

A Potential Successor to RLHF for Efficient LLM Alignment and the Resurgence of CNNs

From Vision Transformers to innovative large language model finetuning techniques, the AI community has been very active with lots of interesting research this past month.
Here's a snapshot of the highlights I am covering in this article:
In the paper ConvNets Match Vision Transformers at Scale, Smith et al. invest significant computational resources to conduct a thorough comparison between Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs), challenging the prevailing notion that ViTs outperform CNNs in image classification tasks.
The Mistral 7B paper introduces a compact yet powerful language model that, despite its relatively modest size of 7 billion tokens, outperforms its larger counterparts, such as the 13B Llama 2 model, in various benchmarks. This surprisingly good performance may be largely attributed potentially to its unique training data.
Zephyr: Direct Distillation of LM Alignment presents a fresh approach to training language models, showcasing the Zephyr 7B model's remarkable performance in both conversational and knowledge benchmarks. They employed distilled Direct Preference Optimization (DPO), which is much less complex than Reinforcement Learning with Human Feedback (RLHF).
In their paper NEFTune: Noisy Embeddings Improve Instruction Finetuning, Jain, Chiang, Wen, Kirchenbauer et al. present a simple and straightforward method to enhance the performance of language models: the injection of uniform random noise into token embeddings. This technique, called NEFTune, has been shown to significantly improve performance in conversational tasks, and it does so without compromising knowledge in question-answer tasks.
PS: Readers of the monthly research highlights may notice that I am changing up the format of the AI research paper highlights, selecting a handful of papers for more detailed summaries and discussions of a handful of papers. In addition, I also included very short summaries of 20+ additional papers that piqued my interest. I hope you like the new format!
ConvNets Match Vision Transformers at Scale
In this paper, researchers invested compute budgets of up to 110k TPU hours to do a fair comparison between ViTs and CNNs.
Their findings revealed that when CNNs are pretrained with a compute budget similar to what is typically used for ViTs, they can match the performance of ViTs. For this, they pretrained on 4 billion labeled images from JFT and subsequently finetuned the models on ImageNet.

Personally, I've observed that it's easier to achieve good image classification performance when finetuning ViTs compared to finetuning CNNs. For instance, a small ViT can be finetuned for a few minutes on a single GPU and achieve approximately 96% accuracy on CIFAR-10. In my teaching experience, obtaining such good results was always challenging with pretrained CNNs. In retrospect, this might be because ViTs benefited from a larger pretraining budget.
Inference
One aspect I wish had been addressed in the paper is inference performance. While it's feasible to match the performance of finetuned ViTs with finetuned CNNs, I wonder about the advantages one might offer over the other regarding memory footprint and inference speed for the exact models they used.
However, this analysis may also be a bit unfair since ViT architectures are relatively new compared to CNNs, which have been heavily optimized over the years. Also, I can understand that such a study is beyond the scope of this work, as it would be relatively comprehensive if both TPUs and GPUs were taken into account. For instance, TPUs are known to be more optimized for matrix multiplications, which are common in ViTs, whereas GPUs are more optimized for convolutions.
Beyond classification
While the main takeaway of this paper -- CNNs can match ViTs at scale -- is super interesting, the paper only focused on image classification. A natural question is whether this also applies to object detection and image segmentation, which would be interesting follow-up work.
Paper reference
ConvNets Match Vision Transformers at Scale by Smith, Brock, Berrada, and De (25 Oct), https://arxiv.org/abs/2310.16764
Mistral 7B
The Mistral 7B paper introduces a new "small" LLM with 7 billion tokens. The paper is relatively short on technical details, but it is still worth covering here since the openly available Mistral 7B LLM has been among the most popular models in the past few weeks. Moreover, the Mistral 7B base model also forms the basis for finetuning Zephyr 7B, which will be covered in the next section.
Mistral performs beyond its size
The main reason why Mistral 7B was so popular was that it outperforms the 13B Llama 2 model, which is almost twice as large, on most benchmarks.

Why exactly it is so good is unclear, but it might likely be due to its training data. Neither Llama 2 nor Mistral discloses the training data, so we can only speculate.
