

A Dream of Spring for Open-Weight LLMs: 10 Architectures from Jan-Feb 2026
A Round Up And Comparison of 10 Open-Weight LLM Releases in Spring 2026

If you have struggled a bit to keep up with open-weight model releases this month, this article should catch you up on the main themes.
In this article, I will walk you through the ten main releases in chronological order, with a focus on the architecture similarities and differences:
Arcee AI’s Trinity Large (Jan 27, 2026)
Moonshot AI’s Kimi K2.5 (Jan 27, 2026)
StepFun Step 3.5 Flash (Feb 1, 2026)
Qwen3-Coder-Next (Feb 3, 2026)
z.AI’s GLM-5 (Feb 12, 2026)
MiniMax M2.5 (Feb 12, 2026)
Nanbeige 4.1 3B (Feb 13, 2026)
Qwen 3.5 (Feb 15, 2026)
Ant Group’s Ling 2.5 1T & Ring 2.5 1T (Feb 16, 2026)
Cohere’s Tiny Aya (Feb 17, 2026)
Update 1: Sarvam 30B and 105B (Mar 6, 2026)
(PS: DeepSeek V4 will be added once released.)
Since there’s a lot of ground to cover, I will be referencing my previous The Big LLM Architecture Comparison article for certain technical topics (like Mixture-of-Experts, QK-Norm, Multi-head Latent Attention, etc.) throughout this article for background information to avoid redundancy in this article.
1. Arcee AI’s Trinity Large: A New US-Based Start-Up Sharing Open-Weight Models
On January 27, Arcee AI (a company I hadn’t had on my radar up to then) began releasing versions of their open-weight 400B Trinity Large LLMs on the model hub, along with two smaller variants:
Their flagship large model is a 400B param Mixture-of-Experts (MoE) with 13B active parameters.
The two smaller variants are Trinity Mini (26B with 3B active parameters) and Trinity Nano (6B with 1B active parameters).
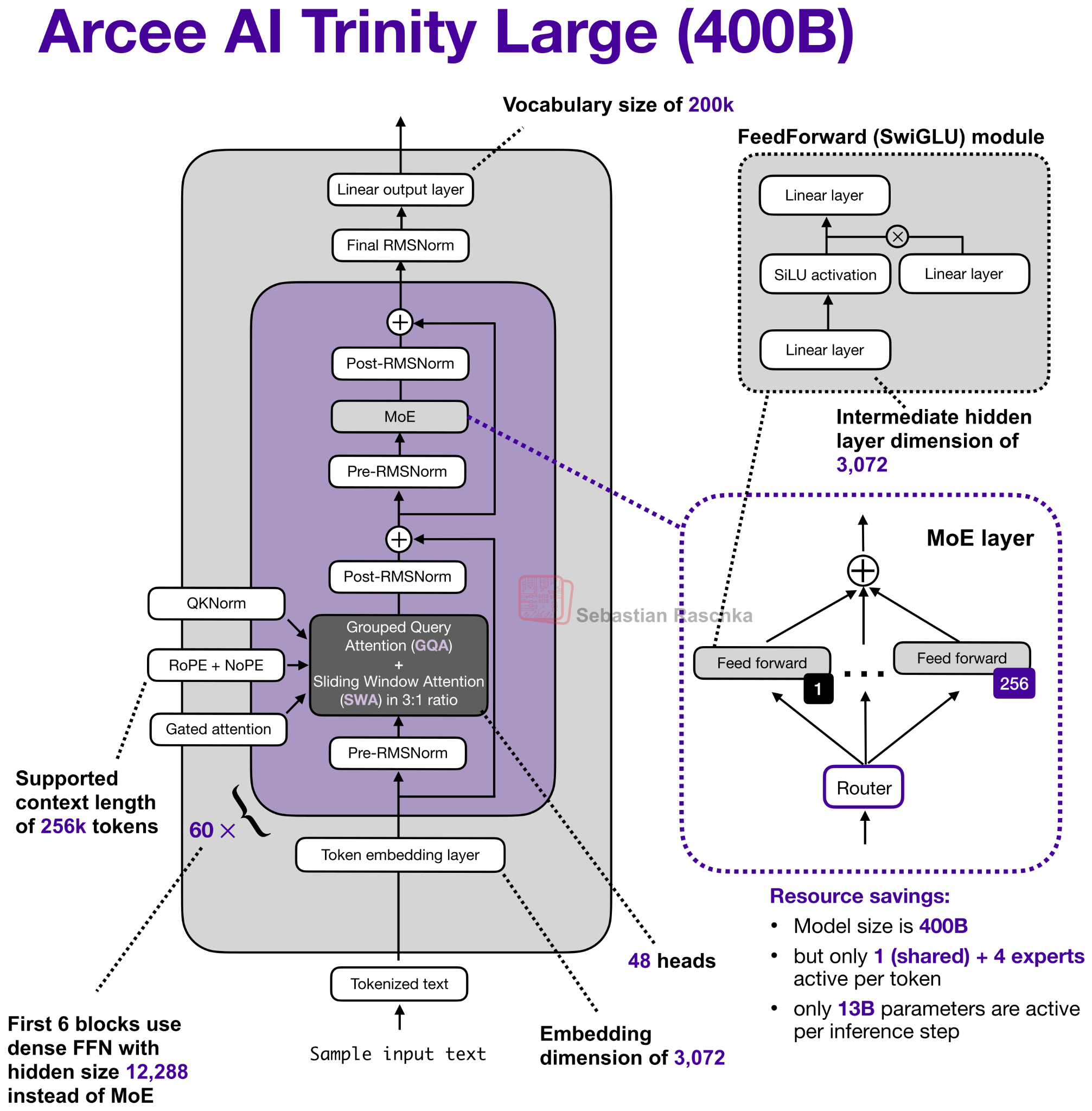
Along with the model weights, Arcee AI also released a nice technical report on GitHub (as of Feb 18 also on arxiv) with lots of details.
So, let’s take a closer look at the 400B flagship model. Figure 2 below compares it to z.AI’s GLM-4.5, which is perhaps the most similar model due to its size with 355B parameters.
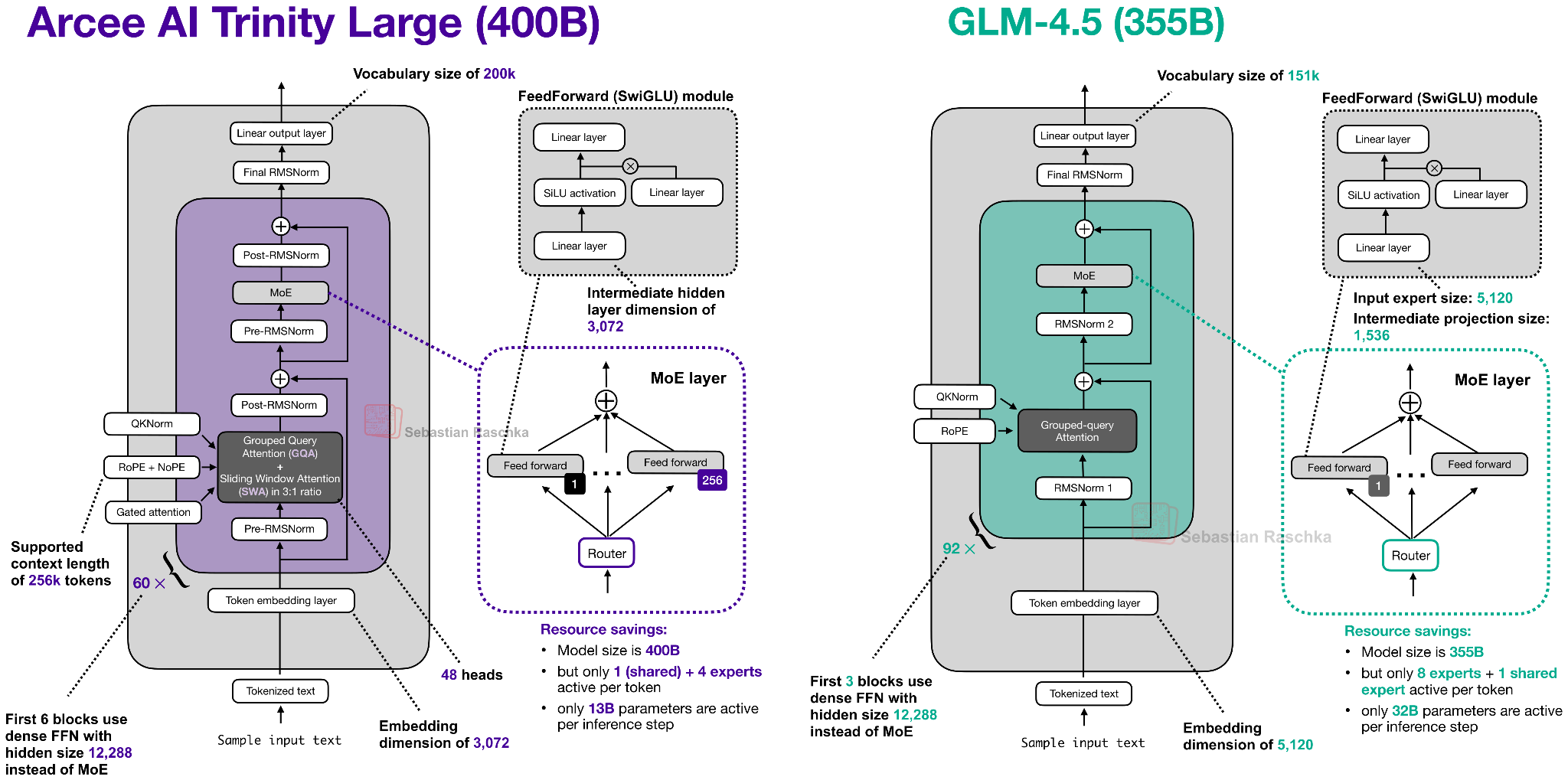
As we can see in the Trinity and GLM-4.5 comparison, there are several interesting architectural components added to the Trinity model.
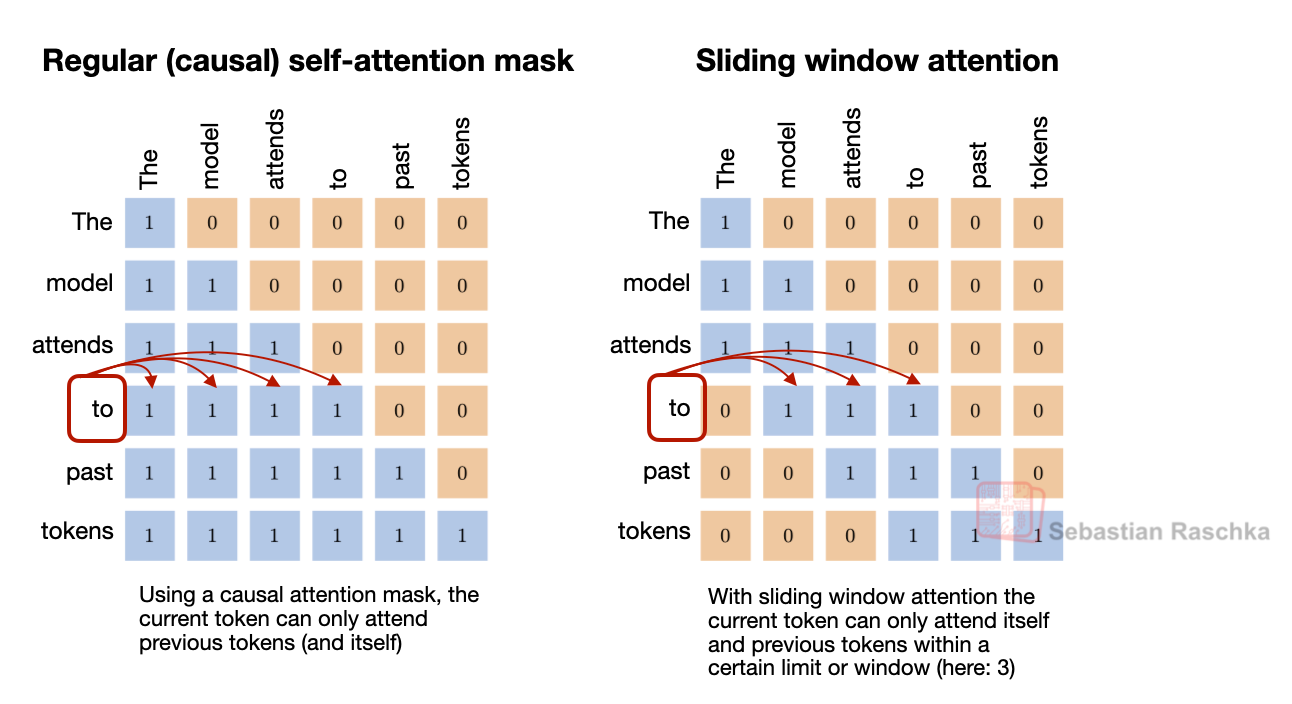
First, there are the alternating local:global (sliding window) attention layers (SWA) like in Gemma 3, Olmo 3, Xiaomi MiMo, etc. In short, SWA is a type of sparse (local) attention pattern where each token attends only to a fixed-size window of t recent tokens (for example, 4096) instead of attending to the entire input (which could be up to n=256,000 tokens). This reduces the per-layer regular attention cost from O(n²) to roughly O(n·t) for sequence length n, which is why it is attractive for long-context models.
But instead of using the common 5:1 local:global ratio that Gemma 3 and Xiaomi used, the Arcee team opted for a 3:1 ratio similar to Olmo 3, and a relatively large sliding window size of 4096 (also similar to Olmo 3).
The architecture also uses QK-Norm, which is a technique that applies RMSNorm to the keys and queries to stabilize training (as shown in Figure 4 below), as well as no positional embeddings (NoPE) in the global attention layers similar to SmolLM3.
