokens. Similar to BigBird, published a few years ago, it achieves linear (versus quadratic) scaling via dilated (versus self-) attention, but the difference is that BigBird uses a heuristic, random pattern for the token pairs.

Training Transformers with 4-bit Integers (21 Jun, https://arxiv.org/abs//2306.11987)
This paper presents a new method for accelerating neural network training by quantizing the activation, weight, and gradient to 4-bit precision using INT4 arithmetic, explicitly designed for transformers. Unlike existing 4-bit training methods, the proposed method doesn't require custom numerical formats; hence it can be implemented on the current generation of GPUs. The proposed method achieves competitive accuracy on several tasks and can speed up the training process by up to 35.1% (memory savings are not discussed).

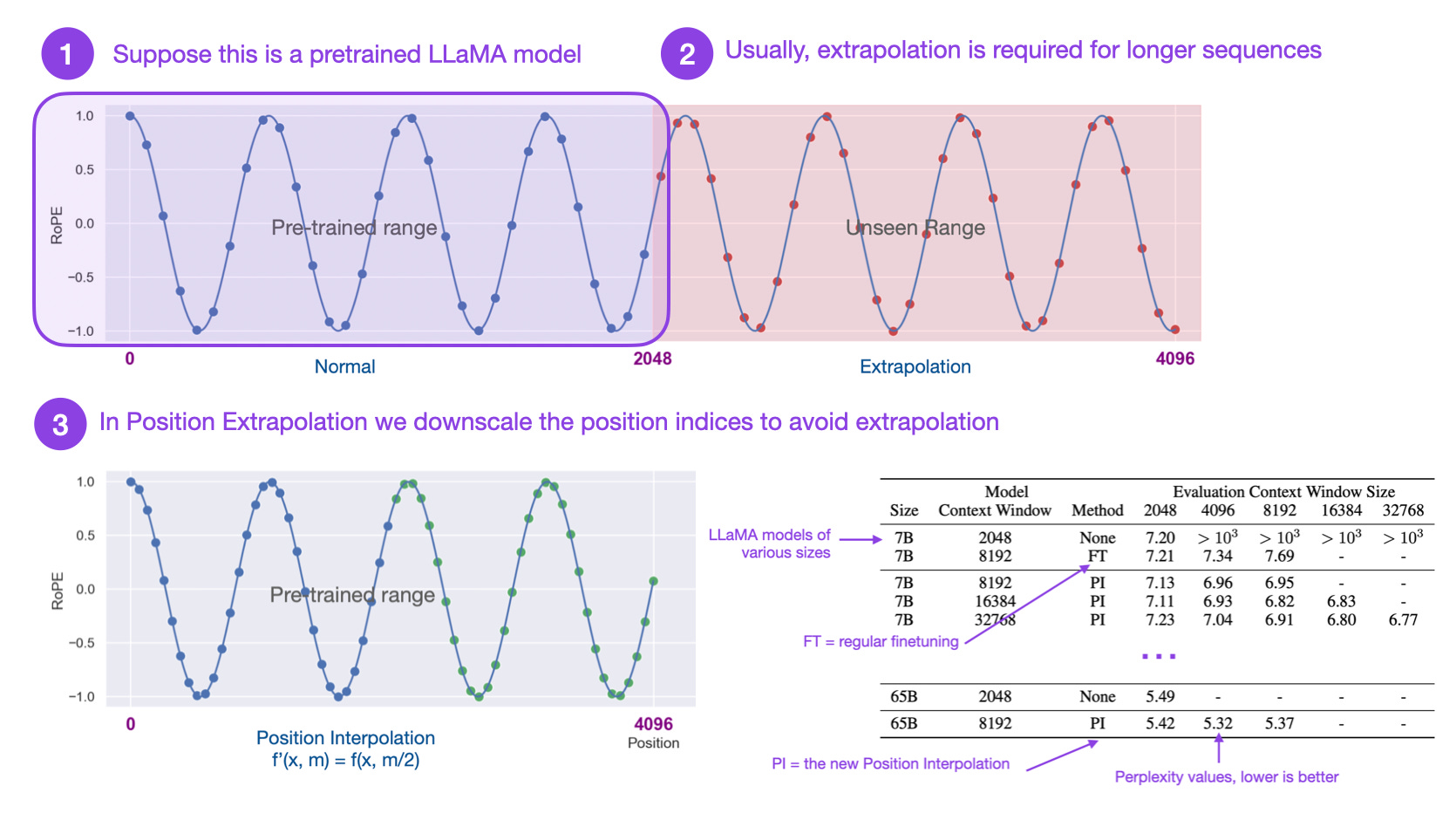
Extending Context Window of Large Language Models via Positional Interpolation (27 Jun, https://arxiv.org/abs/2306.15595)
Rotary positional embeddings (RoPE) have been a recent cornerstone of modern LLM implementations since it supports flexible sequence lengths. In this paper, researchers propose Position Interpolation to increase RoPE-based context window sizes to 32,768 tokens with minimal (1000 steps) finetuning. This allows long document summarization using LLaMA 7B and 65B models, for example.