Architecture-wise, the model shares group-query attention with Llama 2. One interesting addition to the Mistral architecture is sliding window attention to save memory and improve computational throughput for faster training. (Sliding window attention was previously proposed in Child et al. 2019 and Beltagy et al. 2020.)
Sliding window attention
The sliding window attention mechanism used in Mistral is essentially a fixed-sized attention block that allows a current token to attend only a specific number of previous tokens (instead of all previous tokens), which is illustrated in the figure below.

In the specific case of 7B Mistral, the attention block size is 4096 tokens, and the researchers were training the model with up to 100k token context sizes.
To provide a concrete example, in regular self-attention, a model at the 50,000th token can attend all previous 49,999 tokens. In sliding window self-attention, the Mistral model can only attend tokens 45,904 to 50,000 (since 50,000 - 4,096 = 45,904).
However, note that sliding window attention mainly allows it to handle longer sequences, not to improve benchmark performance per se. (Most benchmark tasks are either multiple choice tasks or rely on short answers.)
In other words, sliding window attention is mainly used to improve computational performance. The fact that Mistral outperforms larger Llama 2 models is likely not because of sliding window attention but rather despite sliding window attention.
Paper reference
Mistral 7B by Jian, Sablayrolles, Mensch, Bamford et al. (10 Oct), https://arxiv.org/abs/2310.06825
Zephyr: Direct Distillation of LM Alignment
This paper introduces Zephyr 7B, which is currently one of the most exciting open-source LLMs. The reasons for this are twofold:
Zephyr 7B outperforms models of similar size as well as several larger models in both conversational and knowledge benchmarks.
The authors trained Zephyr using Direct Preference Optimization (DPO) in a fully automated fashion, which is much less complex than Reinforcement Learning with Human Feedback (RLHF).
Zephyr Performance
Let's start with a discussion of Zephyr's performance before we take a brief look at the DPO and distillation processes used in this paper.
The authors included a representative mix of LLMs in their benchmarks, ranging from 7B-parameter models trained with distilled supervised learning (more on distillation later) to 70B-parameter models trained with RLHF.
MT-Bench and AlpacaEval are benchmarks that evaluate the conversational abilities of LLMs. As the performance table below reveals, the 7B-parameter Zephyr model outperforms all other models in its size class. Even more impressively, Zephyr surpasses the 10 times larger 70B-parameter Llama 2 chat model on MT-Bench as well.

Alignment techniques such as RLHF and DPO typically focus on enhancing the instruction-following abilities of LLMs, as well as improving their helpfulness (and, in the case of Llama 2, also their safety). However, an improvement in instruction-following abilities can sometimes negatively impact the knowledge capabilities of LLMs. Therefore, in an additional benchmark, the authors demonstrated that Zephyr also possesses state-of-the-art knowledge skills, as measured by the multiple-choice tasks used in the Open LLM leaderboard, as shown in the table below.