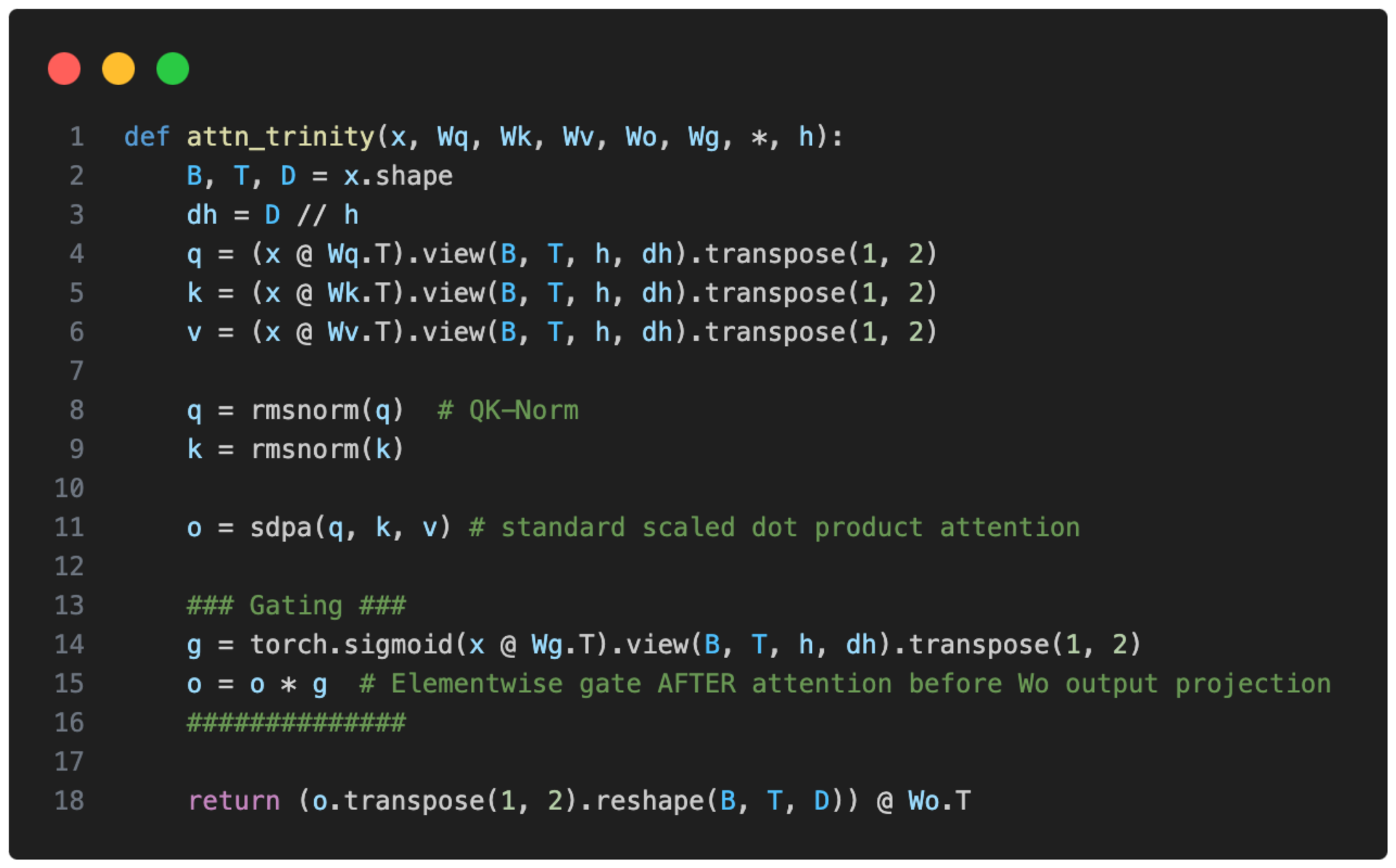
Trinity also has a form of gated attention. It’s not a full-blown Gated DeltaNet but it uses a similar gating as in the attention mechanism in Qwen3-Next.
I.e., the Trinity team modified the standard attention by adding elementwise gating to the scaled dot-product before the output linear projection (as shown in the figure below), which reduces attention sinks and improves long-sequence generalization. Additionally, it also helped with training stability.
Also, the Trinity technical report showed that the modeling performance of the Trinity Large and GLM-4.5 base models are practically identical (I assume they didn’t compare it to more recent base models because many companies only share their fine-tuned models these days.)
You may have noticed the use of four (instead of two) RMSNorm layers in the previous Trinity Large architecture figure which looks similar to Gemma 3 at first glance.
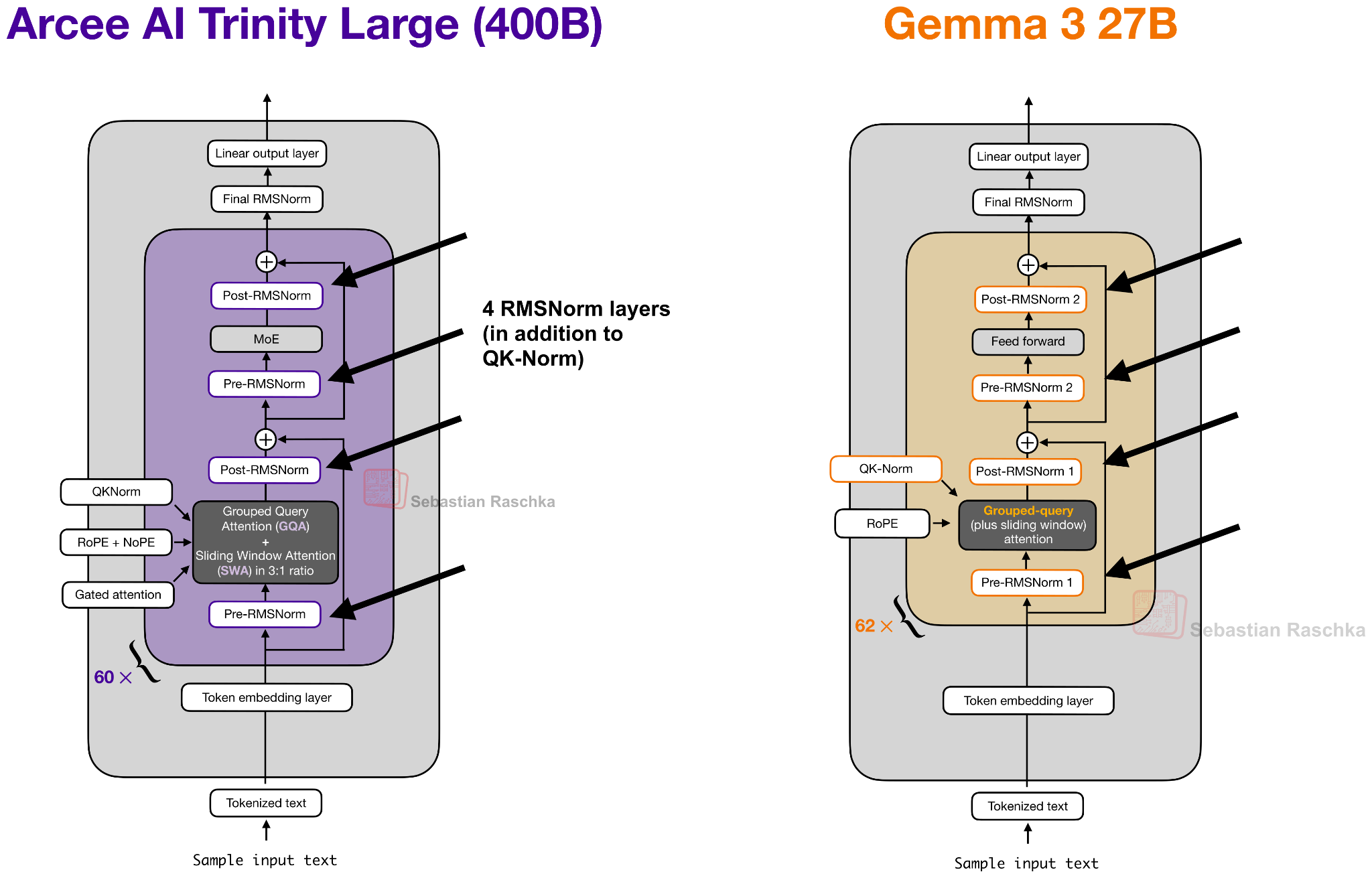
Overall, the RMSNorm placement looks like a Gemma 3-like RMSNorm placement, but the twist here is that the gain of the second RMSNorm (in each block) is depth-scaled, meaning it’s initialized to about 1 / sqrt(L) (with L the total number of layers). So, early in training, the residual update starts small and grows as the model learns the right scale.
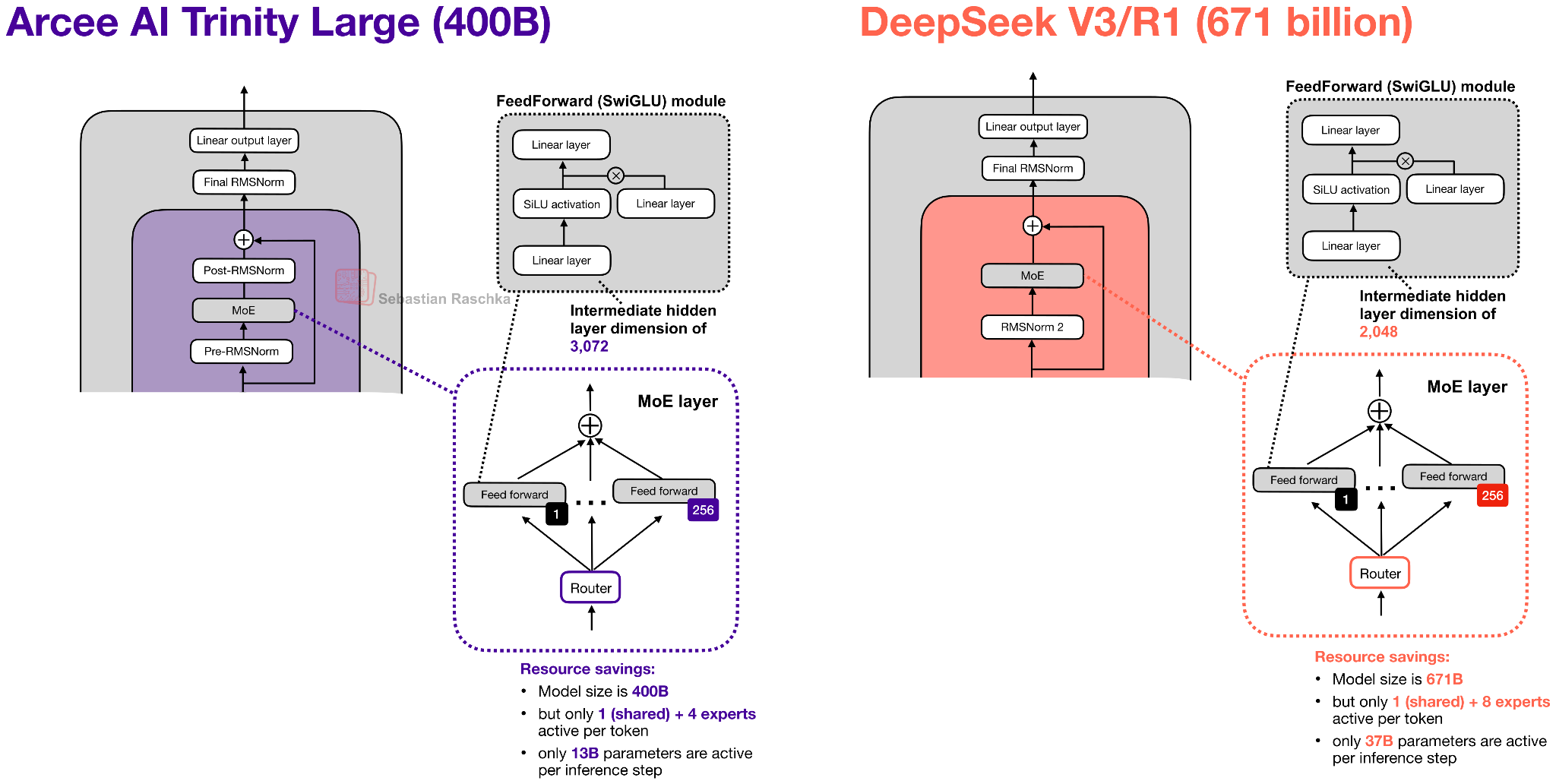
The MoE is a DeepSeek-like MoE with lots of small experts, but made it coarser as that helps with inference throughput (something we have also seen in Mistral 3 Large when they adopted the DeepSeek V3 architecture).
Lastly, there are some interesting details on the training improvements (a new MoE load-balancing strategy and another using the MuOpt optimizer), but since this is a mainly an architecture article (and there are many more open-weight LLMs to cover), these details are out of scope.
2. Moonshot AI’s Kimi K2.5: A DeepSeek-Like Model at a 1-Trillion-Parameter Scale
While Arcee Trinity essentially matched the modeling performance of the older GLM-4.5 model, Kimi K2.5 is an open-weight model that set a new open-weight performance ceiling at the time of its release on Jan 27.
Impressively, according to their own benchmarks in their detailed technical report, it was on par with the leading proprietary models at the time of its release.
