

LLM Tuning & Dataset Perspectives

In the last couple of months, we have seen a lot of people and companies sharing and open-sourcing various kinds of LLMs and datasets, which is awesome.
However, from a research perspective, it felt more like a race to be out there first (which is understandable) versus doing principled analyses.
Now, this month, we are finally seeing a couple of studies that delve a bit into understanding LLM training, and I am excited to cover some of these projects in this newsletter.
While several interesting questions finally get answered
Do we need reinforcement learning with human feedback to align LLMs?
How good are LLMs trained on ChatGPT-imitation data?
Should we train LLMs using multiple training epochs?
...
But many questions are also left unanswered, as we will see. So, if you are someone looking for interesting research directions, there might be something interesting to learn from these papers as well.
PS: If the newsletter appears truncated or clipped, that's because some email providers may truncate longer email messages. In this case, you can access the full article at https://magazine.sebastianraschka.com.
Articles & Trends
Before we dive into some interesting, recent research projects, I want to highlight the importance of LLaMA again. Once more, Meta's LLaMA model proves to be a groundbreaking testbed for LLM research, underlining the importance of open-source models for academic research. As someone not affiliated with any big tech company, I want to acknowledge that while Meta is often downplayed compared to Microsoft/OpenAI and Google, their contributions are highly impactful for the AI research community. So far, LLaMA might be the most impactful LLM model of 2023.
Finetuning Task-Specific LLMs for Your Business Needs
Let's take a closer look at the Goat model, a finetuned 7B LLaMA model that outperforms GPT-4 on arithmetic tasks, which researchers proposed in the recent Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks paper.
Of course, the first thing to note here is that the 7B Goat model outperformed a ~75x larger 540B PaLM model and GPT-4 in zero-shot settings -- just as advertised in the paper's title.

Why is it so good? The Goat model is a special-purpose finetuned LLM that has been trained to perform well on this specific task. Usually, it goes without saying that a task-specific finetuned model outperforms a more general-purpose chatbot like GPT-4. However, I received many queries from practitioners and companies wondering whether they should or could use GPT-4 for everything. In my opinion, and as this paper underlines, well-finetuned models will always maintain an edge. (And this is of course not the first or only LLM that's been finetuned on a specific task; there are countless others. For example, FLAN, Finetuned Language Models Are Zero-Shot Learners, may be one of the most widely used ones.)
The two main ingredients for success behind Goat are
supervised finetuning of a good LLM (here: LLaMA) on a target task (versus general pretraining or instruction finetuning);
LLaMA's digit tokenization (splits each digit into an individual token).
How do we know the combination of the two is important? Point 1 is obvious: A 7B LLaMA base model is, of course, not as good as GPT-4. So, the finetuning here is necessary to make it outperform GPT-4.
However, in this case, finetuning is not enough. As the researchers pointed out, finetuned OPT, GPT-J, GPT-NeoX, and Pythia models are not nearly as good as Goat when finetuned on the same data. The researchers suggest that LLaMA's specific tokenization scheme has been an essential contributor to the success of Goat. I think tokenization is a really interesting point that is often glanced over; I look forward to seeing more ablation and comparison studies on this in the future.
How are these arithmetic tasks related to business needs?
But now, we also have to address the big elephant in the room: why use an LLM for simple arithmetic tasks when we have more capable and reliable tools like Wolfram Alpha or regular calculators?
Arithmetic tasks make for a good testbed because it's easy to generate synthetic training sets with true labels. And the generated responses are easy to evaluate as well (compared to other free-form text answers).
From Goats to Gorillas
Another recent example of finetuning LLMs to improve their specific capabilities is Gorilla: Large Language Model Connected with Massive APIs project.
Gorilla is an LLM specifically finetuned to generate API calls (something GPT-4 could be better at). The researchers used a LLaMA-7B base model and finetuned it on 1,645 API calls from Torch Hub, TensorFlow Hub, and HuggingFace. The finetuned Gorilla outperformed other LLMs not finetuned on API calls.