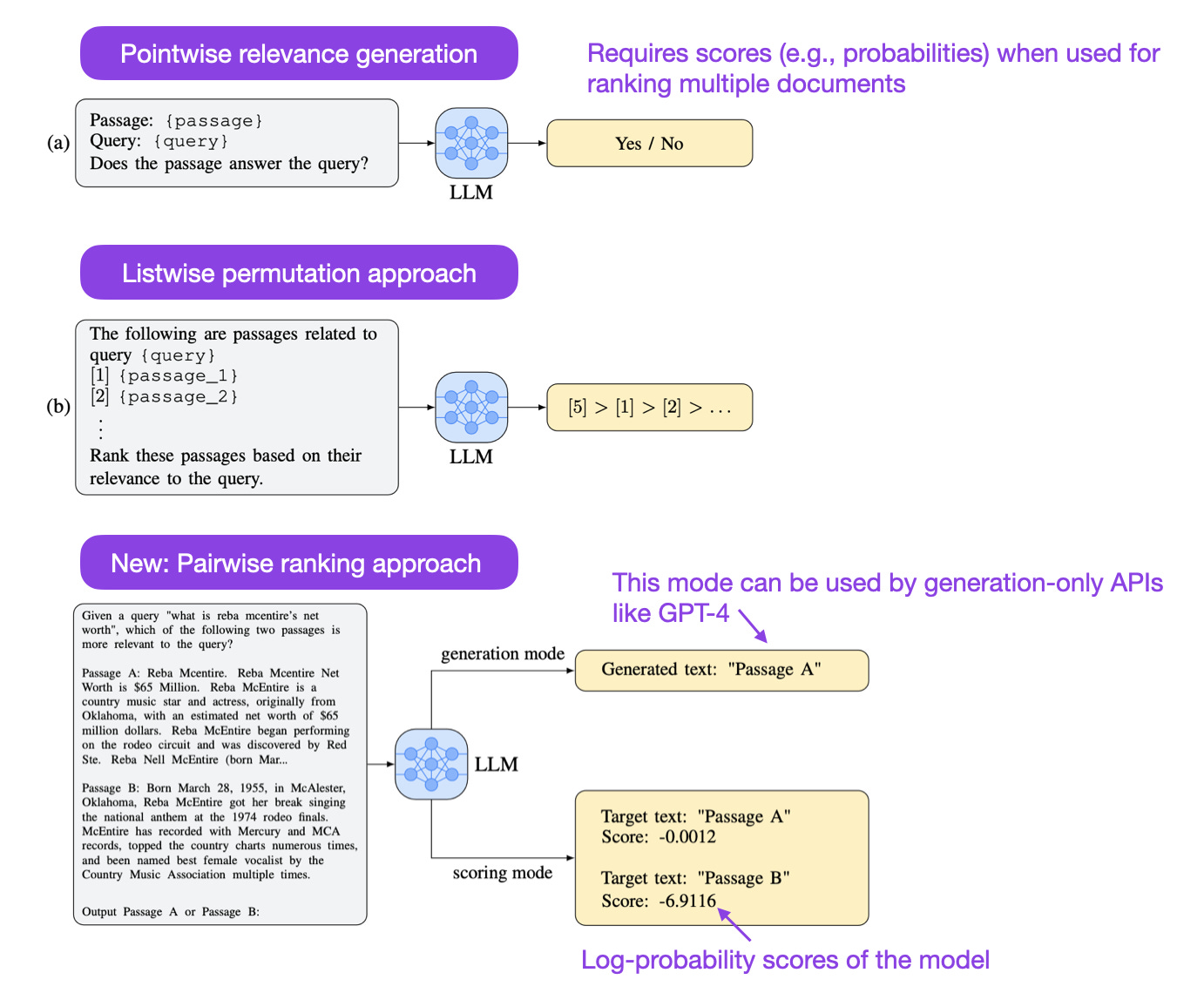
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting (30 Jun, https://arxiv.org/abs/2306.17563)
Researchers evaluated LLMs for relevancy ranking, which is relevant for regular users and for researchers evaluating LLM performance (the latter use-case is not explicitly explored in this paper, though). They compare pointwise approaches (which don't work for APIs like GPT-4 since they require log probabilities if used for ranking) and listwise approaches and introduce a new pairwise ranking prompting method. Using the new pairwise ranking approach, even moderate-sized open-source LLMs based on FLAN-T5 and FLAN-UL2 can perform well (comparable with the gpt-3.5.turbo with 10X - 50X more parameters).
Bring Your Own Data! Self-Supervised Evaluation for Large Language Models (23 Jun, https://arxiv.org/abs//2306.13651)
It goes without saying that in client-facing applications, ensuring that LLMs are truthful and don't respond with profanities is a major challenge regarding real-world applications of LLMs. Instead of relying on small, curated evaluation datasets that may have leaked into the training set, researchers propose a self-supervised evaluation alternative. They find a strong correlation between self-supervised evaluations and human evaluations, which indicates that this approach may be viable.