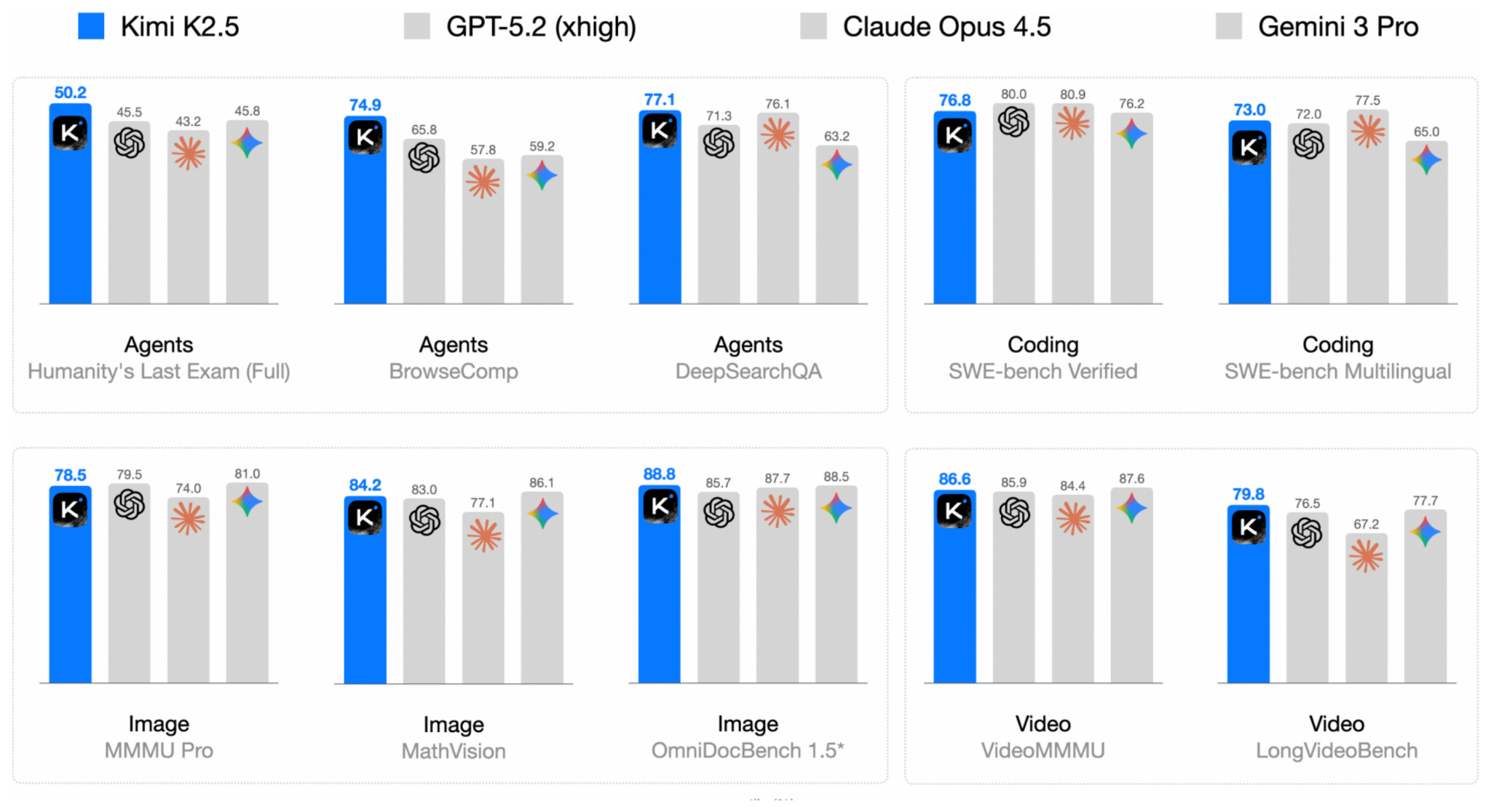
The good modeling performance is no surprise when compared to, e.g., Arcee Trinity or GLM-4.5 covered earlier, since (similar to its K2 predecessor), Kimi K2.5 is a 1-trillion-parameter model and thus 2.5x larger than Trinity and 2.8x larger than GLM-4.5.
Overall, the Kimi K2.5 architecture is similar to Kimi K2, which, in turn, is a scaled-up version of the DeepSeek V3 architecture.
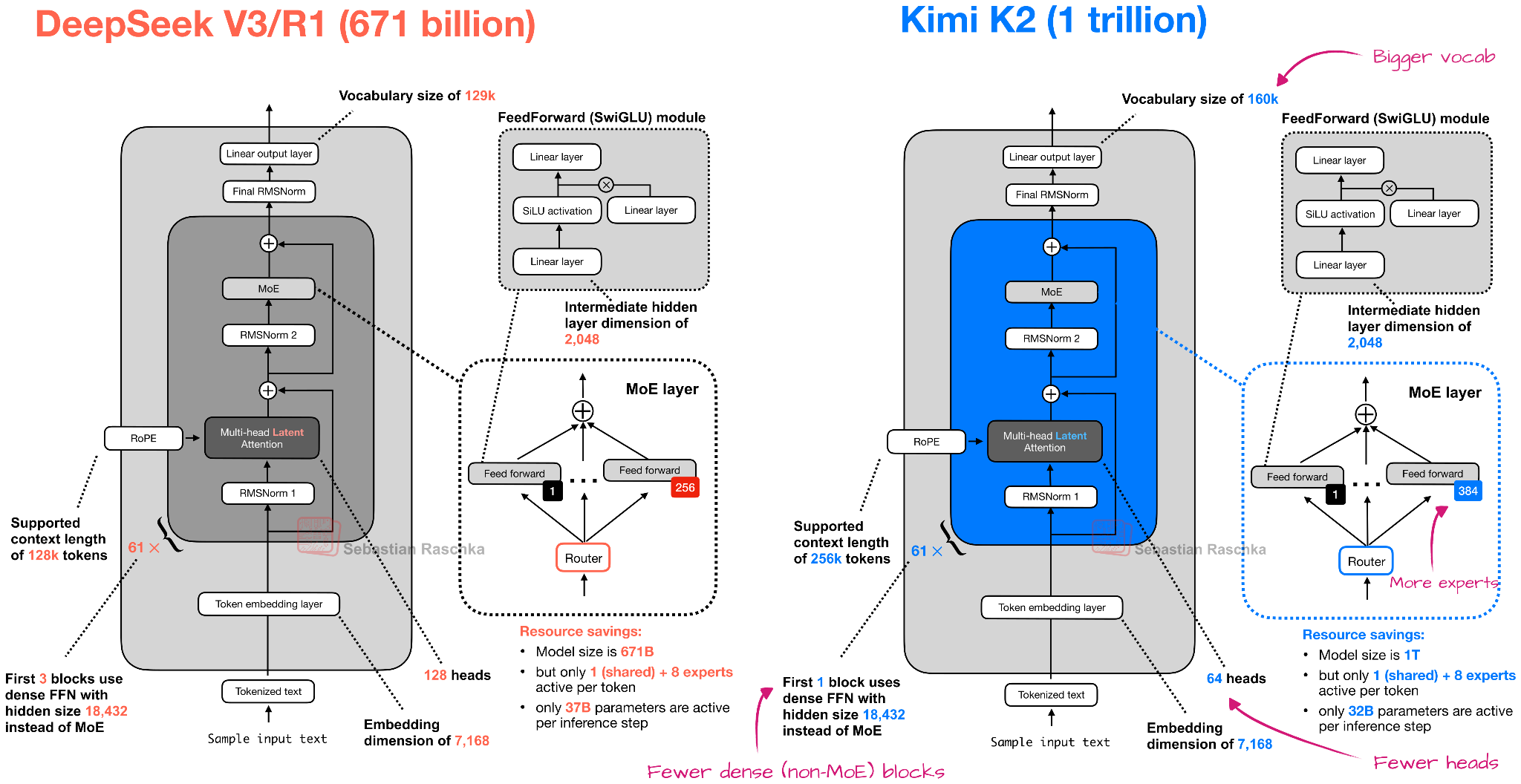
However, K2 was a pure text model, and Kimi K2.5 is now a multimodal model with vision support. To quote from the technical report:
> Kimi K2.5 is a native multimodal model built upon Kimi K2 through large-scale joint pre-training on approximately 15 trillion mixed visual and text tokens.
During the training, they adopted an early fusion approach and passed in the vision tokens early on alongside the text tokens, as I discussed in my older Understanding Multimodal LLMs article.
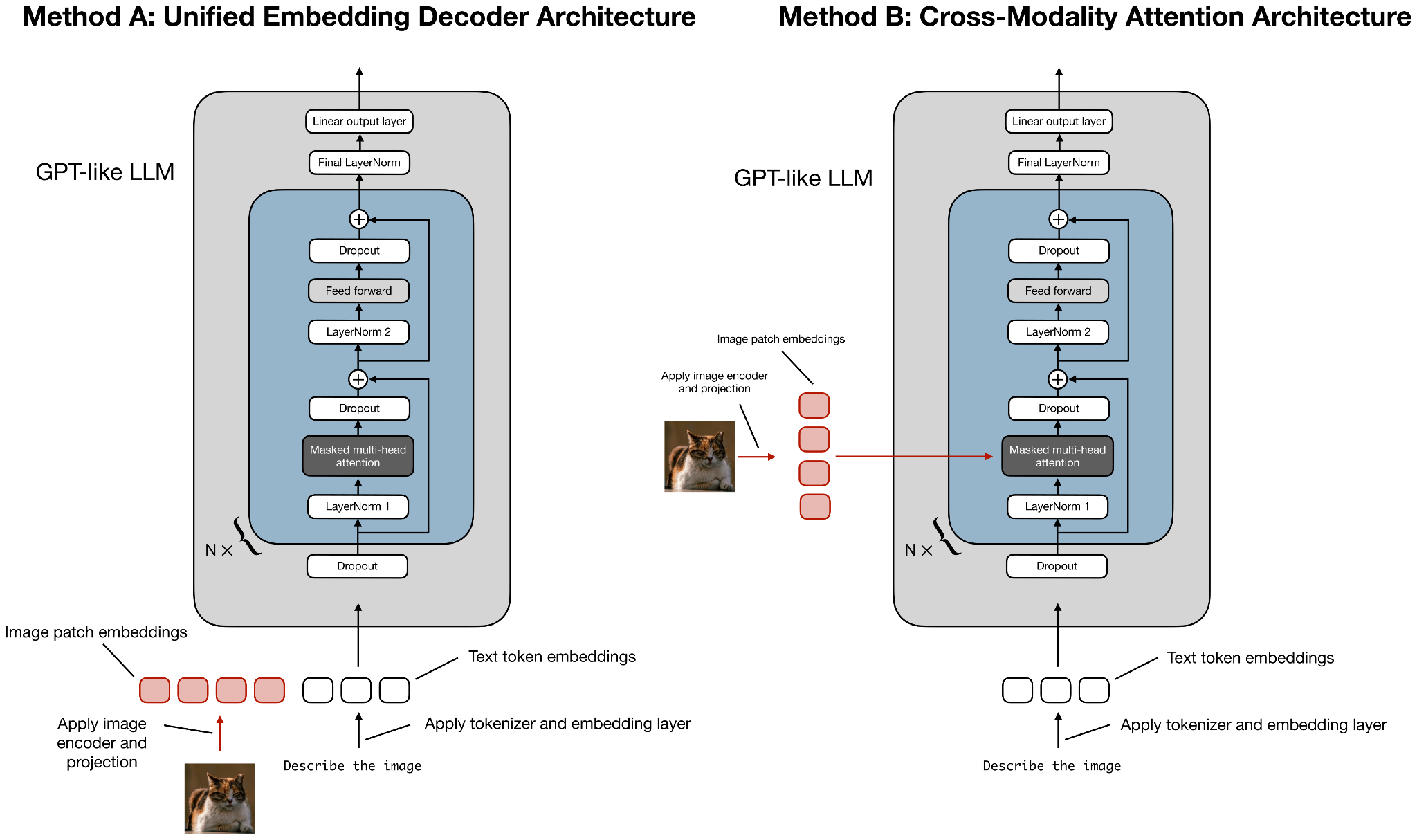
Side note: In multimodal papers, “early fusion” is unfortunately overloaded. It can mean either
1. When the model sees vision tokens during pre-training. I.e., vision tokens are mixed in from the start (or very early) of pre-training as opposed to later stages.
2. How the image tokens are combined in the model. I.e., they are fed as embedded tokens alongside the text tokens.
In this case, while the term “early fusion” in the report specifically refers to point 1 (when the vision tokens are provided during pre-training), point 2 is also true here.
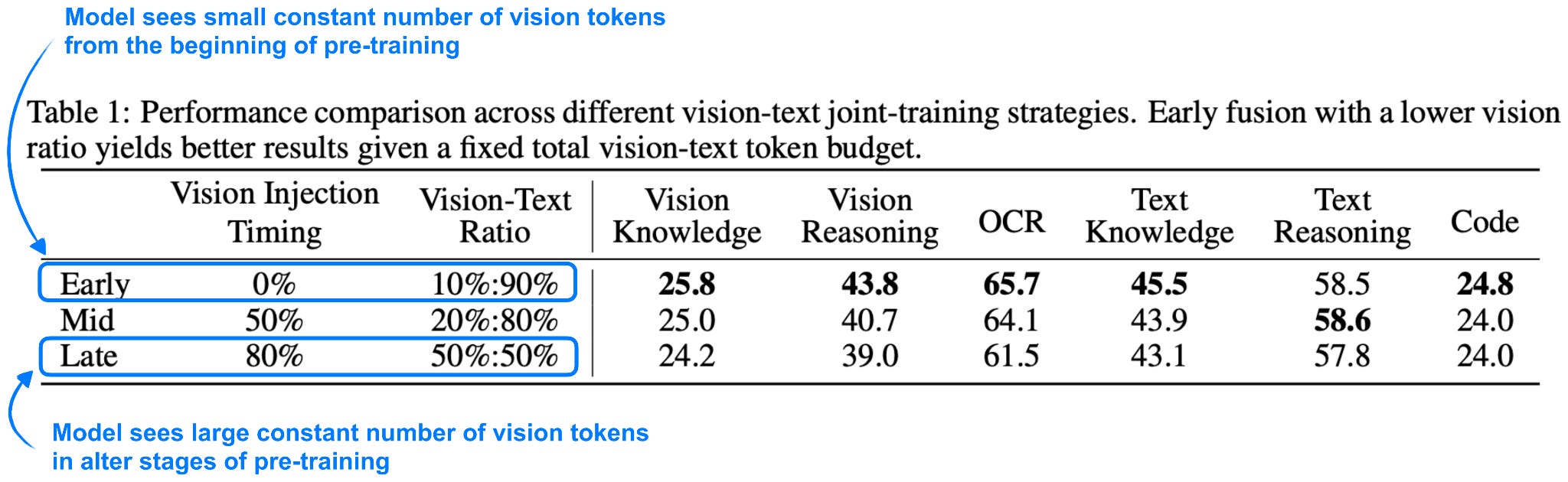
Furthermore, regarding point 1, the researchers included an interesting ablation study showing that the model benefits from seeing vision tokens early in pre-training, as shown in the annotated table below.