Distillation
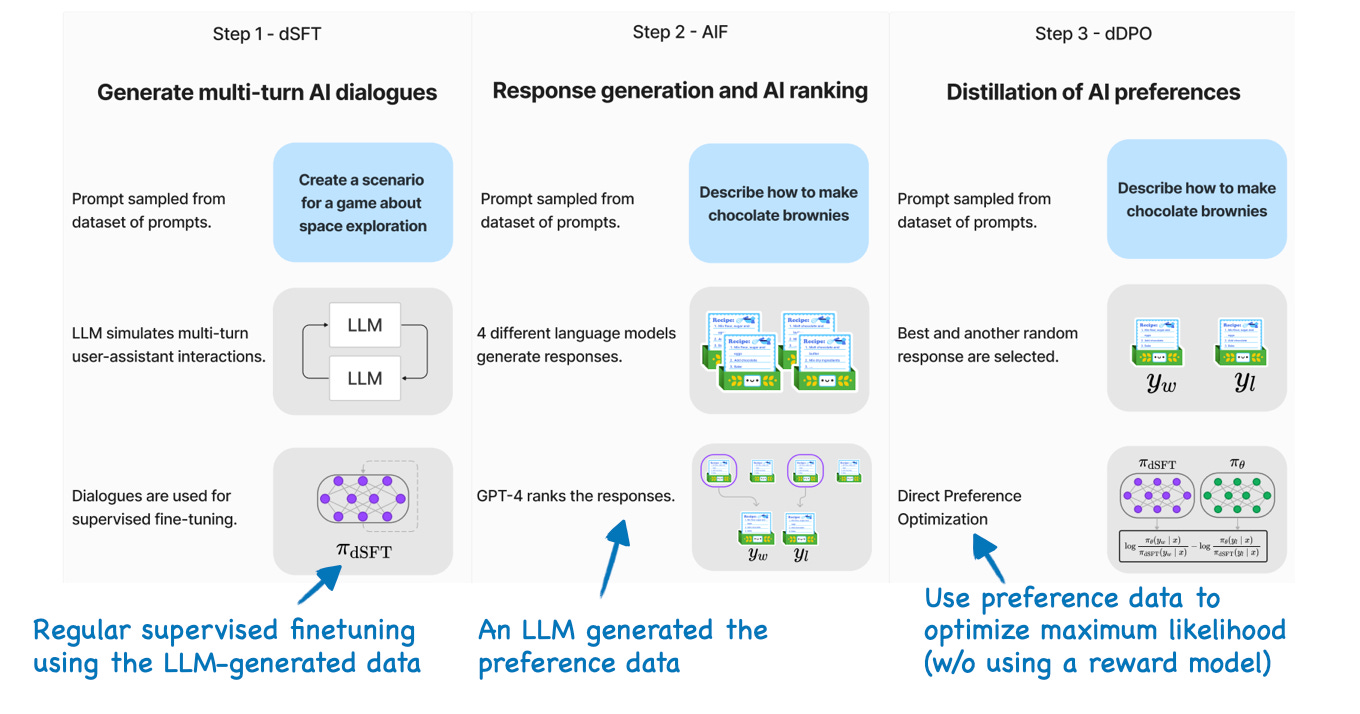
Unlike RLHF and other Proximal Policy Optimization approaches, the proposed dDPO method does not require human annotation and sampling — dDPO is a fully automated, end-to-end fine-tuning pipeline.
The distillation process involves a smaller target (student) LLM learning from a larger existing LLM (teacher). Here, the authors utilize LLM-generated data in two places:
Creating a dataset for supervised fine-tuning (similar to self-instruct);
Sampling and ranking responses to collect preference data for alignment fine-tuning.
Let's examine the dDPO process in the next section.
Direct Preference Optimization
In this paper, the researchers employed Distilled Direct Preference Optimization (dDPO). Before discussing the distilled aspect, let's define DPO. DPO is an alternative to RLHF that trains a model directly on the rewards, in contrast to RLHF. (Check out my standalone article LLM Training: RLHF and Its Alternatives for more details on RLHF.)

Zephyr adopts the DPO approach and focuses entirely on LLM-generated data (via GPT-4). The fact that this approach, which doesn't involve any human in the loop, works so well is very impressive.
Limitations
This is a very exciting paper, but I think there might be a potential bias in the MT-Bench and AlpacaEval benchmarks, which both use GPT-4 for preference evaluation. Since GPT-4 is also used for preference ranking in the dDPO procedure, the results from AlpacaEval and MT-Bench are likely overly optimistic. It would be interesting to see a human preference evaluation of Zephyr models (such a study is expensive, and I can understand why the authors omitted it).
Note that the focus of this paper is on constructing small and efficient LLMs that can outperform larger LLMs trained with RLHF, such as the 70B Llama 2 chat. However, a distillation approach will likely not be sufficient to develop new state-of-the-art LLMs (e.g., the successor to GPT-4). Since GPT-4 provided the data for this approach, I suspect that GPT-4 will act as the ceiling for the model's performance.
However, it will be interesting to see whether DPO (without distillation) can potentially be used to replace RLHF for new model development entirely.