Making Finetuning More Efficient
The Goat model covered in the section above was finetuned using low-rank adaptation (LoRA) to make the finetuning more parameter-efficient, which allows for finetuning a 7B-parameter LLaMA model using a single 24 Gb GPU. (PS: If you want to use LoRA for finetuning LLaMA, we implement this in our lit-llama open-source repository.)
Now, how about training a 65B (instead of 7B) parameter LLaMA model on a single GPU Related to LoRA, a new method called QLoRA (short for quantized LoRA) was just published a few days ago that allows users to do that.
QLoRA (quantized low-rank adaptation) is the newest entry in the parameter-efficient LLM finetuning category. It reduces the memory requirements of a 65B LLaMA model such that it fits onto a single 48 GB GPU (like an A100). The resulting 65B Guanaco model, from quantized 4-bit training, maintains full 16-bit finetuning task performance, reaching 99.3% of the ChatGPT performance after only 24h of finetuning.

How Much Data Do We Need For Finetuning LLMs Anyways?
Getting enough data is another challenge for practitioners and researchers who want to finetune LLMs.
The recent LIMA: Less Is More for Alignment project might be a game-changer for researchers and tinkerers who want to develop capable LLMs.
In the LIMA paper, the researchers showed that a 65B LLaMA model finetuned on only 1000 examples (in a supervised fashion) is not too far behind bigger models like ChatGPT / GPT3.5. So let's have a closer look!
The researchers found that in 57% of the cases, GPT-4 is still better, but they observed that in 43% of the cases, LIMA outperforms or matches GPT-4, which sounds impressive. Or, looking at it from another angle, about half of the time, LIMA outperforms the GPT-4 predecessor ChatGPT/GPT3.5 (also referred to as DaVinci003).

An interesting question, though, is why LIMA outperforms Alpaca by such a large margin. Both are LLaMA models after supervised finetuning.
First, LIMA is based on a 65B LLaMA model, whereas the original Alpaca model is based on the 7B LLaMA base model. To make the comparison fair, the authors reproduced the Alpaca training using a 65B base model, training it on 52,000 samples as described in the original Alpaca project.
So, we may conclude that the difference is really in the quality of the training set that the authors carefully curated for LIMA, as it beats the same 65B LLaMA base model trained on 52x more data (i.e., Alpaca).
This is an exciting paper. One baseline and ablation study I am missing here is how LIMA compares to a 65B LLaMA base model finetuned with RLHF instead of supervised learning?

Hold Your LLaMAs
While the LIMA article above is very promising and exciting, there's a specific paper worth mentioning in this context: The False Promise of Imitating Proprietary LLMs.
In recent months, it's become common practice to finetune LLMs on data derived from other LLMs, such as ChatGPT. And in this recent study, researchers found that crowd workers rate these so-called imitation models highly. But it turns out that these imitation models only tend to mimic the style of the upstream LLMs on whose data they were trained on, not their factuality.

Now, the LIMA paper does not use imitation data. Instead, it uses a carefully curated dataset. However, it's still worth highlighting that evaluation methods can sometimes seem to be too good to be true, and there is an increased need for more and better benchmarks.
New Alternatives to Reinforcement Learning With Human Feedback
Not too long ago, we talked about aligning LLMs using reinforcement learning with human feedback (RLHF) -- this is how ChatGPT was trained, for example. If you are interested in more explanations and references, also see

Then, in recent months, supervised finetuning became the new norm when finetuning LLMs (e.g., supervised finetuning was also used in the LIMA paper above.)
Now, Direct Preference Optimization (DPO) is another new alternative to reinforcement learning with human feedback with Proximal Policy Optimization (PPO), which is used for instruction-finetuning models like ChatGPT. Here, the researchers show that the cross-entropy loss for fitting the reward model in RLHF can be used directly to finetune the LLM. According to their benchmarks, it's more efficient to use DPO and is often also preferred over RLHF/PPO regarding response quality.

Something on my wishlist is also to see how well it compares to RLHF regarding dataset efficiency. It would be an interesting future study.
Can We Improve LLM Base Models By Pretraining for Multiple Epochs?
So far, we've only talked about finetuning. The finetuned models all require a pretrained base model. So, it's natural to ask how we can create better base models as well.