3. StepFun’s Step 3.5 Flash: Good Performance at Great Tokens/Sec Throughput
I have to admit that I haven’t had the Step models on my radar yet. This one caught my attention due to its interesting size, detailed technical report, and fast tokens/sec performance.
Step 3.5 Flash is a 196B parameter model that is more than 3x smaller than the recent DeepSeek V3.2 model (671B) while being slightly ahead in modeling performance benchmarks. According to the Step team, Step 3.5 Flash has a 100 tokens/sec throughput at a 128k context length, whereas DeepSeek V3.2 has only a 33 tokens/sec throughput on Hopper GPUs, according to the data on the Step model hub page.
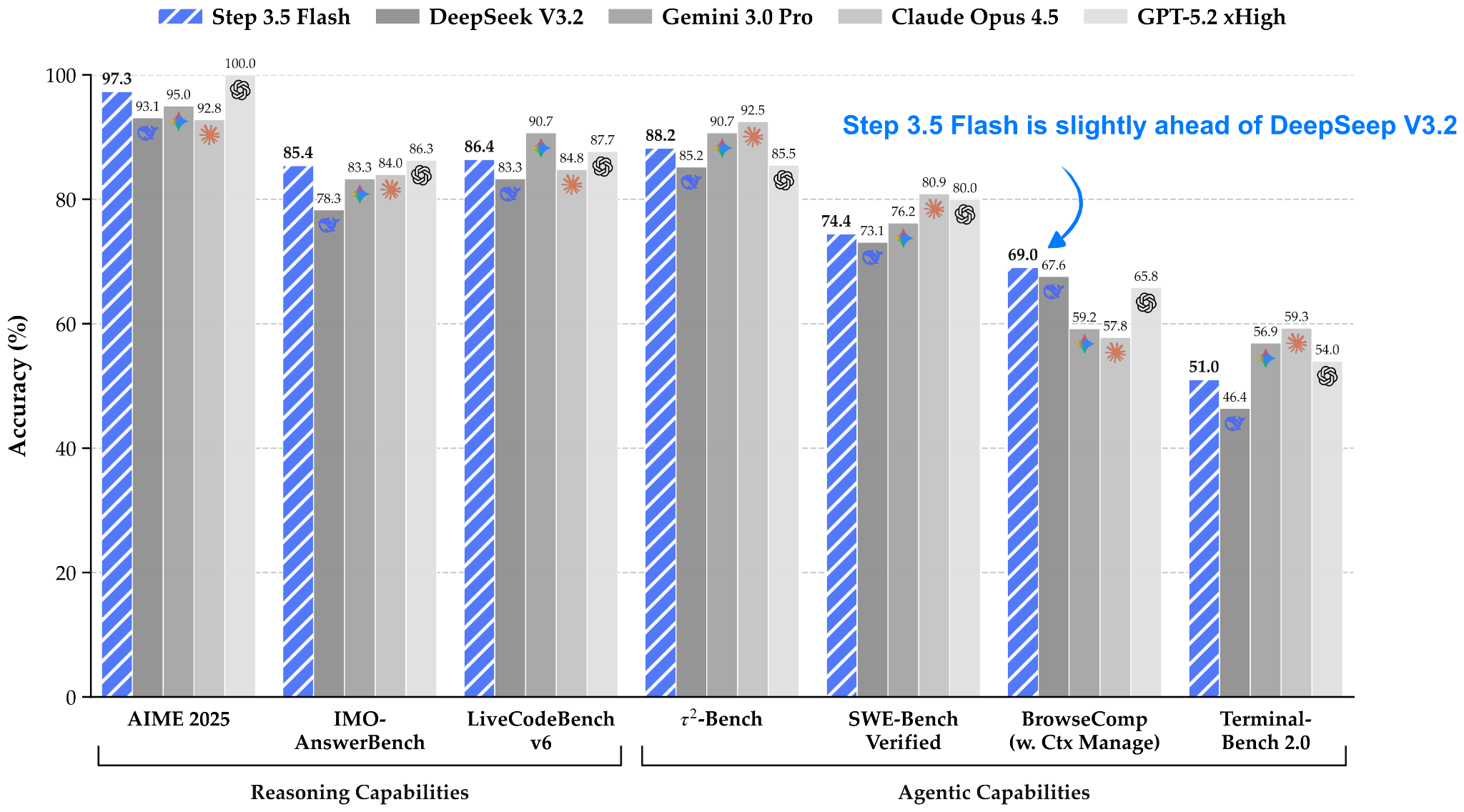
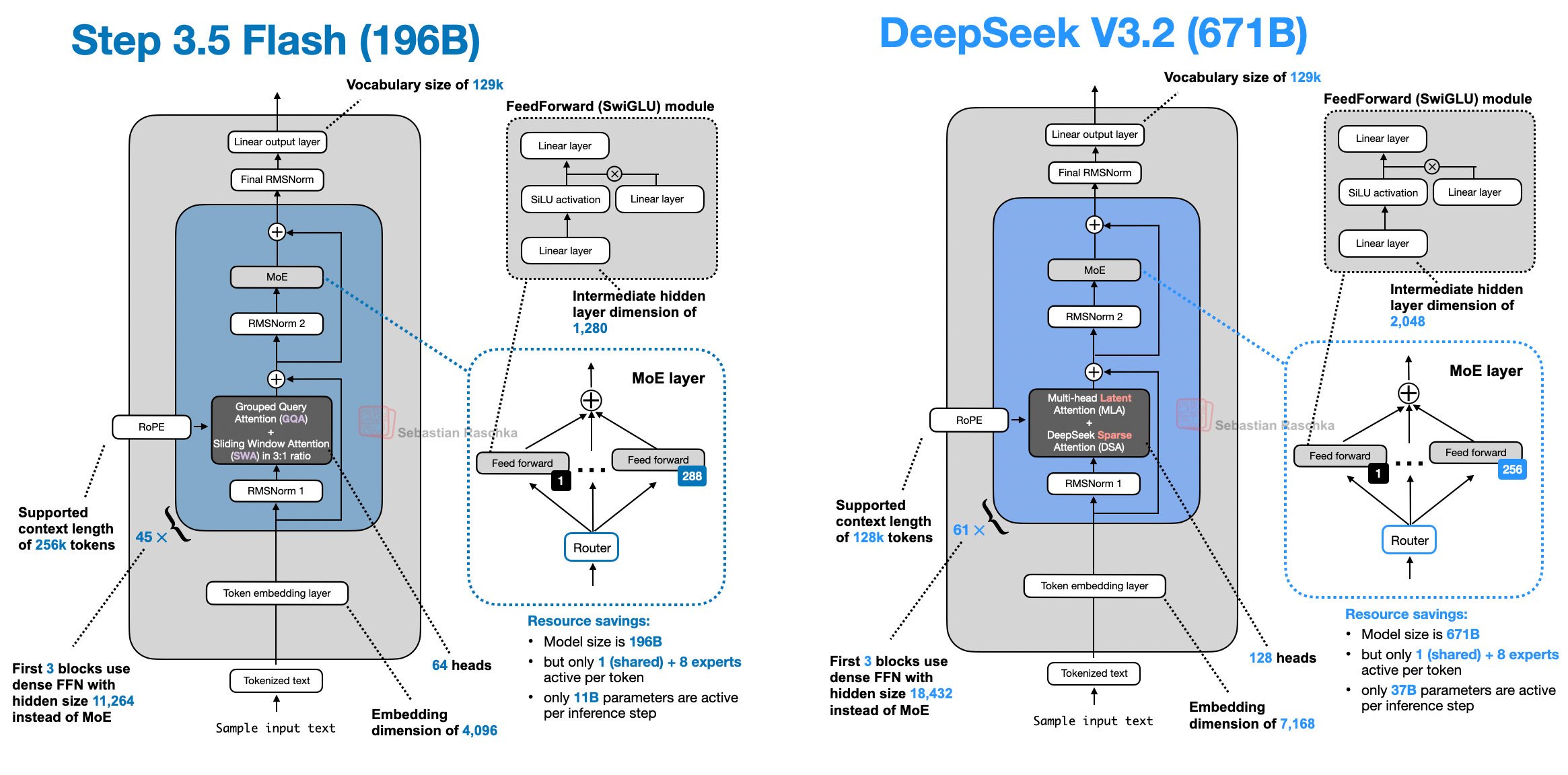
One reason for this higher performance is the model’s smaller size (196B-parameter MoE with 11B parameters active per token versus 671B-parameter MoE with 37B parameters active), as shown in the figure below.
The other reason along with gated attention (which we previously discussed in the context of Trinity) is Multi-Token Prediction (MTP). DeepSeek has been an early adopter of multi-token prediction, a technique that trains the LLM to predict multiple future tokens at each step, rather than a single one. Here, at each position t, small extra heads (linear layers) output logits for t+1...t+k, and we sum cross-entropy losses for these offsets (in the MTP paper, the researchers recommended k=4).
This additional signal speeds up training, and inference may remain at generating one token at a time, as illustrated in the figure below.
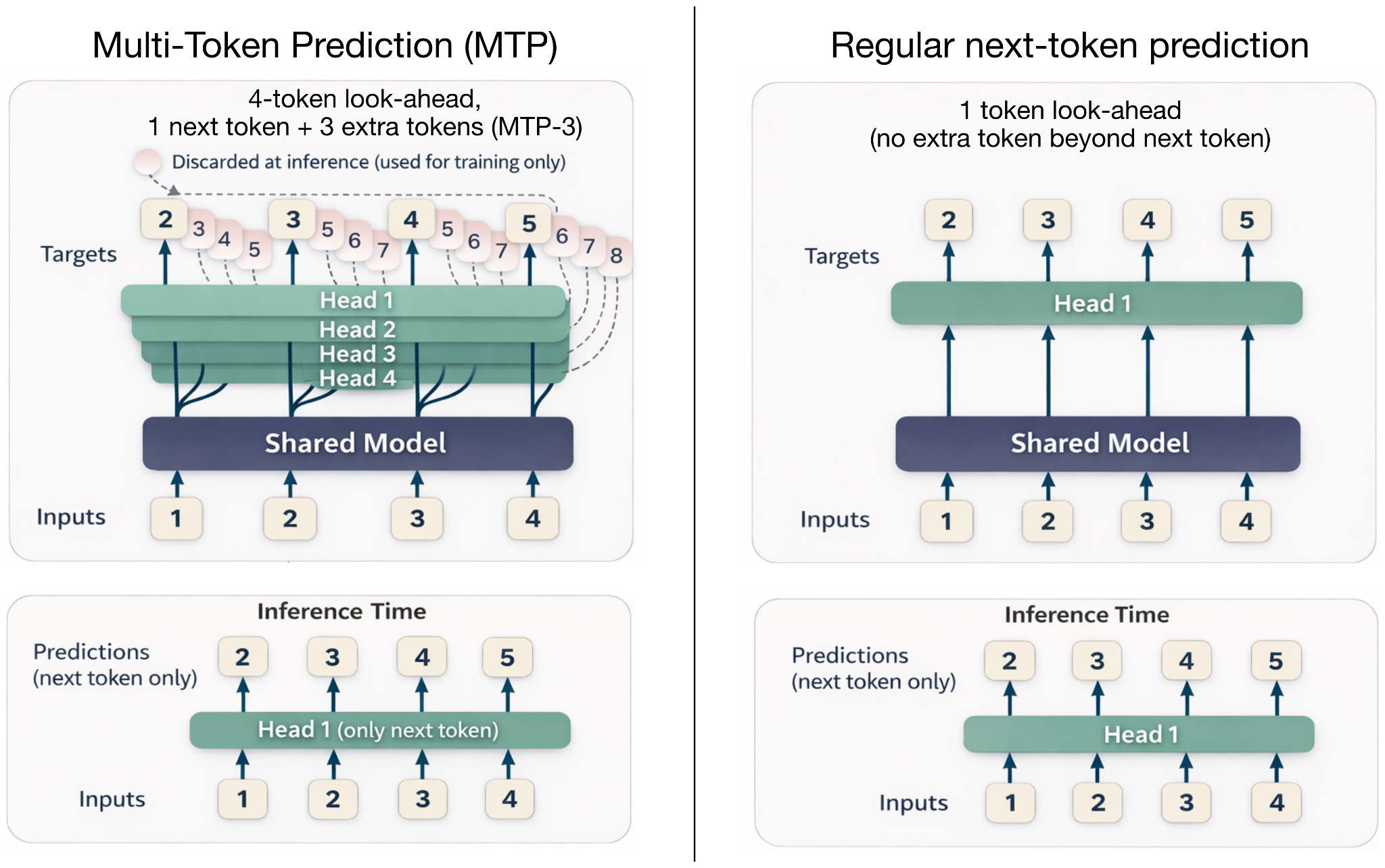
DeepSeek V3 reported using MTP-1, that is, MTP with 1 extra token (instead of 3) during training, and then making MTP optional during inference.
Step 3.5 Flash uses MTP with 3 additional tokens (MTP-3) during both training and inference (note that MTP is usually not used during inference, and this is an exception).
Note that the previously discussed Arcee Trinity and Kimi K2.5 do not use MTP, but other architectures already use an MTP-3 setup similar to Step 3.5 Flash, for example, GLM-4.7 and MiniMax M2.1.
4. Qwen3-Coder-Next: An Attention-Hybrid for Coding
In early February 2026, the Qwen3 team shared the 80B Qwen3-Coder-Next model (3B parameters active), which made big headlines for outperforming much larger models like DeepSeek V3.2 (37B active) and Kimi K2.5 and GLM-4.7 (both 32B active) on coding tasks.