Focused Transformer: Contrastive Training for Context Scaling (6 Jul, https://arxiv.org/abs/2307.03170)
One workaround for LLMs context length constraints is accessing documents stored externally (e.g., via a vector database approach). But the larger the database, the more irrelevant keys it contains for a given query, which decreases the model performance. To address this, researchers introduce the "Focused Transformer" finetune LLMs (like OpenLLaMA) via a new contrastive learning procedure.

Textbooks Are All You Need (20 Jun, https://arxiv.org/abs/2306.11644)
In this paper, researchers trained a refreshingly small-sized 1.3B parameter transformer model on a high-quality dataset: a relatively small 6B token "textbook quality" dataset from the web plus 1B tokens of exercises synthesized via GPT-3.5. For comparison, GPT-3 / GPT-3.5 has 175 parameters (130x larger), and comparable LLaMA models were trained on 1T tokens (140x more data). The proposed model outperforms GPT-3.5 (but not GPT-4) even though it's much smaller and has been trained on a much smaller (but higher quality) dataset than the reference LLMs.

ClinicalGPT: Large Language Models Finetuned with Diverse Medical Data and Comprehensive Evaluation (16 Jun, https://arxiv.org/abs/2306.09968)
In the past, I've been advocating a lot for finetuning pretrained LLMs (foundation models) for more specific applications. ClinicalGPT is a good example of this, where researchers incorporated medical data into the training pipeline to handle clinical tasks better. In short, they finetuned a pretrained LLM (BLOOM-7B) using reinforcement learning with human feedback -- the same instruction-finetuning strategy that was used on GPT-3 to create the original ChatGPT model.

A Simple and Effective Pruning Approach for Large Language Models (20 Jun, https://arxiv.org/abs/2306.11695)
Models like DistilBERT are popular because LLMs are usually too large for most contexts, but creating such pruned versions of a model usually require retraining. In this paper, researchers propose an approach that does not require retraining a pretrained LLM for pruning. The approach is relatively simple and based on determining the weight importance for pruning based on computing element-wise product between the weight magnitude and norm of input activations.

How Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources (Jun 7, https://arxiv.org/abs/2306.04751)
In this paper, the authors investigate the performance of openly available LLM models, such as LLaMA, when finetuned on openly available instruction datasets. Some models, such as LLaMA, can achieve a "win rate" of 70% over the proprietary text-davanici-003 (GPT 3.5) model. It should be noted that the authors used supervised finetuning instead of reinforcement learning with human feedback, which was used for InstructGPT and ChatGPT.