Final words
The paper includes many additional interesting insights and ablation studies that I am not covering here due to the length of this article. For example, readers may wonder why dDPO is a 3-step procedure with supervised fine-tuning as the first step. Can this first step be skipped, and can we train a model only with DPO via steps 2 and 3? The answer is that without the supervised fine-tuning step 1, the model will perform terribly.
This is a really exciting paper; I can foresee it becoming the new reference methodology for training and aligning LLMs efficiently.
Paper reference
Zephyr: Direct Distillation of LM Alignment by Tunstall, Beeching, Lambert, Rajani et al. (25 Oct), https://arxiv.org/abs/2310.16944
NEFTune: Noisy Embeddings Improve Instruction Finetuning
We usually improve LLM finetuning performance via better base models, larger dataset sizes, and higher-quality data (more on that in the next Ahead of AI issue). In this paper, the researchers tried a different and simpler approach: injecting uniform random noise into the token embeddings.
Interestingly, when adding random noise to the token embeddings, the performance on AlpacaEval improved substantially, as shown in the figure below.
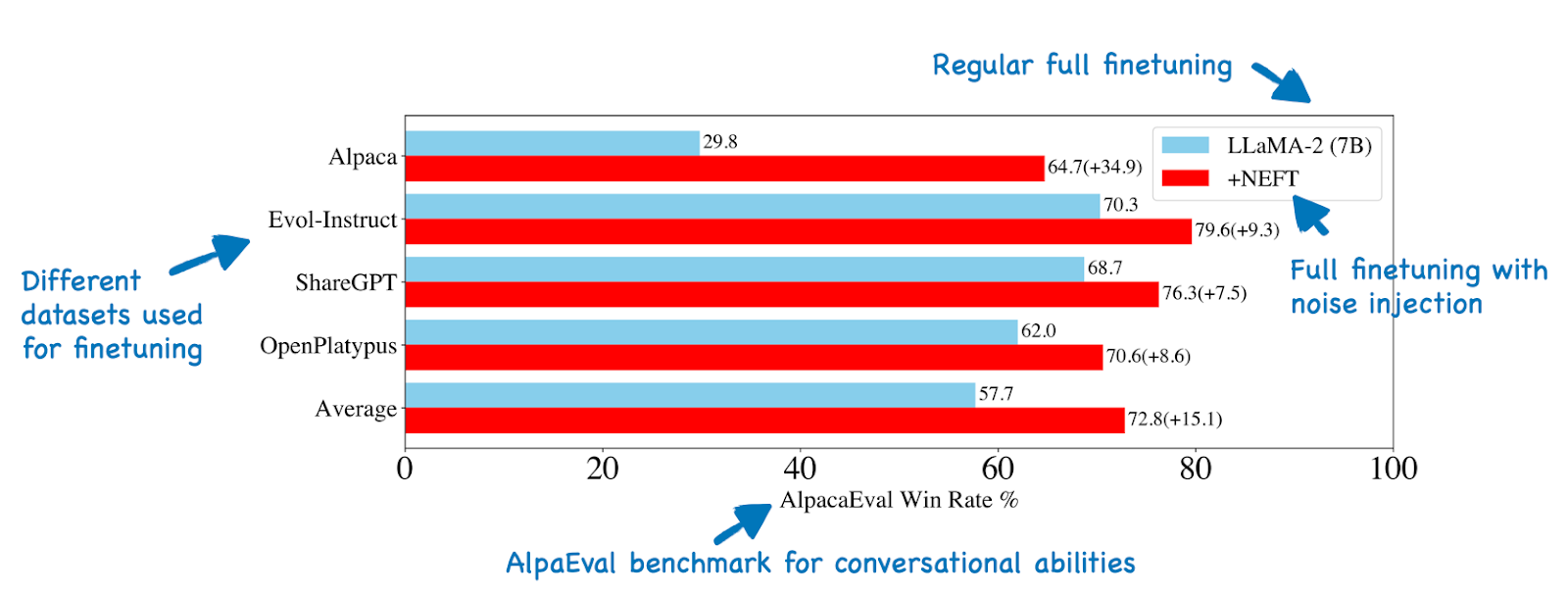
AlpacaEval is a benchmark that uses GPT-4 to select the better response given a base model and a finetuned model. Such automated LLM benchmarks have to be interpreted carefully because slight formatting changes can already result in performance changes. Moreover, GPT-4 preference analysis is also affected by the length of the responses (GPT-4 generally prefers longer responses). However, in this case, the researchers could reproduce the results with human evaluators, and it's likely a real effect.