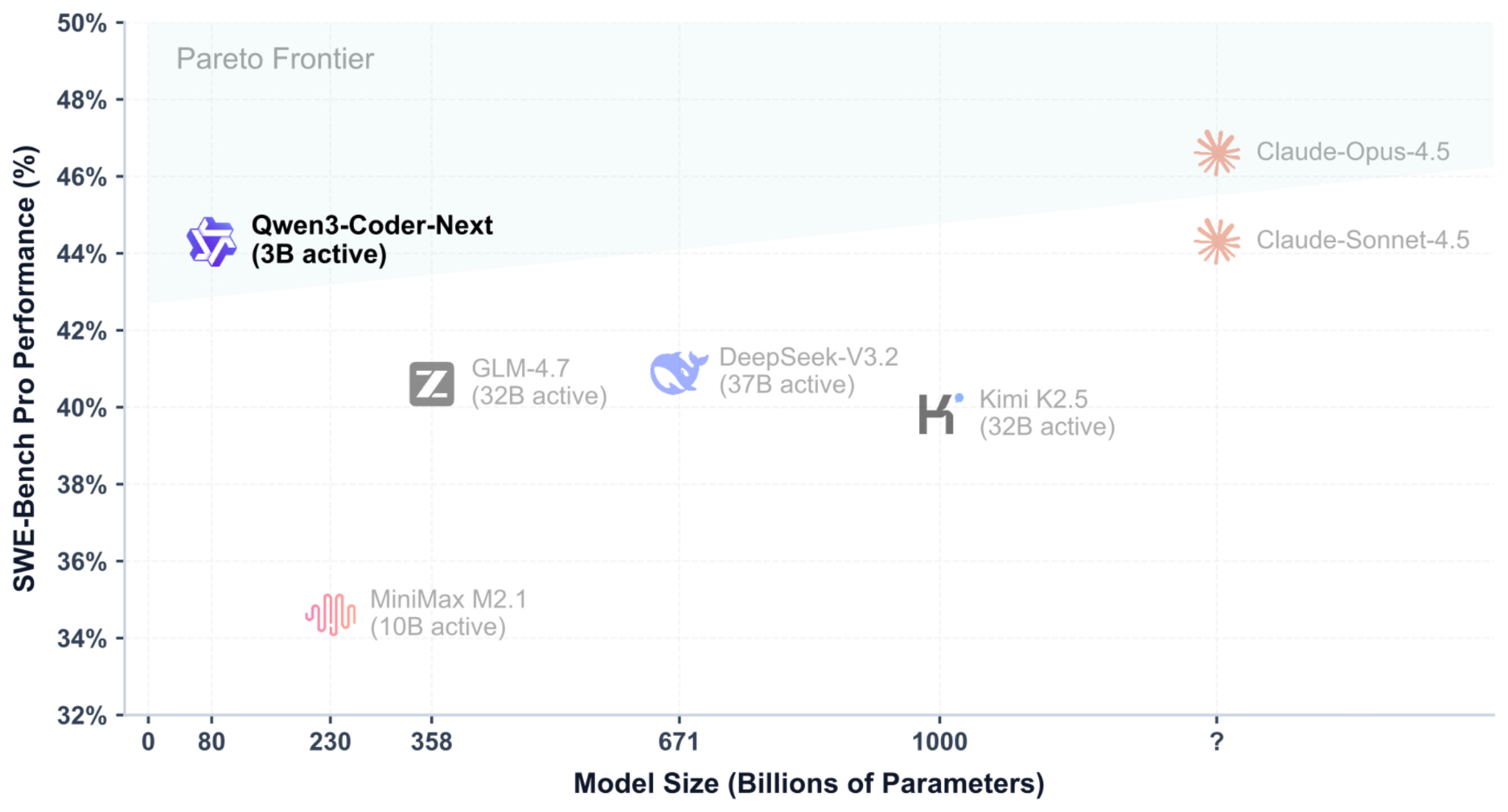
Moreover, as shown in the benchmark figure above, the Qwen3-Coder-Next SWE-Bench Pro performance is roughly on par with Claude Sonnet 4.5 (and only slightly below Claude Opus 4.5), which is impressive for a relatively small open-weight model!
Using the ollama version of Qwen3-Coder-Next locally, the model takes about 48.2 GB of storage space and 51 GB of RAM.
Note that the architecture behind Qwen3-Coder-Next is exactly the same as Qwen3-Next 80B (in fact, the pre-trained Qwen3-Next 80B is used as a base model for further mid- and post-training). Figure 16 below shows the Qwen3-Next architecture next to a regular Qwen3 235B model for reference.
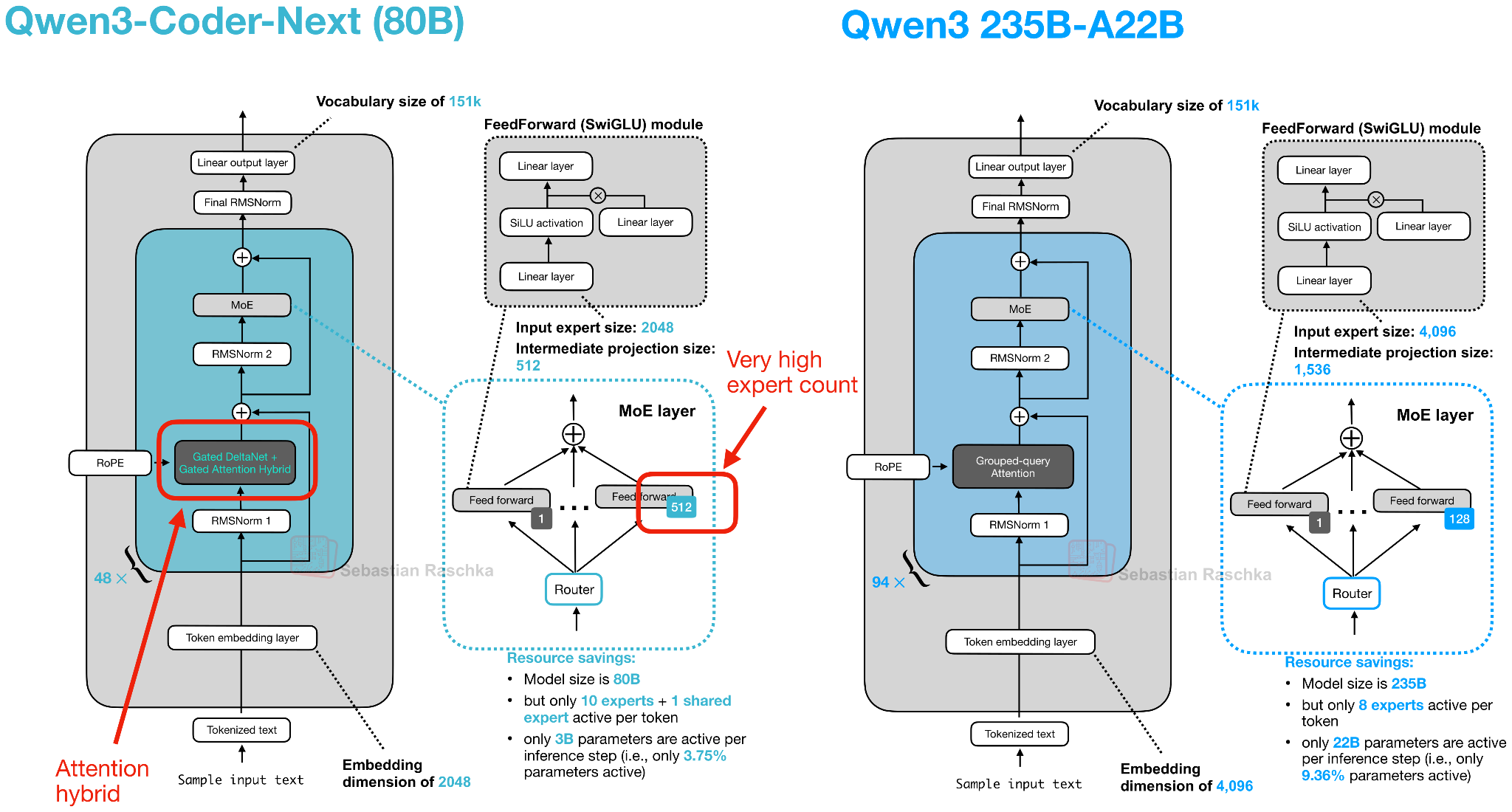
The new Qwen3 Next architecture stands out because, despite being 3x smaller than the previous 235B-A22B model, it introduces four times as many experts and even adds a shared expert. Both of these design choices (a high expert count and the inclusion of a shared expert).
The other highlight is that they replace the regular attention mechanism with a Gated DeltaNet + Gated Attention hybrid, which helps enable the native 262k token context length in terms of memory usage (the 235B-A22B model supported 32k natively and 131k with YaRN scaling).
So how does this new attention hybrid work? Compared to grouped‑query attention (GQA), which is still standard scaled dot‑product attention (sharing K/V across query‑head groups to cut KV‑cache size and memory bandwidth as discussed earlier, but whose decode cost and cache still grow with sequence length), their hybrid mechanism mixes Gated DeltaNet blocks with Gated Attention blocks in a 3:1 ratio as shown in Figure 17.
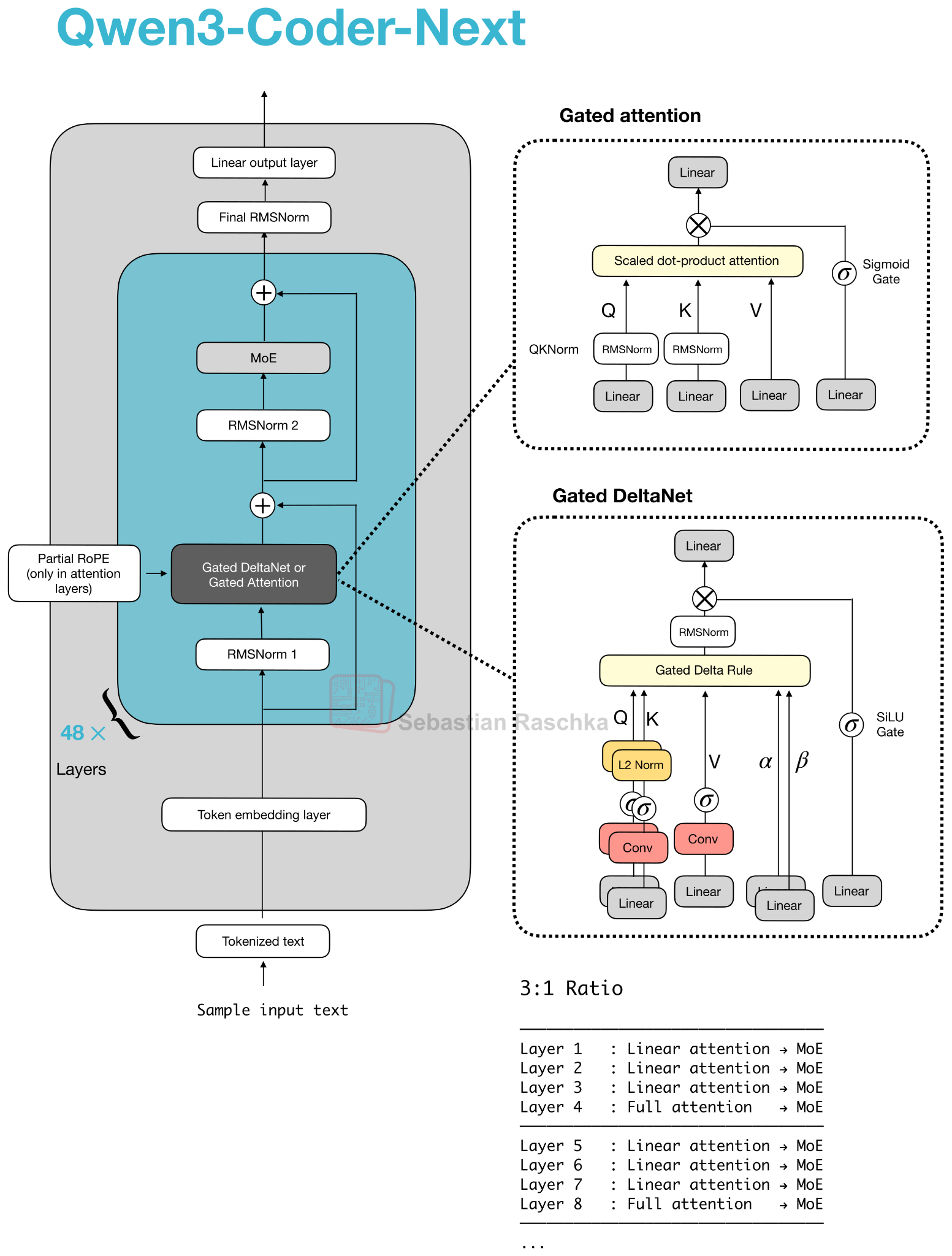
We can think of the gated attention block as standard scaled-dot-product attention used in GQA, with a few tweaks on top. The main differences between gated attention and plain GQA block are:
an output gate (sigmoid-controlled, usually per-channel) that scales the attention result before it is added back to the residual;
zero-centered RMSNorm for QKNorm, rather than a standard RMSNorm;
partial RoPE (on a subset of dimensions).
Note that these are essentially just stability changes to GQA.
The Gated DeltaNet is a more significant change. In the DeltaNet block, q, k, v, and two gates (α, β) are produced by linear and lightweight convolutional layers with normalization, and the layer replaces attention with a fast‑weight delta rule update.
However, the tradeoff is that DeltaNet offers less precise content‑based retrieval than full attention, which is why one gated attention layer remains.
Given that attention grows quadratically, the DeltaNet component was added to help with memory efficiency. In the “linear-time, cache-free” family, the DeltaNet block is essentially an alternative to Mamba. Mamba keeps a state with a learned state-space filter (essentially a dynamic convolution over time). DeltaNet keeps a tiny, fast-weight memory updated with α and β, and reads it with q, using small convolutions only to help form q, k, v, α, β.
For more details on the attention hybrid and Qwen3-Next architecture, please see my previous article Beyond Standard LLMs.
Since this article is primarily focused on LLM architectures, the training details are outside its scope. However, interested readers can find more information in their detailed technical report on GitHub.