One question I often asked myself is What happens if we train LLMs for multiple epochs? (Here, epoch means one pass over the training set). It's quite common to train classic machine learning models and deep neural networks, as well as the latest vision transformers for hundreds of epochs, so what happens if we do the same for LLMs, which are commonly trained for only a single epoch?
This question finally got answered in the new To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis.
But first, given the enormous amounts of data, why would we want to consider training LLMs for multiple epochs? It turns out that high-quality text data on the internet is slower than required. Also, if copyrighted material is removed in the future, this could even shrink the datasets further. So, why not train for multiple epochs on existing data?
The result is that training for multiple epochs leads to overfitting.
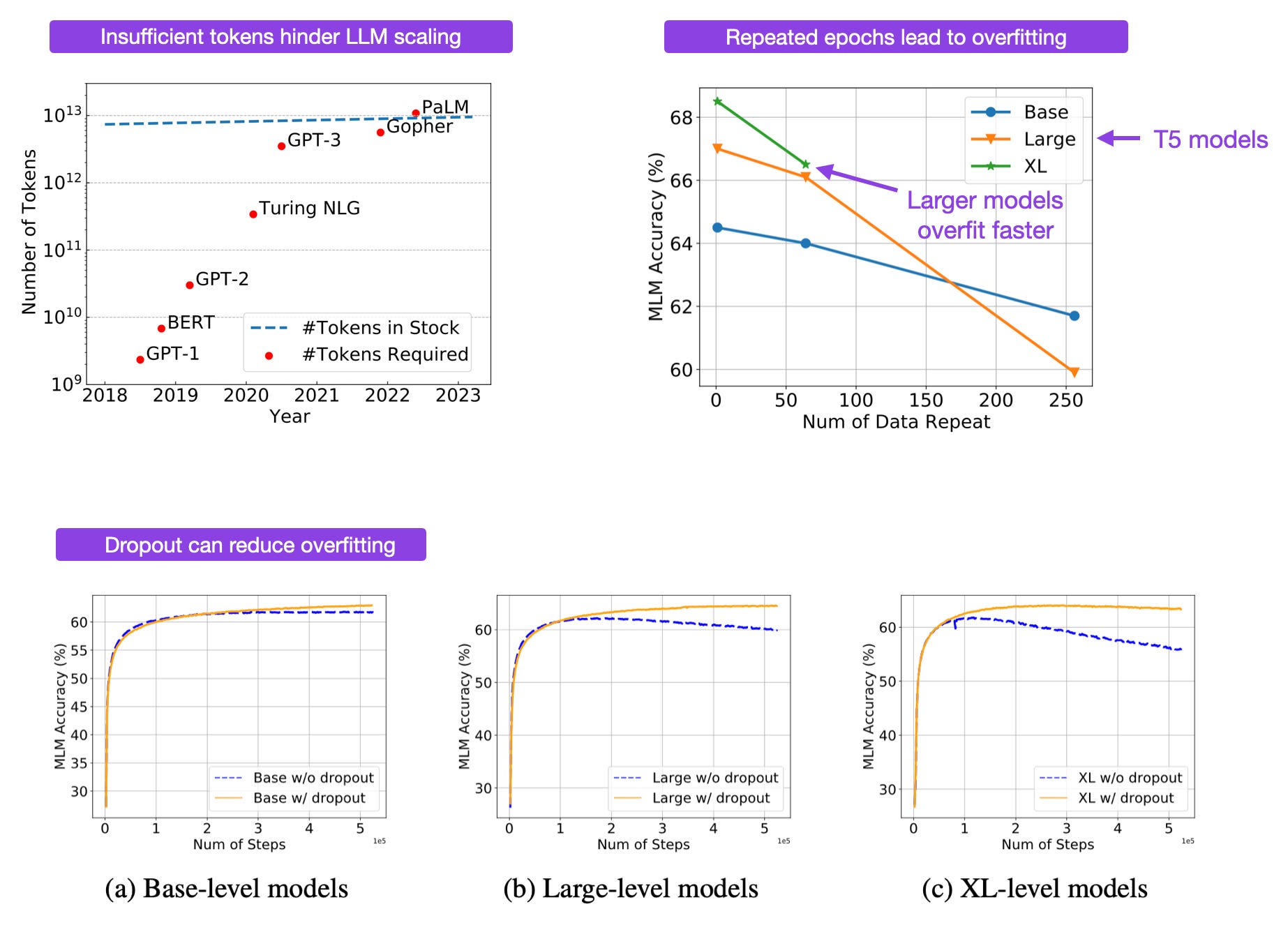
Another interesting takeaway: dropout can help reduce overfitting (no surprise), but other techniques, such as weight decay, can't, according to the authors. As a side note: popular large models like LLaMA, Gopher, Chinchilla, GPT-3, and PaLM did not use dropout, since it can slow down learning.