How does NEFTune perform in multiple-choice question-answer tasks such as those on the Hugging Face OpenLLM leaderboard? Here, a model finetuned conventionally and finetuned via NEFTune have the same performance, as shown in the figure below, which indicates that there is no knowledge decline when training with NEFTune.

The positive effect that NEFTune has on the performance in conversational tasks such as those measured by AlpacaEval is likely due to a reduction in overfitting. For instance, the researchers found that NEFTune leads to higher training loss while reducing the loss on the test dataset.
The experiments above were all done using full finetuning. However, the proposed noise-injection method can also be used with the most popular finetuning techniques, such as LoRA and QLoRA. In the case of QLoRA, there is also a positive effect of NEFTune, but it is less pronounced than in finetuning, as shown in the table below
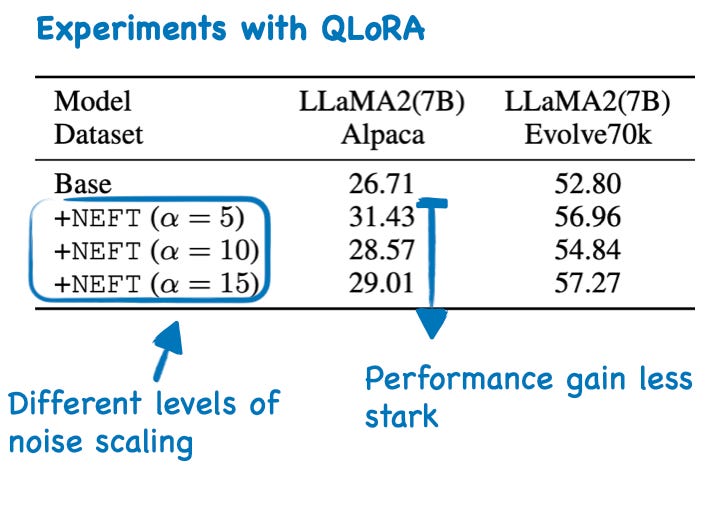
Since random noise injection can be seen as a simple form of data augmentation, which is usually used to reduce overfitting, it would have been interesting to see comparison studies with other techniques to reduce overfitting in LLMs, such as increasing the weight decay rate or increasing the dropout rates in adapter layers. The fact that the effect is less pronounced in QLoRA, which usually uses a dropout rate of 0.05, would support this hypothesis.
Even though I usually prefer QLoRA for finetuning because it allows me to finetune much, much larger models compared to full finetuning, I find the proposed NEFTune technique very intriguing nonetheless. Injecting random noise is easy to implement and essentially just one more additional configuration (with a hyperparameter for the scale of the noise values) to consider when finetuning LLM.
Paper reference
NEFTune: Noisy Embeddings Improve Instruction Finetuning by Jain, Chiang, Wen, Kirchenbauer et al. (9 Oct 2023), https://arxiv.org/abs/2310.05914
Other Interesting Research Papers
The Alignment Ceiling: Objective Mismatch in Reinforcement Learning from Human Feedback by Lambert and Calandra (31 Oct), https://arxiv.org/abs/2311.00168
This paper examines the complications of excessive Reinforcement Learning from Human Feedback (RLHF), leading to models that dodge user requests due to misguided safety concerns, lack flexibility in behavior, and exhibit monotonous response styles, while also questioning the efficacy of reward models and the accuracy of current evaluation tools for such models.\
Battle of the Backbones: A Large-Scale Comparison of Pretrained Models across Computer Vision Tasks by Goldblum, Souri, Ni, Shu, et al. (30 Oct), https://arxiv.org/abs/2310.19909
Consistent with the ConvNets Match Vision Transformers at Scale paper, the authors found that convolutional neural networks pretrained in a supervised fashion on large training sets still outperform pretrained vision transformers on many tasks.