5. z.AI’s GLM-5: A New Flagship Open-Weight Model
The GLM-5 release on February 12th was a big deal, because at the time of its release it appeared to be on par with the major flagship LLM offerings, including GPT-5.2 extra-high, Gemini Pro 3, and Claude 4.6 Opus. (That said, benchmark performance does not necessarily translate to real-world performance.)
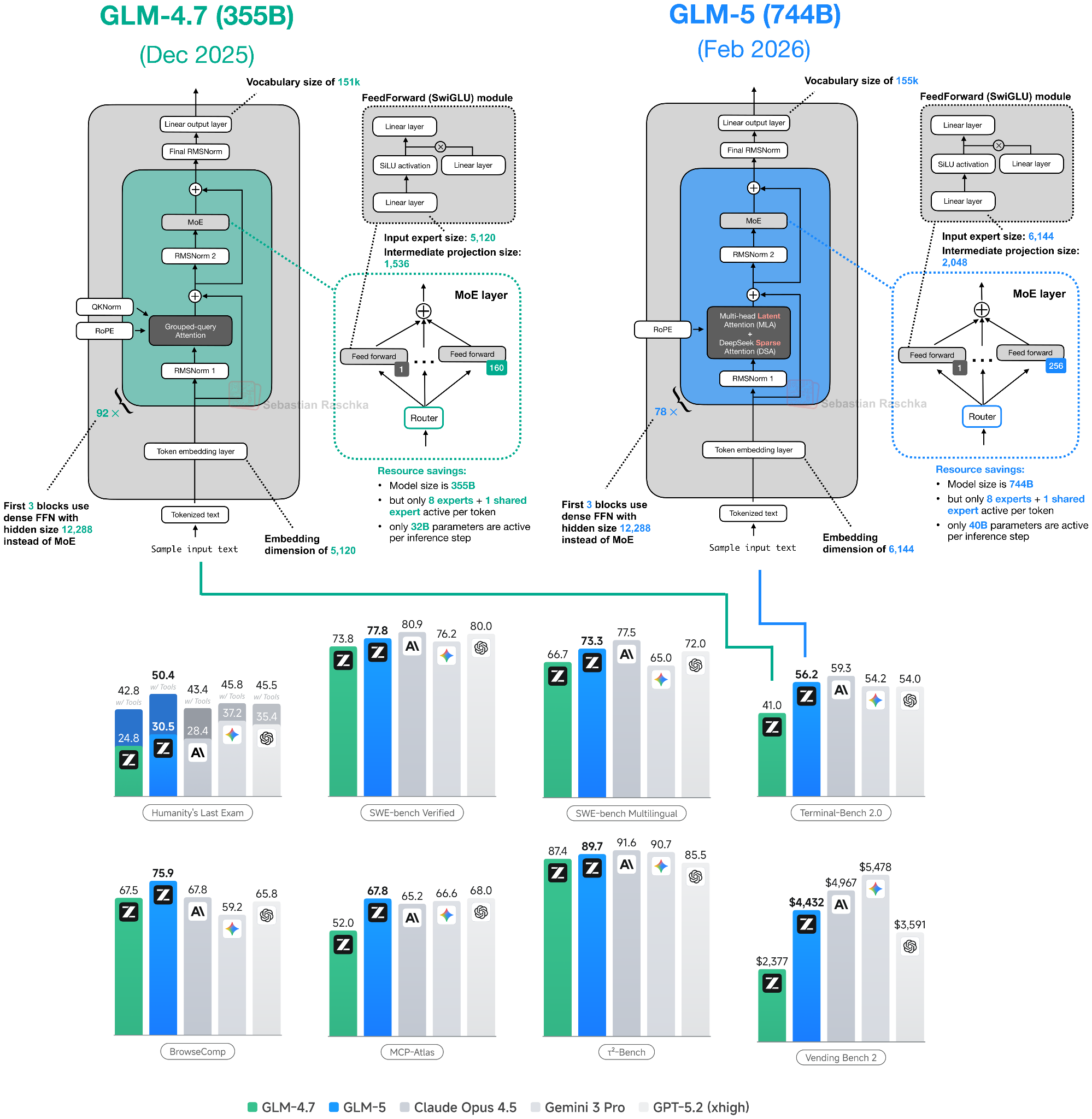
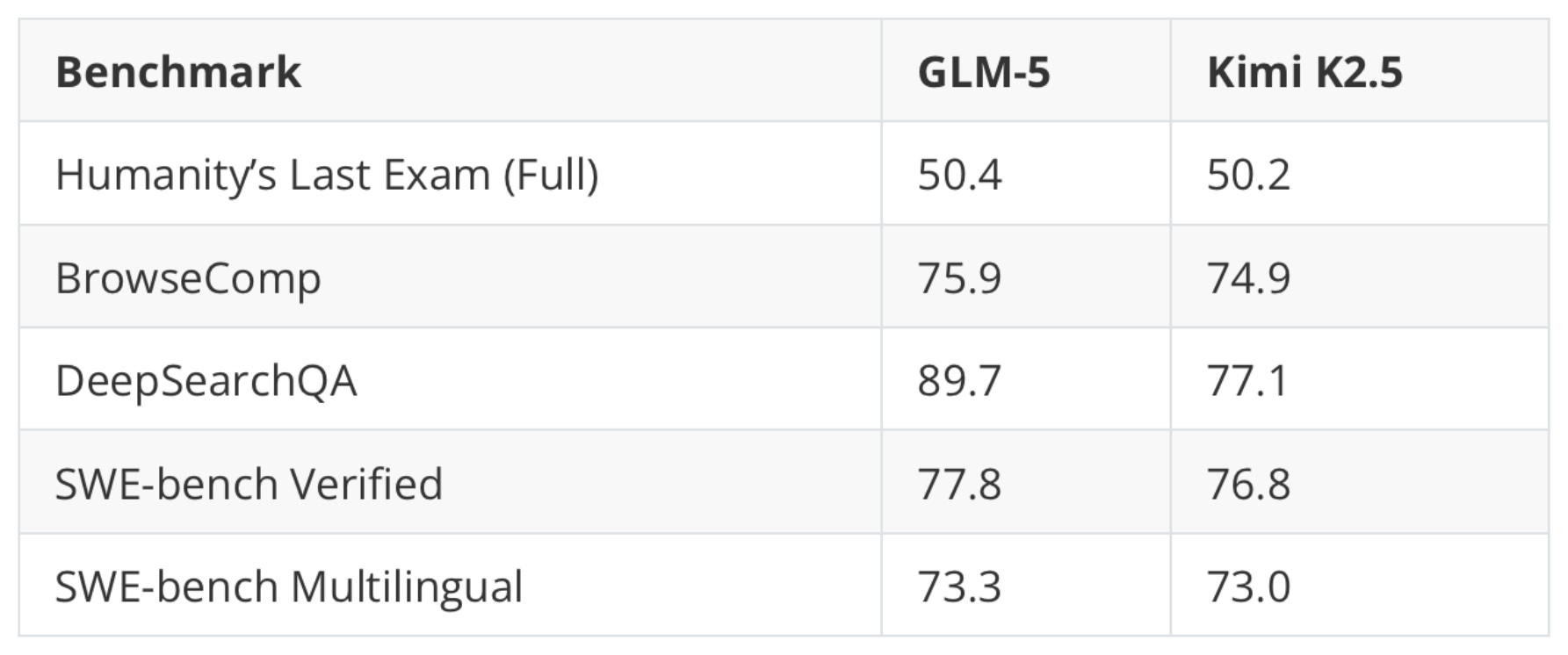
Not too long ago, GLM-4.7 (December 2025) was one of the strongest open-weight models. GLM-5 shows a major modeling performance improvement based on the benchmark shown in Figure 18 above. That jump is likely partly due to improvements to the training pipeline, but likely largely attributed to its 2x larger parameter count from 355B parameters in GLM-4.7 to 744B parameters in GLM-5. This size increase now places GLM-5 between DeepSeek V3.2 (671B) and Kimi K2.5 (1T) in terms of scale.
Comparing the benchmark numbers of the previously discussed Kimi K2.5 (1T), the smaller GLM-5 (744B) model seems slightly ahead, as shown in the table below.
Like GLM-4.7, all the other models discussed so far, GLM-5 is a Mixture-of-Experts model. The number of active parameters per token increases only slightly, from 32B in GLM-4.7 to 40B in GLM-5.
As shown in Figure 20 below, GLM-5 now adopts DeepSeek’s multi-head latent attention as well as DeepSeek Sparse Attention. (I described DeepSeek Sparse Attention in more detail in From DeepSeek V3 to V3.2: Architecture, Sparse Attention, and RL Updates.)
These modifications are likely intended to reduce inference costs when working with long contexts. Otherwise, the overall architecture remains relatively similar.
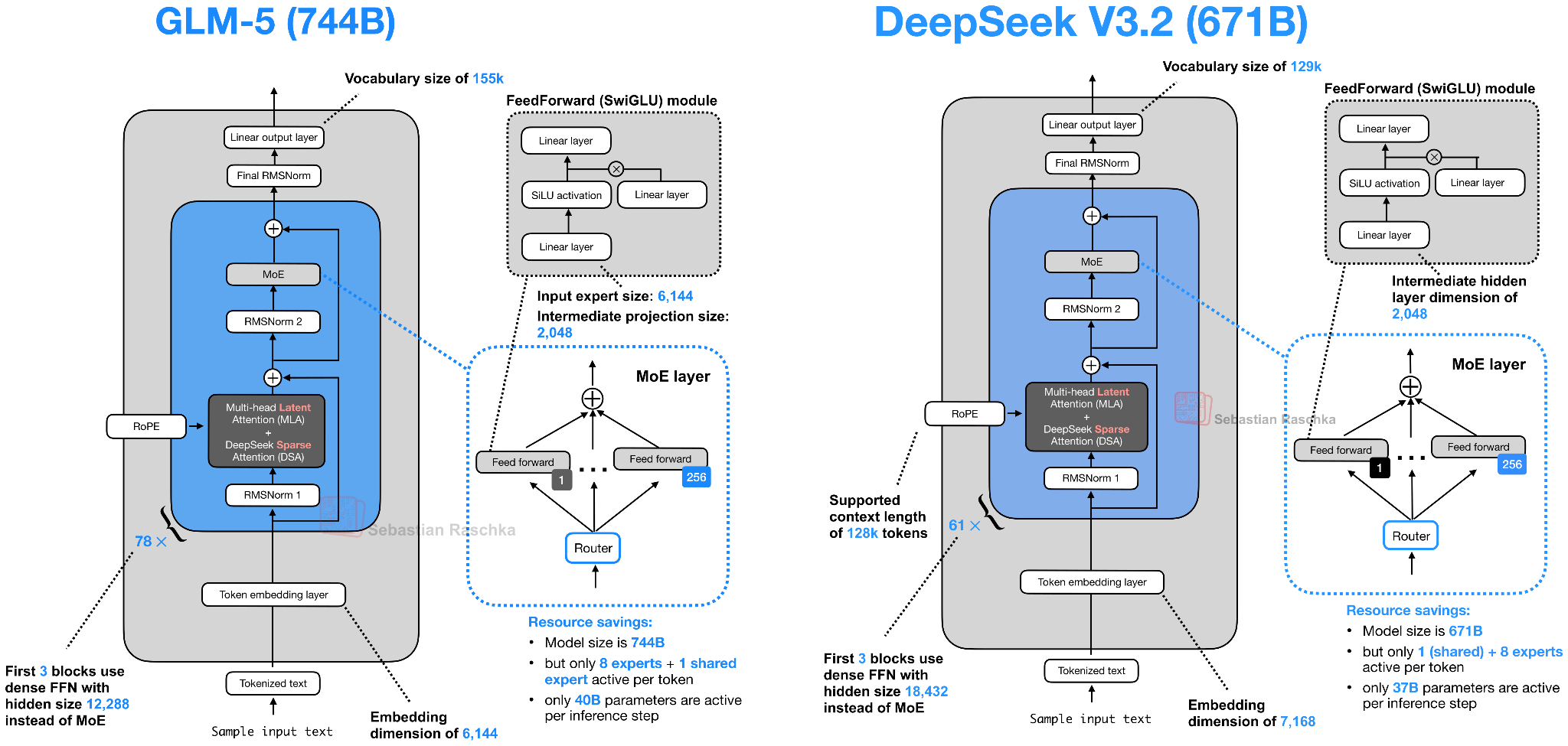
The increase in total size over GLM-4.7 mainly comes from expanding the number of experts, from 160 (GLM-4.7) to 256 (GLM-5), and slightly increasing layer dimensions (while keeping the number of experts the same at 8 regular + 1 shared expert per token). For example, the embedding dimension and expert size increase from 5,120 to 6,144, and the intermediate projection size rises from 1,536 to 2,048.
Interestingly, the number of transformer layers is reduced from 92 in GLM-4.7 to 78 in GLM-5. I assume this change is also intended to reduce inference costs and improve latency, since layer depth cannot be parallelized in the same way as width.
Additionally, I also checked an independent benchmark (here, the hallucination leaderboard), and it indeed looks like GLM-5 is on par with Opus 4.5 and GPT-5.2 (while using fewer tokens).