Three Open Questions
How about repeating only the high-quality data like LIMA, which we discussed above? That's an interesting idea; intuitively, this makes sense and could help. However, the bad news is that it probably doesn't help much. The researchers conducted a related experiment with Wikipedia data (versus C4) where they regarded Wikipedia as high-quality (which I agree with). However, it turned out that there was a similar degradation when repeating the Wikipedia data for multiple epochs.
Does data augmentation help? Several methods for text augmentation exist, so that's another good question to study in the future! By the way, some of these techniques include back translation, synonym replacement, sentence shuffling, and using synthetic data (e.g., GPT-4 ), which I summarized in my Machine Learning Q and AI book.
Lastly, what does it look like for finetuning (instead of pretraining)? Do the same rules apply? (In my experience, training for a small number of epochs, like 3-5, is worthwhile, but I'd like to see a principled study on this one day.)
More Efficient Vision Transformers
This is already a long section, but there are also some interesting developments on the computer vision front that I wanted to briefly share below.
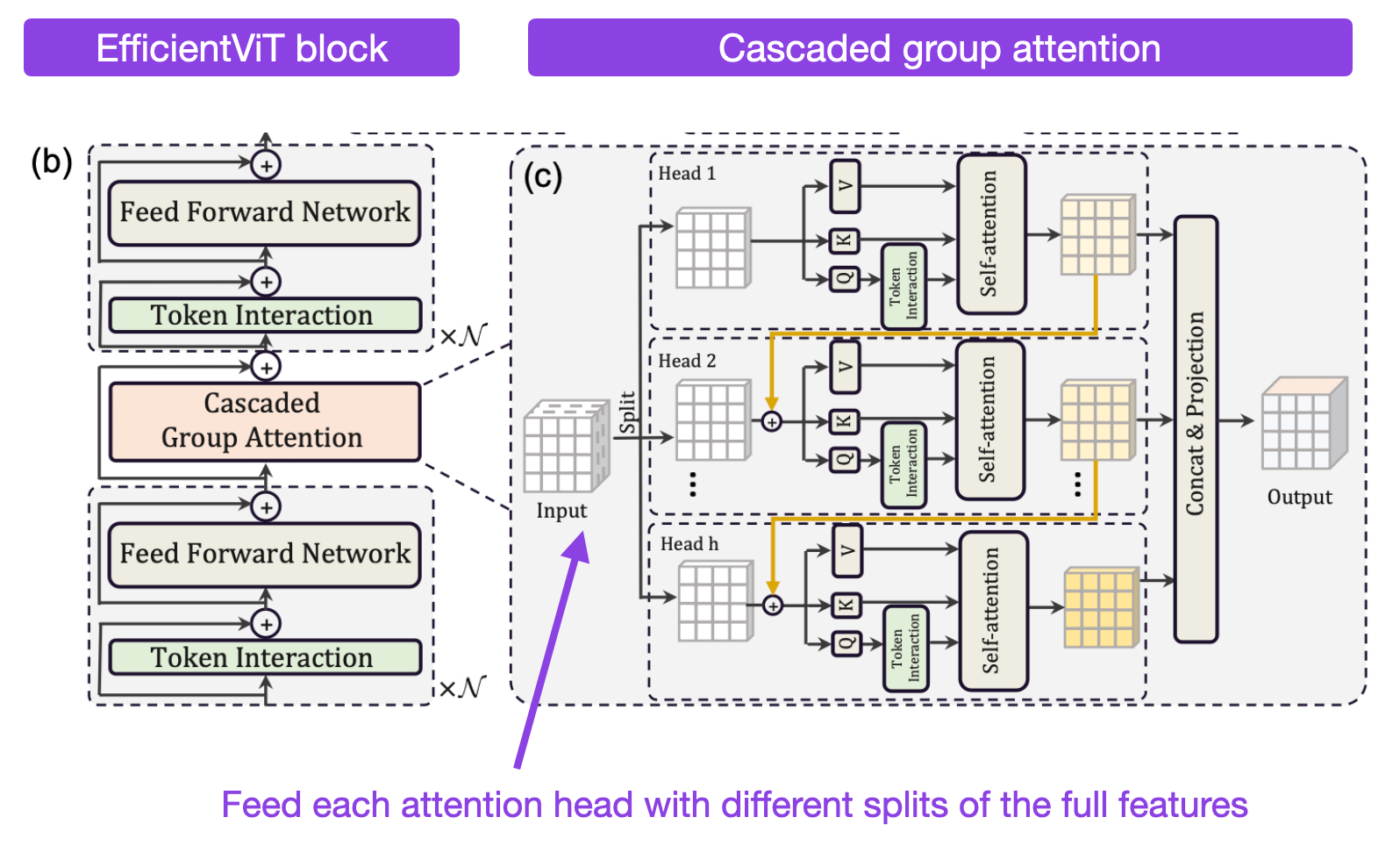
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention (https://arxiv.org/abs/2305.07027, 11 May 2023)
EfficientViT is a new vision transformer that provides a good trade-off between speed and accuracy. It outperforms other efficient architectures like MobileNetV3 and MobileViT while being substantially faster. The researchers achieve this with cascaded group attention, which reduces redundancy in the multi-head self-attention layers by feeding each attention head with different splits of the full features (analogous to group convolutions).