FP8-LM: Training FP8 Large Language Models by Peng, Wu, Wei, Zhao, et al. (27 Oct) https://arxiv.org/abs/2310.18313
The authors propose a new FP8 automatic mixed-precision framework for training LLMs that reduces memory usage by 42% and increases training speed by 64% compared to the typical BFloat16 framework, without sacrificing model accuracy or requiring hyper-parameter adjustments.
CodeFusion: A Pre-trained Diffusion Model for Code Generation by Singh, Cambronero, Gulwani, Le, et al. (26 Oct), https://arxiv.org/abs/2310.17680
Researchers present a 75-million-parameter model that outperforms the 175-billion-parameter GPT-3 model and the specialized 15.5-billion-parameter StarCoder on most coding benchmarks.
Detecting Pretraining Data from Large Language Models by Shi, Ajith, Xia, Huang, et al. (25 Oct), https://arxiv.org/abs//2310.16789
The paper delves into the challenge of determining if a black-box model was trained on particular texts, such as copyrighted books, and proposes a method that, while not perfect, achieves a 7.4% improvement over previous techniques.
ALCUNA: Large Language Models Meet New Knowledge by Yin, Huang, and Wan (23 Oct), https://arxiv.org/abs/2310.14820
Researchers address the gap in benchmarks for evaluating how LLMs handle new knowledge, and they propose a new benchmark that reveals that LLMs underperform in reasoning between newly generated and existing internal knowledge.
Contrastive Preference Learning: Learning from Human Feedback without RL by Hejna, Rafailov, Sikchi, Finn et al. (20 Oct), https://arxiv.org/abs/2310.13639
This paper proposes Contrastive Preference Learning (CPL) a more straightforward, off-policy algorithm as an alternative to RLHF.
Understanding Retrieval Augmentation for Long-Form Question Answering by Chen, Xu, Arora, and Choi (18 Oct), https://arxiv.org/abs/2310.12150
This study offers new perspectives on the influence of retrieval augmentation on long, knowledge-rich text generation by LLMs and identifies attribution patterns for extended text generation, as well as the primary causes of attribution errors.
Can Large Language Models Explain Themselves? A Study of LLM-Generated Self-Explanations by Huang, Mamidanna, Jangam, Zhou, et al. (17 Oct), https://arxiv.org/abs/2310.11207
The authors' findings indicate that LLMs like ChatGPT, which are instruction-tuned on human conversations to provide "helpful" responses accompanied by self-explanations, produce explanations comparable in quality to traditional model interpretability techniques while being cheaper to generate.
BitNet: Scaling 1-bit Transformers for Large Language Models by Wang, Ma, Dong, Huang, et al. (17 Oct), https://arxiv.org/abs/2310.11453
This work introduces BitNet, a scalable and stable 1-bit Transformer architecture for large language models, featuring BitLinear as a replacement for the nn.Linear layer that enables training with 1-bit weights from scratch and demonstrates competitive performance with significantly reduced memory and energy consumption compared to 8-bit quantization methods and FP16 Transformer baselines.
Llemma: An Open Language Model For Mathematics by Azerbayev, Schoelkopf, Paster, Dos Santos, et al. (16 Oct), https://arxiv.org/abs/2310.10631
This paper introduces Llemma, an LLM for mathematics that outperforms existing models on the MATH benchmark and can perform formal theorem proving (the 7 and 34 billion parameter versions, dataset, and code are publicly available).
LoftQ: LoRA-Fine-Tuning-Aware Quantization for Large Language Models by Li, Yu, Liang, He, et al. (12 Oct), https://arxiv.org/abs/2310.08659
LoftQ is a new quantization framework that unifies quantization with LoRA finetuning on pretrained models, effectively reducing the performance gap between full- and LoRA-finetuning on downstream tasks by providing a suitable low-rank initialization that enhances the generalization of the quantized model.