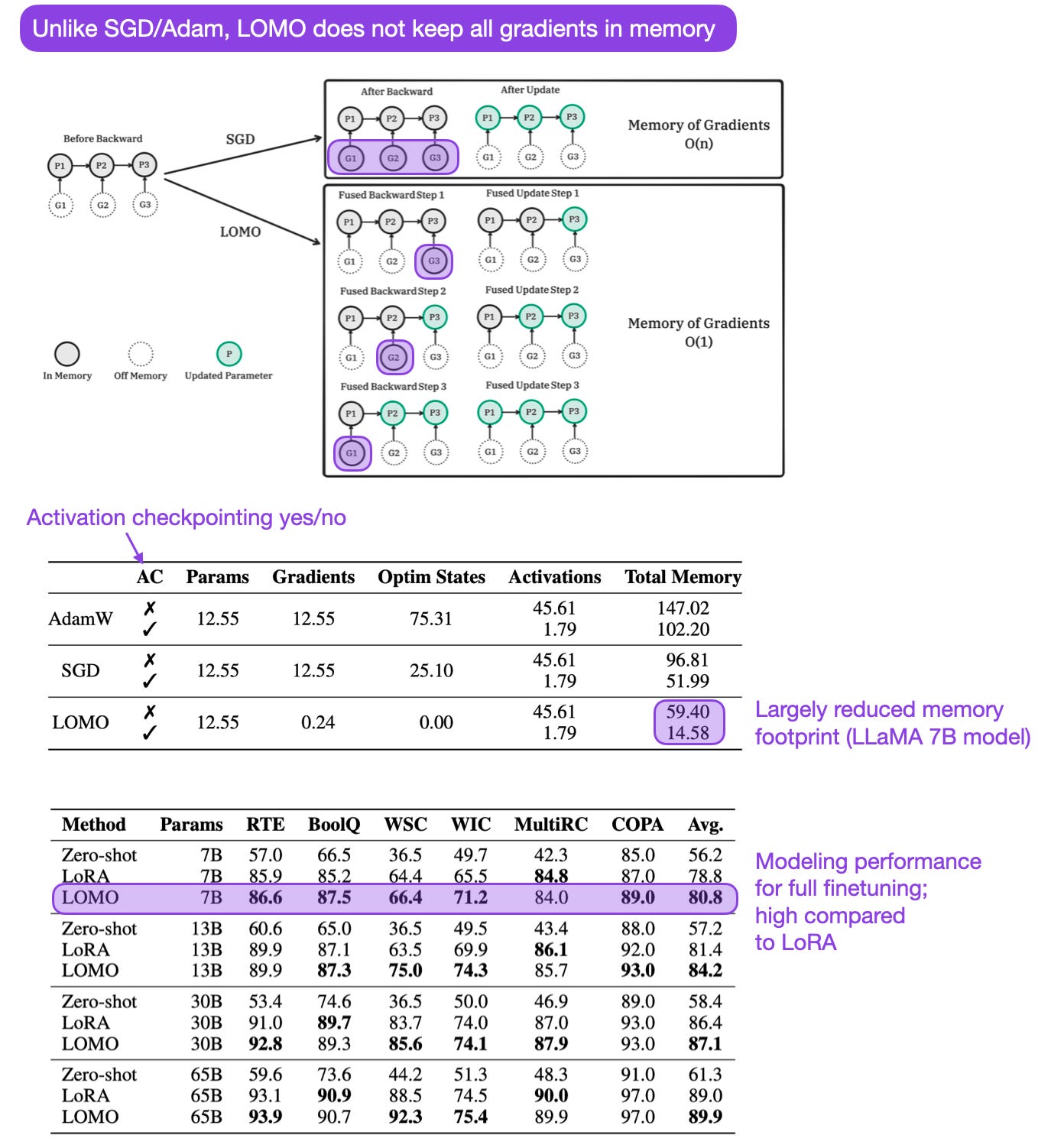
Full Parameter Fine-tuning for Large Language Models with Limited Resources (16 Jun, https://arxiv.org/abs/2306.09782)
Typically, we resort to parameter-efficient finetuning methods, such as Adapters and low-rank adaptation (LoRA), when finetuning LLMs under resource (particularly memory) constraints. Here, researchers propose a new optimizer (LOw-Memory Optimization, LOMO) as an alternative method, which saves memory by combining gradient computation and parameter updates into a single step. It can be combined with Adapters, LoRA, and other techniques, but the caveat is that it can't be combined with gradient accumulation, and the savings when using Adam are just 25%.
Preference Ranking Optimization for Human Alignment (30 Jun, https://arxiv.org/abs//2306.17492)
Last month, I covered direct preference optimization (DPO) as a simpler alternative for reinforcement learning with human feedback (RLHF) for LLM instruction-finetuning. In this paper, researchers propose another alternative: Preference Ranking Optimization (PRO). The advantage of PRO over RLHF is that PRO utilizes the whole ranking sequence instead of just pairwise rankings.