Getting ViT in Shape: Scaling Laws for Compute-Optimal Model Design (https://arxiv.org/abs/2305.13035, 22 May 2023)
Previously, studies have focused on the optimal dataset sizes and model sizes in terms of parameter numbers. Here, researchers propose methods to infer compute-optimal model shapes, for example, width and depth. The result is a vision transformer that outperforms models twice its size. Moreover, while the smaller compute-optimal model was trained using the same compute resource budget, it achieved less than half the inference cost of its larger counterpart.
Deep Neural Networks for Ordinal Regression
Last but not least, I wanted to share one of my own papers, which just got accepted this week: Deep Neural Networks for Rank-Consistent Ordinal Regression Based On Conditional Probabilities.
This paper is about a new loss function to turn any neural network classifier (convolutional network, recurrent neural network, or transformer) into a model for ordinal data. What is ordinal data? For example, think about rating scales like the Amazon star rating. Or disease classification with ordered categories: none < mild < moderate < severe.
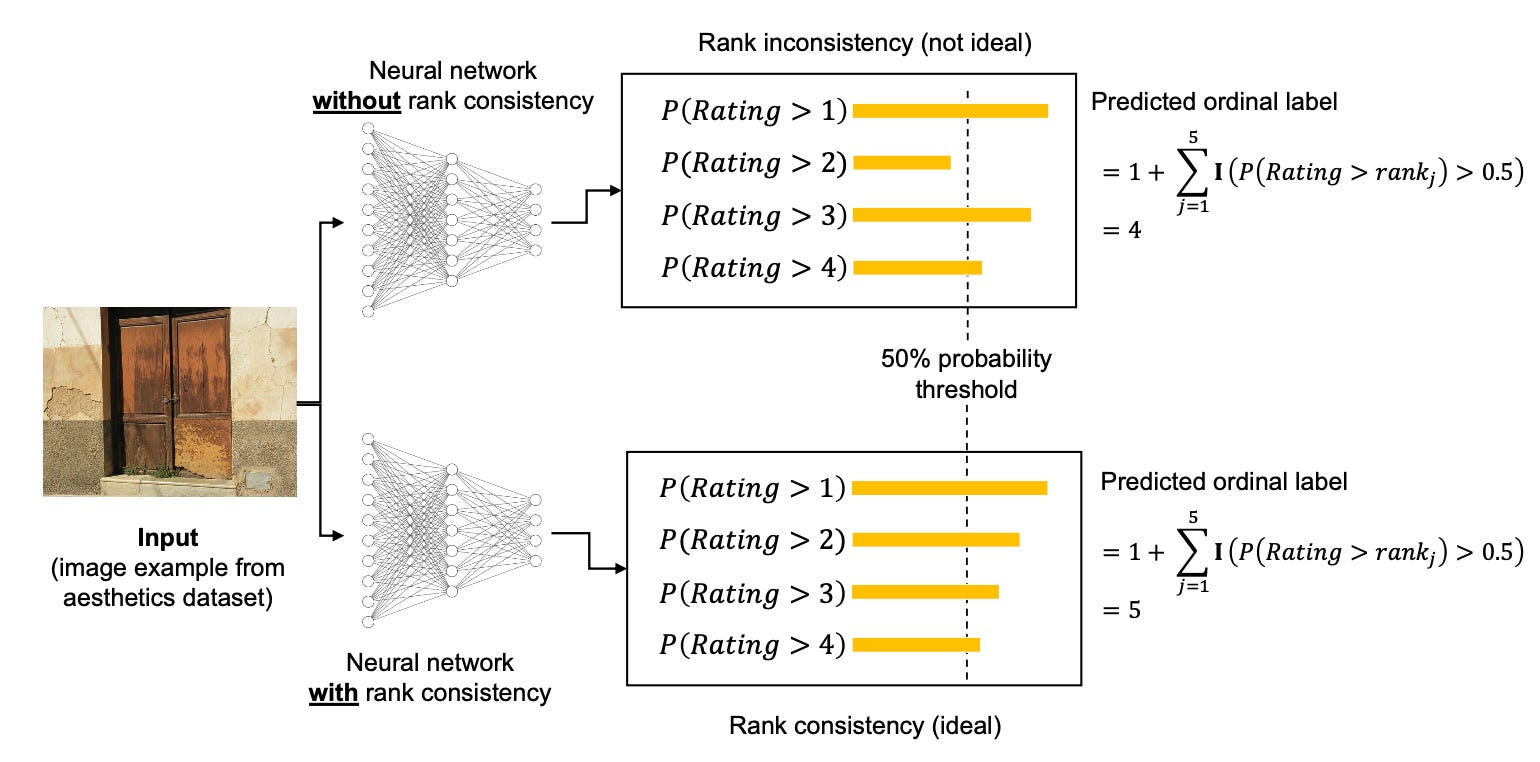
Of course, I also have an LLM example for this.
Research Highlights in Three Sentences or Less
As always, there are many more interesting papers that I stumbled upon this month. And of course, I can't share them all in this already very long newsletter. So, similar to last time, I'll share a few more research highlights in a separate list next week. In the meantime, here's the previous list in case you are curious:

AI Risk & Regulation
There is no way around discussing the latest AI risk and regulation updates. The current debates are centered around several hotly discussed topics: does AI pose existential risks, can AI cause other types of harms and should be regulated, how should AI be regulated to mitigate risks and harms, and in how far is it okay to train AI applications on internet data concerning respecting copyrighted data.
Several AI researchers and experts weighed in on the debate around AI risks. Some of the most prominent and accomplished AI researchers, such as Yann LeCun and Kyunghyun Cho, and Andrew, dismiss AI related concerns:
Titans of AI Andrew Ng and Yann LeCun oppose call for pause on powerful AI systems
Top AI researcher dismisses AI ‘extinction’ fears, challenges ‘hero scientist’ narrative
Meanwhile, other prominent researchers, including Geoffrey Hinton and Yoshua Bengio, voice concerns:
Furthermore, OpenAI CEO Sam Altman recommended regulating AI at a US Senate hearing. And as a response to the EU regulation plans, he added "We will try to comply, but if we can’t comply we will cease operating." (The dramatized version of this comment says that Altman is suggesting that OpenAI may leave the European market if the EU regulates AI.)
Lastly, Japan just stated that it would not enforce copyrights on data used for training AI models.
Quote of the Month
“Regulate us in a way that will make it hard for others to compete”
-- Michael Bronstein describing or paraphrasing OpenAI's CEO Sam Altman after a US senate hearing.