Survey on Factuality in Large Language Models: Knowledge, Retrieval and Domain-Specificity by Wang, Liu, Yue, Tang, et al. (11 Oct), https://arxiv.org/abs/2310.07521
This survey examines the problems of factual inaccuracies in LLM outputs, assesses methodologies for evaluating LLM factuality with emphasis on key metrics and benchmarks, and investigates domain-specific strategies to improve LLM factuality.
Understanding the Effects of RLHF on LLM Generalisation and Diversity by Kirk, Mediratta, Nalmpantis, Luketina, et al. (10 Oct), https://arxiv.org/abs/2310.06452
This comprehensive analysis of the stages in finetuning LLMs with RLHF reveals that while RLHF offers better out-of-distribution (OOD) generalization, especially with larger train-test distribution shifts, it notably diminishes the output diversity compared to supervised finetuning.
OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text by Paster, Dos Santos, Azerbayev, and Ba (10 Oct), https://arxiv.org/abs/2310.06786
This paper introduces OpenWebMath, a 14.7B token dataset of mathematical webpages from Common Crawl, and it shows that language models trained on it significantly outperform those trained on over 20 times more general language data, which underscores the importance of high-quality, specialized tokens like code or mathematics in enhancing LLMs' reasoning abilities.
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression by Jiang, Wu, Luo, Li, et al. (10 Oct), https://arxiv.org/abs/2310.06839
LongLLMLingua is a prompt compression approach designed to enhance LLMs' focus on key information, aiming to simultaneously tackle the challenges of high cost, latency, and inferior performance in long context scenarios.
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference by Luo, Tan, Huang, Li, et al. (6 Oct), https://arxiv.org/abs/2310.04378
The authors propose Latent Consistency Models, based on the concept behind Consistency Models, to accelerate the generation process of pretrained Latent Diffusion Models like Stable Diffusion, including finetuning techniques for custom image datasets.
Thought Propagation: An Analogical Approach to Complex Reasoning with Large Language Models by Yu, He, and Ying (6 Oct), https://arxiv.org/abs/2310.03965
Thought Propagation improves complex reasoning in LLMs by solving related analogous problems and applying their solutions to new problems.
Retrieval Meets Long Context Large Language Models by Xu, Ping, Wu, McAfee, et al. (4 Oct). https://arxiv.org/abs/2310.03025
The authors find that retrieval-augmentation with a 4K context window can match the performance of a finetuned LLM with a 16K context window on long-context tasks while being more computationally efficient.
Think Before You Speak: Training Language Models With Pause Tokens by Goyal, Ji, Rawat, Menon, et al. (3 Oct), https://arxiv.org/abs/2310.02226
Implementing a learnable pause token, a sequence appended to the input prefix in LLMs, which postpones output generation until the final token is processed, enhances performance when applied during both pretraining and finetuning phases.
Ring Attention with Blockwise Transformers for Near-Infinite Context by Liu, Zaharia, and Abbeel (3 Oct), https://arxiv.org/abs/2310.01889
Ring Attention introduces parallelizes the computation of self-attention across multiple devices for longer sequences to make LLMs substantially more memory efficient.
RA-DIT: Retrieval-Augmented Dual Instruction Tuning by Lin, Chen, Chen, Shi, et al. (2 Oct), https://arxiv.org/abs/2310.01352
Retrieval-Augmented Dual Instruction Tuning (RA-DIT) is a new, efficient finetuning approach as an alternative to existing retrieval-augmented LLM approaches.
Sparse Backpropagation for MoE Training by Liu, Gao, and Chen (1 Oct), https://arxiv.org/abs/2310.00811
SparseMixer introduces a scalable gradient estimator compatible with Mixture-of-Expert models' sparse computation, providing precise gradient approximations via a second-order ODE solver, which significantly accelerates training convergence in tasks like pre-training and machine translation.
GrowLength: Accelerating LLMs Pretraining by Progressively Growing Training Length by Jin, Han, Yang, and Jiang (1 Oct), https://arxiv.org/abs/2310.00576
The proposed GrowLength approach is an efficient method for accelerating the pretraining of LLMs by progressively increasing the sequence length, starting from 128 and extending up to 4096.
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!