Computer Vision
Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution (12 Jul, https://arxiv.org/abs/2307.06304)
When training language transformers, researchers often take advantage of sequence packing (also referred to as "packing padded sequences"), which handles variable-length sequences efficiently by avoiding unnecessary computation on padding tokens. In this paper, researchers extend the idea of sequence packing to vision transformers and NaViT (Native Resolution ViT) that processes and trains on inputs of arbitrary resolutions and aspect ratios. The proposed procedure improves both training efficiency and model accuracy.

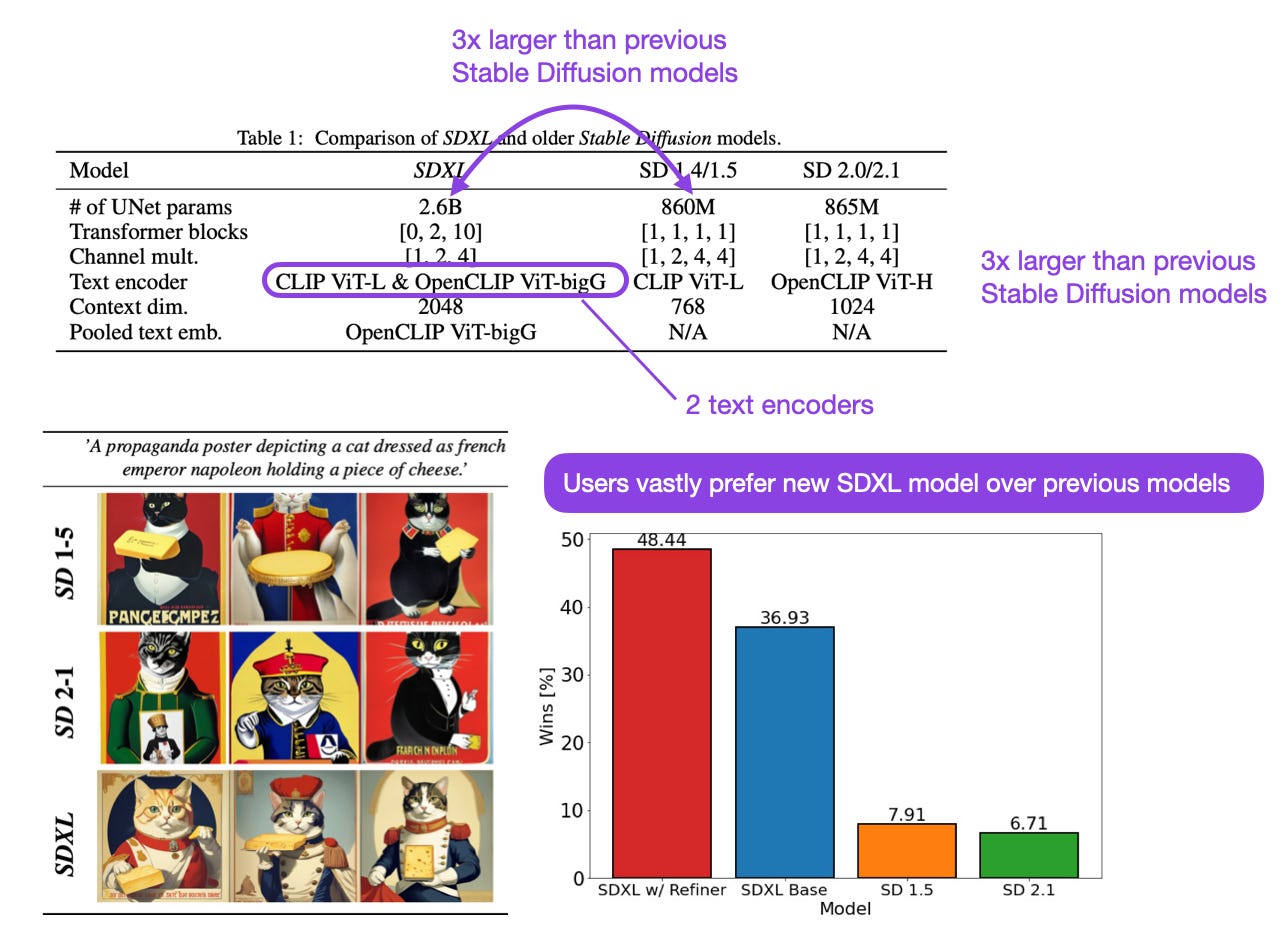
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis (4 Jul, https://arxiv.org/abs/2307.01952)
SDXL (short for Stable Diffusion XL) is a new iteration of the latent diffusion-based Stable Diffusion model for text-to-image generation. Its underlying convolutional UNet backbone is now 3 times larger, and it uses a second CLIP text encoder (the outputs of two different CLIP encoders are concatenated along the channel axis). According to preference studies, users vastly prefer the generated outputs of SDXL over previous stable diffusion models.
Self-Consuming Generative Models Go MAD (4 Jul, https://arxiv.org/abs/2307.01850)
Researchers investigated the effect of training generative AI models on synthetic data. Without fresh training data, the performance of the models progressively decreases with each training round as progressive training rounds on the models' own generated data amplify the models' biases. The takeaway is that either synthetic quality or diversity is impacted when training generative models on (even high-quality) synthetic data.