Deep Learning Fundamentals: Improving Training Performance and What Comes Next
The final two units of my Deep Learning Fundamentals -- Learning Deep Learning Using a Modern Open-Source Stack are now finally out!
Unit 9 covers Techniques for Speeding Up Model Training
Unit 10 concludes the course by suggesting Next Steps After AI Model Training
For instance, in these two units, you'll learn how to train PyTorch models faster using mixed-precision training, distributed multi-GPU training paradigms, model compilation, and more.

My goal with this course was to provide a modern take on learning deep learning & AI using open-source libraries. Moreover, I tried to be concise but also go beyond the typical topics covered in university classes.
What was also particularly important to me was to also include important topics that are super relevant in practice: learning rate schedulers, mixed-precision training, distributed multi-GPU training strategies, and more!
If you have been following along, I hope you enjoyed the journey from backpropagation to implementing computer vision models and LLMs in PyTorch!
Making this course was hard work but truly a pleasure! If you liked it and got something useful out of it, I'd be happy to hear! Please feel free to ask any questions on the Discussion page on GitHub. And I would also really appreciate it if you could share it with your colleagues.
Open Source Highlights
GPT4All -- A free-to-use, locally running, privacy-aware chatbot
GPT4All is a ChatGPT-like chat book that runs on a local computer -- no GPU or internet required. Based on the technical report shared in the GPT4All GitHub repository, the model is a 7B parameter LLaMA model finetuned on roughly one million prompt-response pairs generated via the GPT-3.5-Turbo OpenAI API using low-rank adaptation (LoRA).
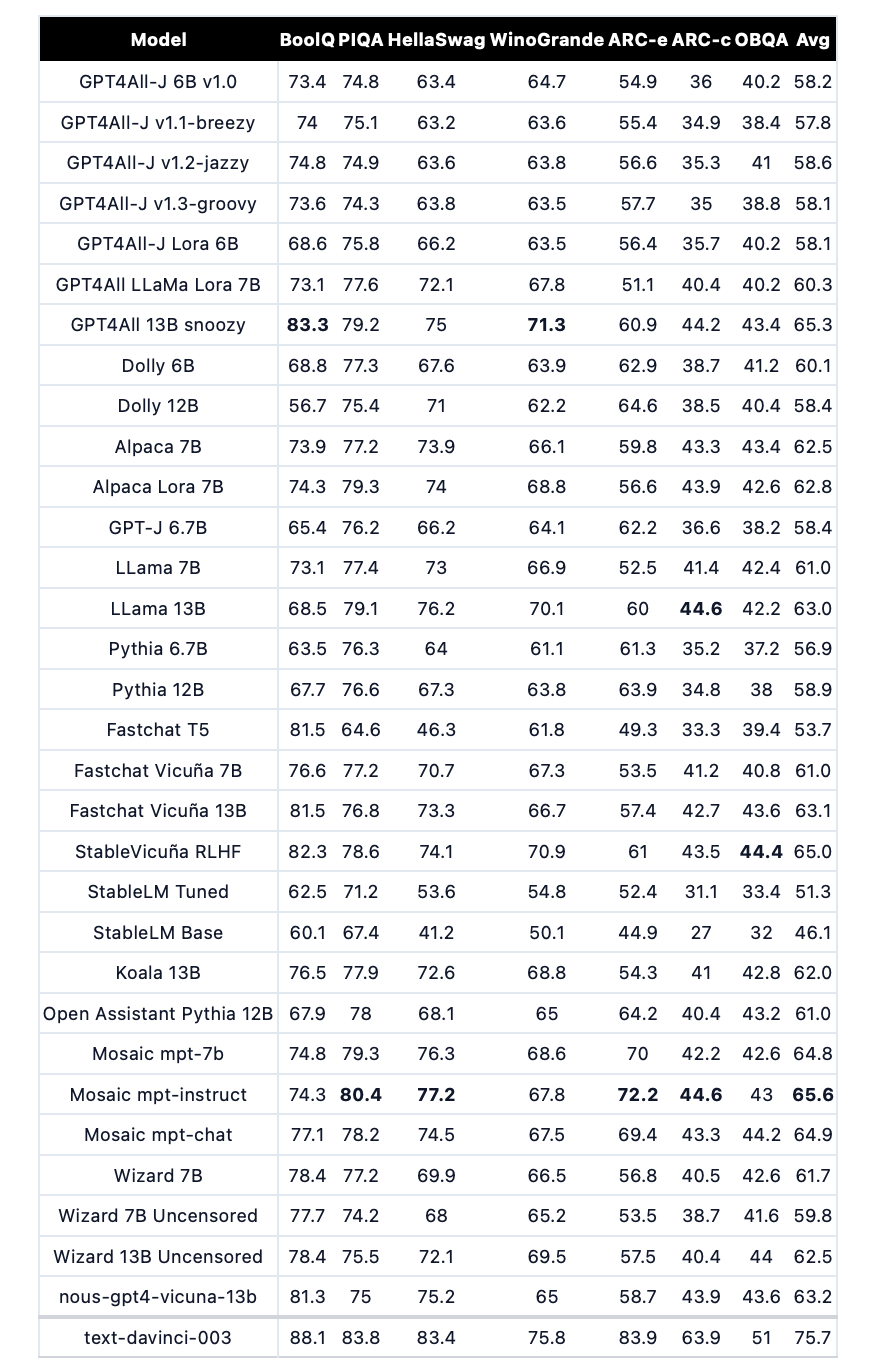
While the GPT4All program might be the highlight for most users, I also appreciate the detailed performance benchmark table below, which is a handy list of the current most-relevant instruction-finetuned LLMs.
Falcon 40-B -- A New LLM With a License Controversy
The Technology Innovation Institute developed and shared the 40B Falcon LLM, which outperforms StableLM, LLaMA, and MPT, according to the OpenLLM Leaderboard.
At first, Falcon 40-B featured a controversial license that required users to disclose financial information with the developers of Falcon and share 10% of the revenue when exceeding 1 million dollars. This license started a heated debate on social media, so the developers reversed course and eventually changed the license to a regular Apache 2.0 open-source license one week later.