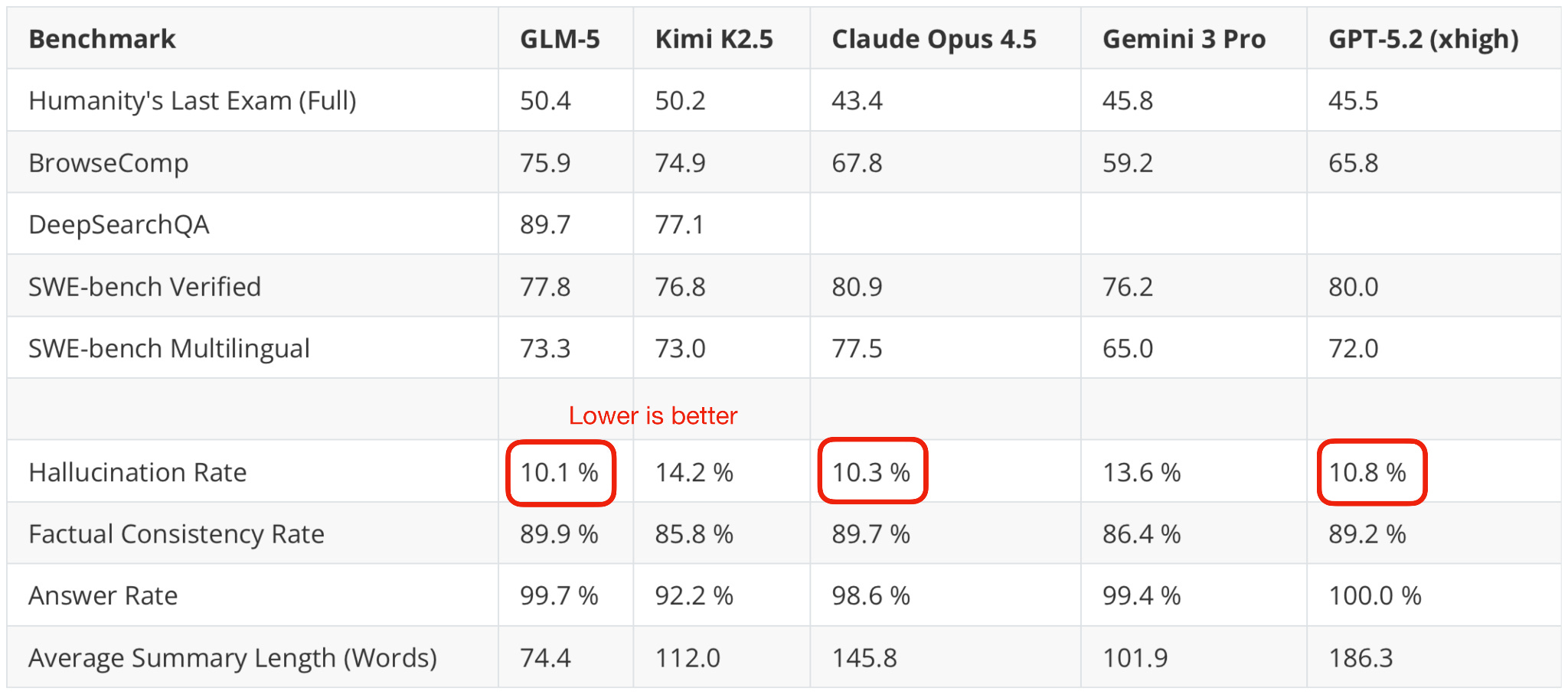
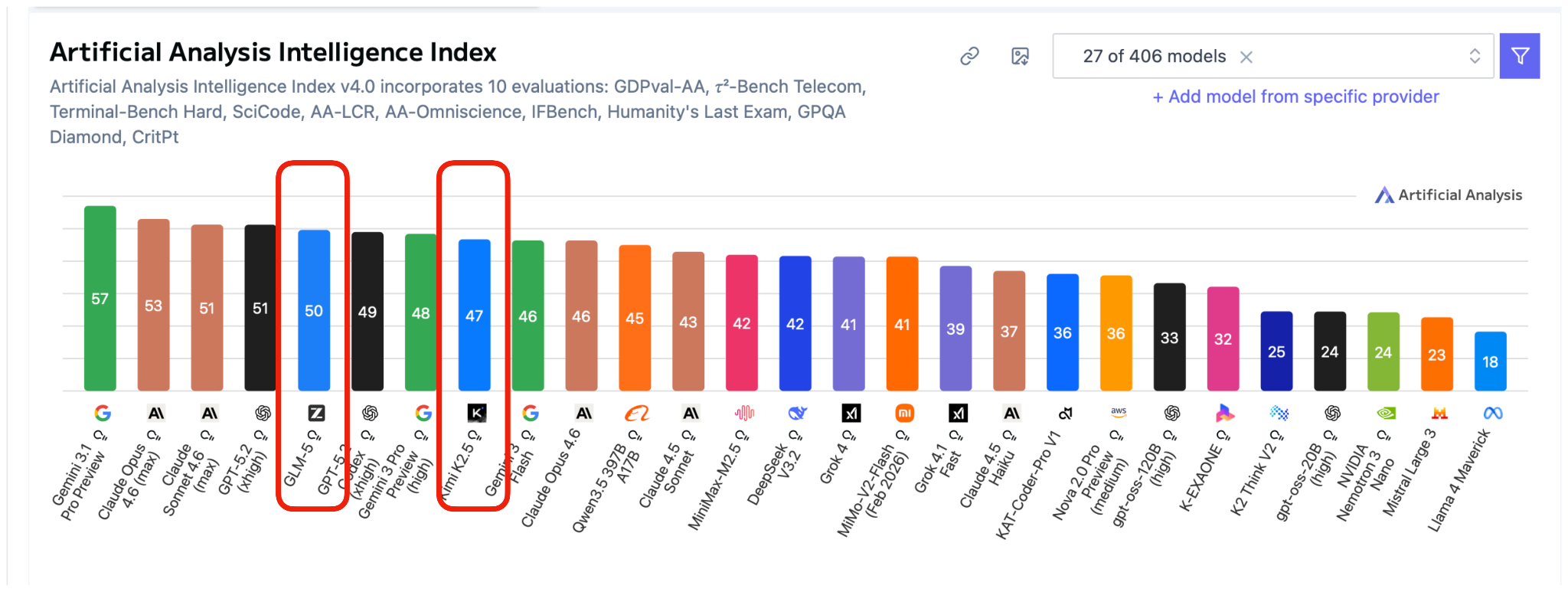
Furthermore, looking at the most recent Artificial Intelligence Index, which aggregates various benchmarks, GLM-5 is indeed slightly ahead of Kimi K2.5 and only one point behind GPT-5.2 (xhigh) and the recent Claude Sonnet 4.6.
6. MiniMax M2.5: A Strong Coder with “Only” 230B Parameters
The aforementioned GLM-5 and Kimi K2.5 are popular open-weight models, but according to OpenRouter statistics, they pale in comparison to MiniMax M2.5, which was released on February 12 as well.
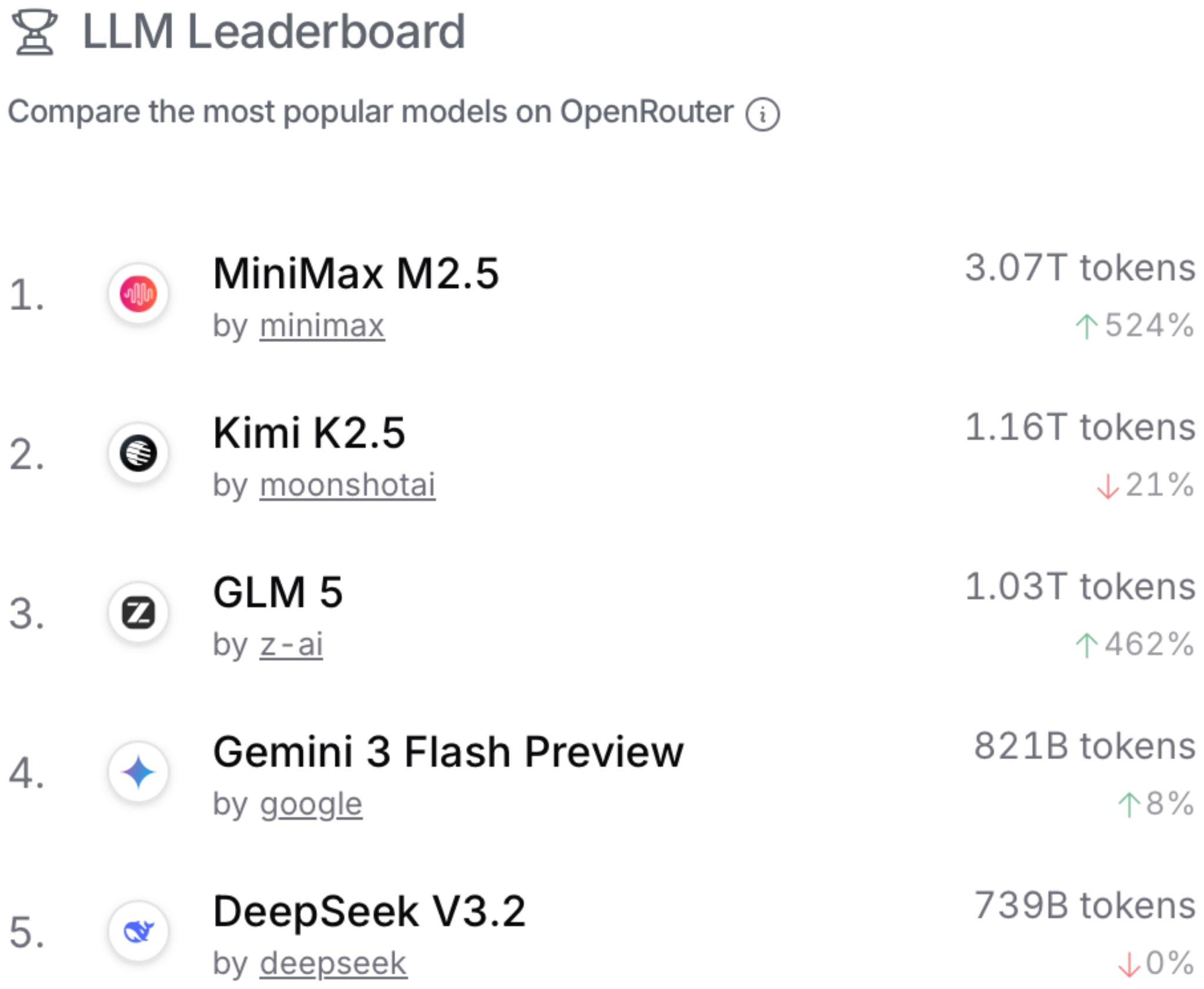
OpenRouter is a platform and API that lets developers access and route requests across many different LLMs from various providers. Note that while its usage statistics are a good indicator of open-weight model popularity, it’s heavily biased towards open-weight models (versus proprietary models), since most users use proprietary models through the official platform directly. There is also usage bias across open-weight models, since many people also use open-weight models through the official developers’ APIs. Anyways, it can still be an interesting place to guesstimate the relative popularity of open-weight models that are too large to run locally for most users.
Now, back to MiniMax M2.5. Pulling together the GLM-5 data from the SWE-Bench Verified coding benchmark and combining it with the reported MiniMax M2.5, the latter appears to be a slightly stronger model (at least when it comes to coding).
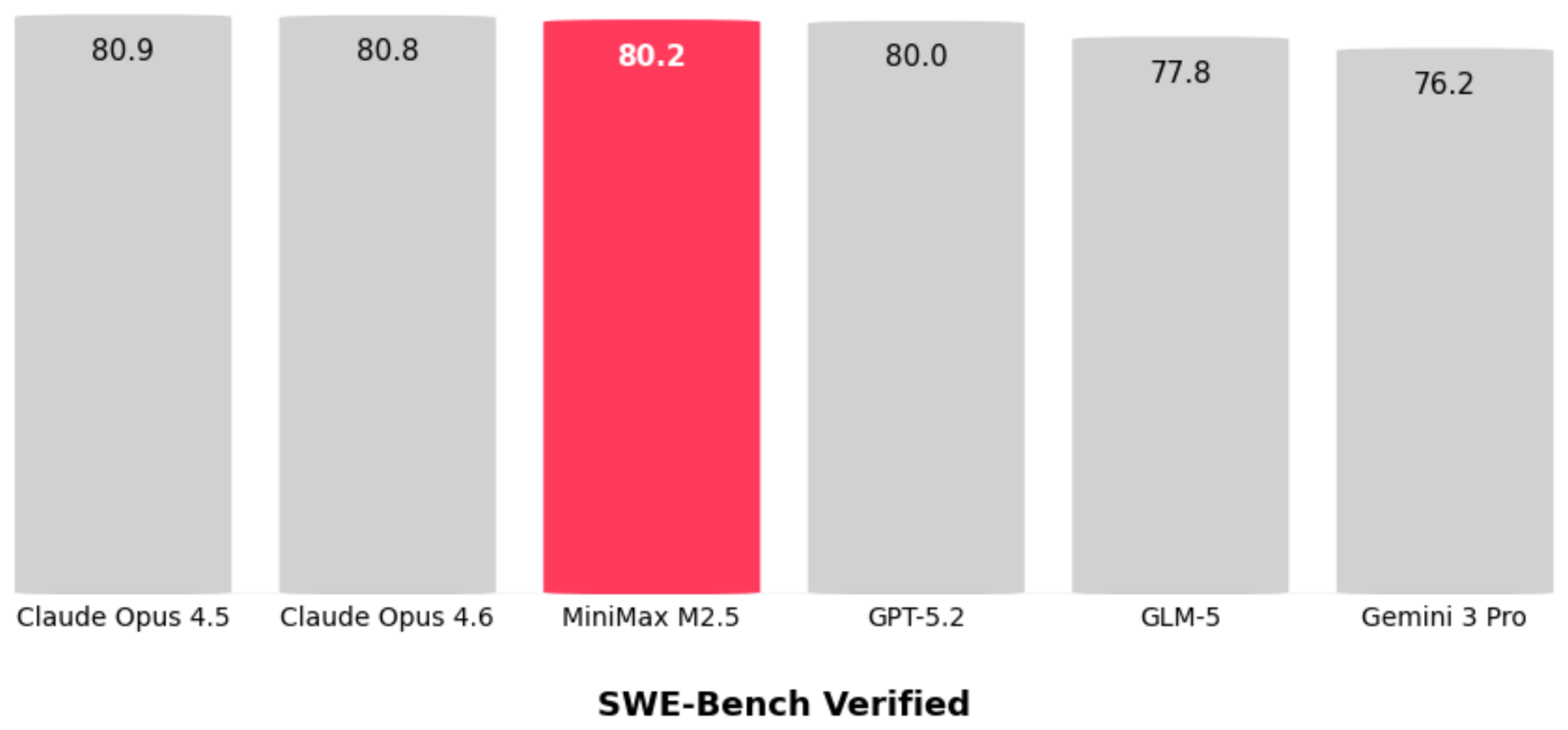
Side note: It’s interesting to see Opus 4.5 and Opus 4.6 practically scoring identically on SWE-Bench Verified. This can be an indicator that LLM progress has stalled. I don’t think that’s true, though, given that users of Opus 4.6 can confirm that this model does seem to perform better in real-world usage. So, the more likely issue here is that the SWE-Bench Verified benchmark has saturated, and it may no longer be a meaningful benchmark to report from now on (in favor of other benchmarks like SWE-Bench Pro, for example). With saturated, I mean that it potentially contains unsolvable problems due to design issues (as discussed in a recent Reddit thread and the new “Why SWE-bench Verified no longer measures frontier coding capabilities“ article by OpenAI).