Fast Training of Diffusion Models with Masked Transformers (15 Jun, https://arxiv.org/abs/2306.09305)
Motivated by the fact that images contain a lot of redundancy (and inspired by representation learning), researchers propose to mask out a large number of patches when training diffusion transformers for image generation. This introduces an auxiliary loss of reconstructing masked patches to the regular denoising objective during training. They found they could achieve the same quality as a state-of-the-art diffusion transformer for image generation but require 70% less training time.

Other
HyenaDNA: Long-Range Genomic Sequence Modeling at Single Nucleotide Resolution (27 Jun, https://arxiv.org/abs/2306.15794)
This work is an application of the recent Hyena paper (Hyena Hierarchy: Towards larger convolutional language model), which proposed a new convolutional model for text as an alternative to transformer LLMs back in April. The appeal is that Hyena can model context lengths up to 1 million tokens (which is relevant for working with DNA, for example). In short, it supports longer context lengths than regular transformer LLMs and trains faster at a comparable size.

Simple and Controllable Music Generation (https://arxiv.org/abs/2306.05284, Jun 8)
Authors from Meta AI trained generative single-stage transformer language models (300M, 1.5B, and 3.3B) on approximately 20,000 hours of copyrighted music. The music dataset consisted of 10K high-quality music tracks from ShutterStock and Pond5. The novelty here is the efficient token interleaving patterns allowing the model to generate high-quality music samples without upsampling cascades or hierarchies.

General Computational Efficiency
Rockmate: an Efficient, Fast, Automatic and Generic Tool for Re-materialization in PyTorch (3 Jul, https://arxiv.org/abs/2307.01236)
Rockmate is a PyTorch tool that analyzes and automatically rewrites models (like GPT) to use a predefined amount of memory for computing the activations. The trade-off is that it increases re-computations (slowing the runtime), but it allows running bigger models on smaller hardware. The memory savings can be 2-5x while the overhead is as small as 10-20% in some instances.

ZeRO++: Extremely Efficient Collective Communication for Giant Model Training (Jun 16, https://arxiv.org/abs/2306.10209)
ZeRO (Zero Redundancy Optimizer) is an optimization strategy that partitions model states across GPUs to reduce memory requirements and enables the training of larger models like LLMs. In this paper, the researchers introduce three communication volume reduction techniques to optimize throughput. In short, these optimizations include block-quantization-based all-gather, data remapping, and all-to-all-based quantized gradient averaging.

This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Nice update!
Do you see LongNet ultimately being rolled out everywhere? In other words, assuming this works, will ChatGPT, Bard, etc ultimately have a billion token capacity? Will they be able to do things like read entire books and have discussions about their content with you, etc?