In my opinion, it's definitely fair for developers to ask to be compensated for their hard work. However, I think the fact that it was branded as "open source" was why the heated discussion arose.
Also, the license was unnecessarily complicated, and the disclosure of financial information with the Falcon developers would have been a no-go for most companies and users. In my opinion, a fixed one-time or subscription fee would have been a more user-friendly way to use the model. However, open-sourcing the model under Apache 2.0 is of course, even nicer, and that's definitely good news!
PS: Falcon-40B is now also supported in lit-parrot (lit-parrot is a new sister-repo of the lit-llama repo for non-LLaMA LLMs.)

A New Speech-To-Text Model for 1000's of Languages
As some of you may know, I love OpenAI's open-source Whisper model, which I use to generate the subtitles for all my lecture videos.
There's now an alternative available by Meta AI called MMS. Impressively, MMS covers ~1,100 languages (for comparison, OpenAI's Whisper model supports 99). According to the benchmarks in the accompanying paper, the MMS model outperforms Whisper on all 54 languages in the FLEURS benchmark that both MMS and Whisper cover. The model is released under a permissible CC-BY-NC 4.0 license and is available here on GitHub.

Watermark 2.4 now with GPU information
Watermark is a small open-source library that I have been developing for many years. I (and many others) use it to print the compute and package information for reproducibility when developing and sharing Python scripts and Jupyter notebooks. Long story short, the recent 2.4 version now has a --gpu flag to display GPU hardware. You can install or update it to the most current version via the following command:
pip install watermark --upgrade
--gpu flag, https://github.com/rasbt/watermarkThis magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Delightful to read as always. I enjoy the concise summarizations of recent AI development, especially in this super fast pace era. Also thank you for sharing your thoughts on a lot of these problems. This opens up a lot of discussions and potential research areas.
Great insights on this AI issue. While the readings is a well fit-purpose for researchers and alike to allow replicating work, I was wondering in some sort of as an extended arm on these LLMs topics, if a pragmatic approach on how to implement all of these papers/research work via applications (streamlit, gradio, etc., just to name a few) can be covered as well with practical examples.