Anyways, back to the topic of MiniMax M2.5 performance. Looking across a broader selection of benchmarks, according to the Artificial Intelligence Index aggregation, GLM-5 remains ahead. This is perhaps no surprise because GLM-5 is still a 4x larger model than M2.5, even though the tokens/sec throughput is quite similar.

I think MiniMax M2.5’s popularity is partly owed to the fact that it is a smaller, cheaper model with roughly similar modeling performance (i.e., a good bang for the buck).
Architecture-wise, MiniMax M2.5 is a 230B model with a fairly classic design: just plain Grouped Query Attention, no sliding window attention or other efficiency improvements.
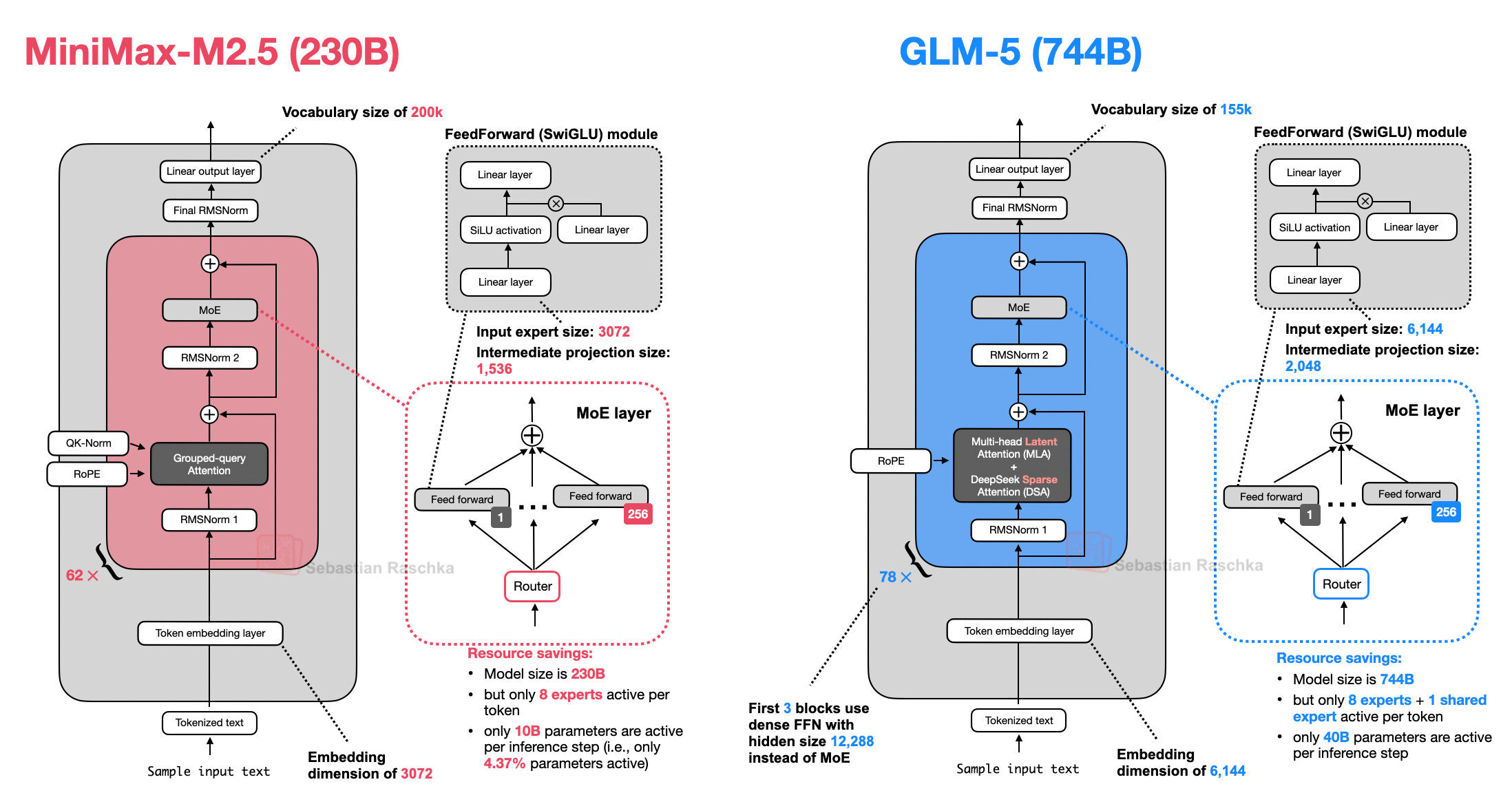
So far, this is also the first architecture in this report that doesn’t come with a detailed technical report, but you can find additional information on the model hub page.
7. Nanbeige 4.1 3B: A Strong Llama 3 Successor
In this section, we are switching gears and finally covering a smaller model that can run locally on a laptop. But first let’s start with some context before we get to Nanbeige 4.1 3B.
Qwen models have always been very popular models. I often tell the story that when I was an advisor during the NeurIPS LLM efficiency challenge a few years back, most of the winning solutions were based on a Qwen model.
Now, Qwen3 is likely among the most widely used open-weight model suite since they cover such a wide range of sizes and use cases (from 0.6B to 235B)
Especially the smaller models (80B and less, like Qwen3-Next, covered previously) are great for local use on consumer hardware.
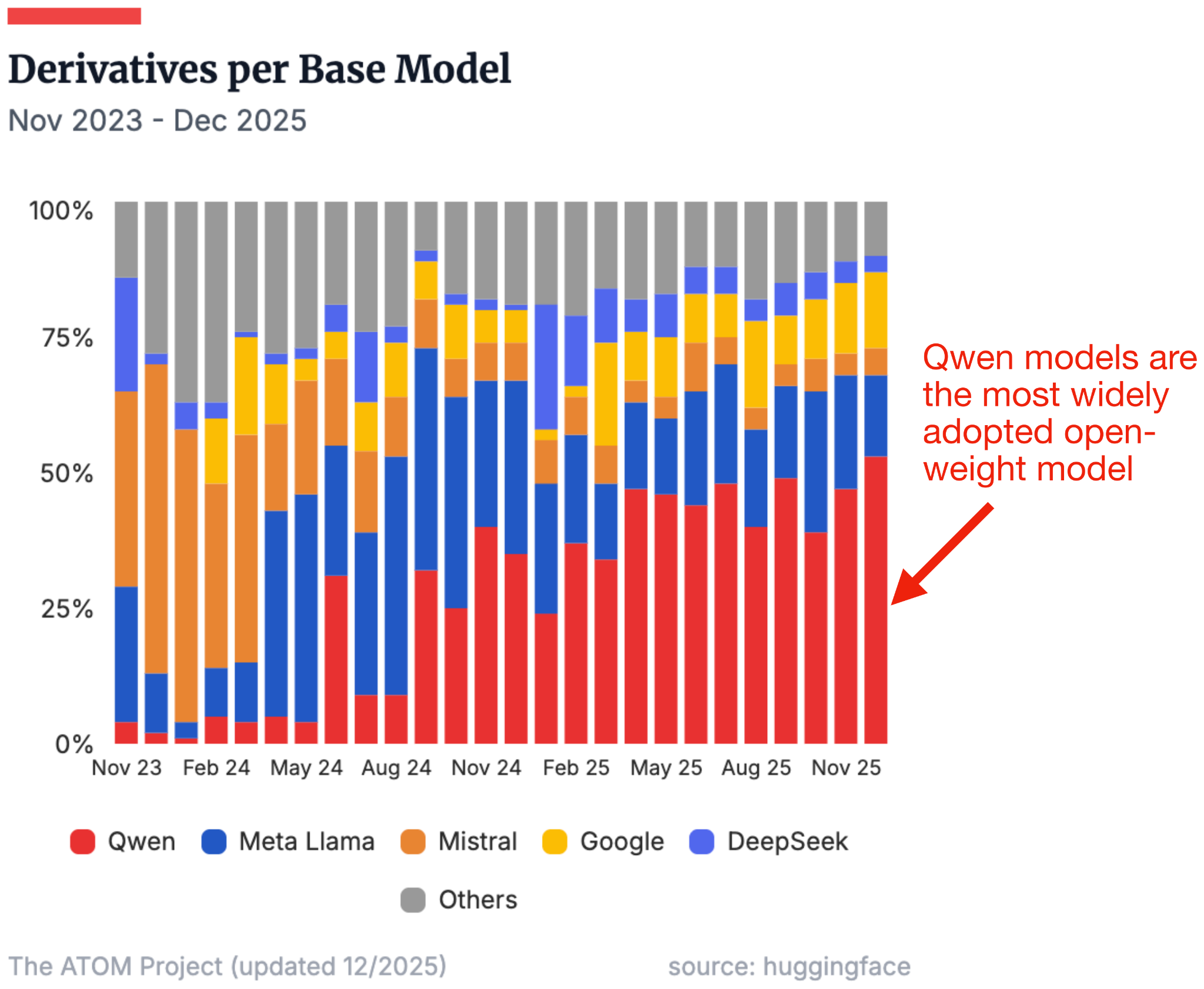
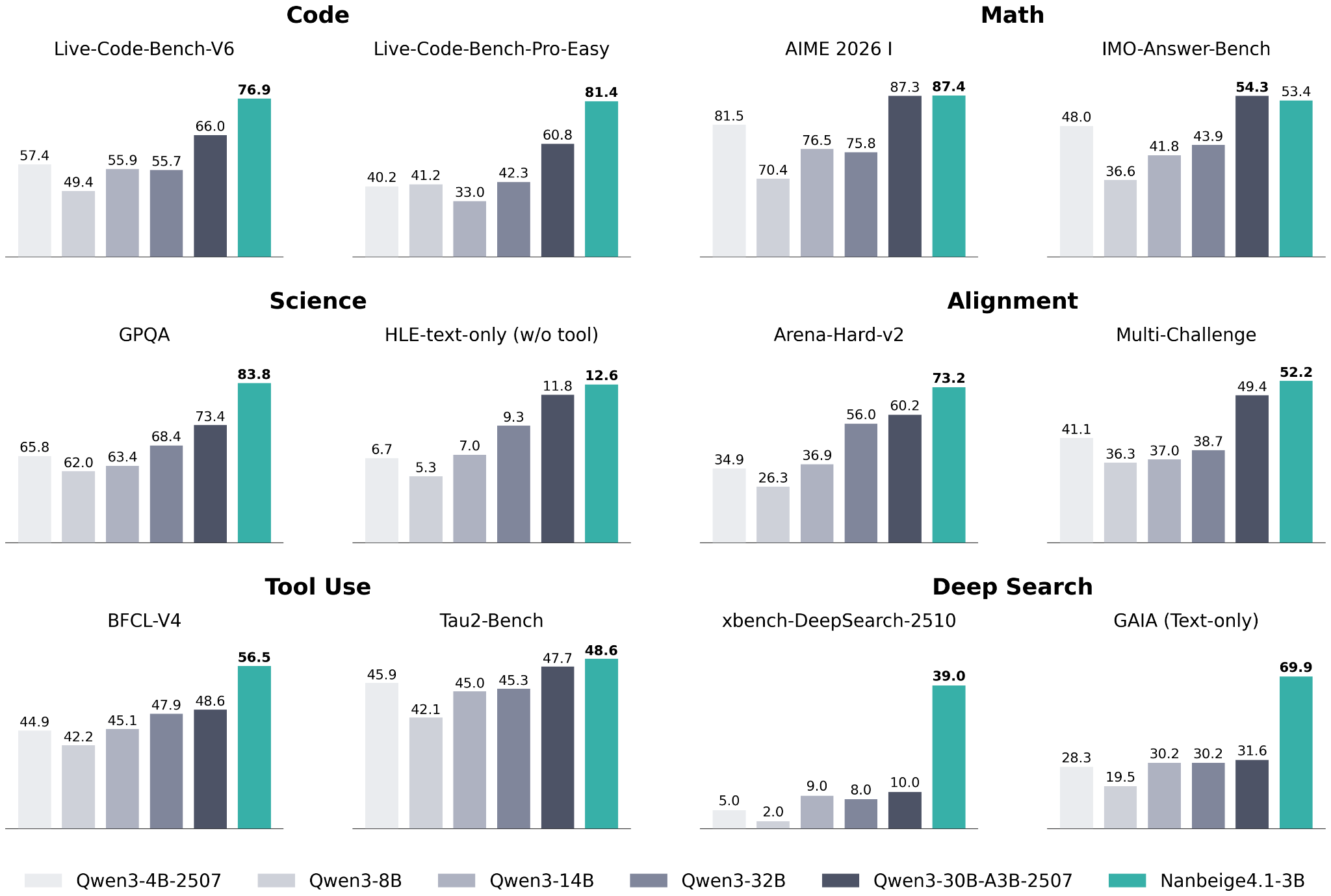
Why I am mentioning all this is that Nanbeige 4.1 3B seems to target the “small” LLM on-device use case that Qwen3 is so popular for. According to the Nanbeige 4.1 3B benchmarks, their model is way ahead of Qwen3 (perhaps no surprise, given that Qwen3 is almost a year old).
Architecture-wise, Nanbeige 4.1 3B is similar to Qwen3 4B, which is, in turn, very similar to Llama 3.2 3B. I am showing Nanbeige 4.1 3B next to Llama 3.2 3B below because it is the most similar in size.
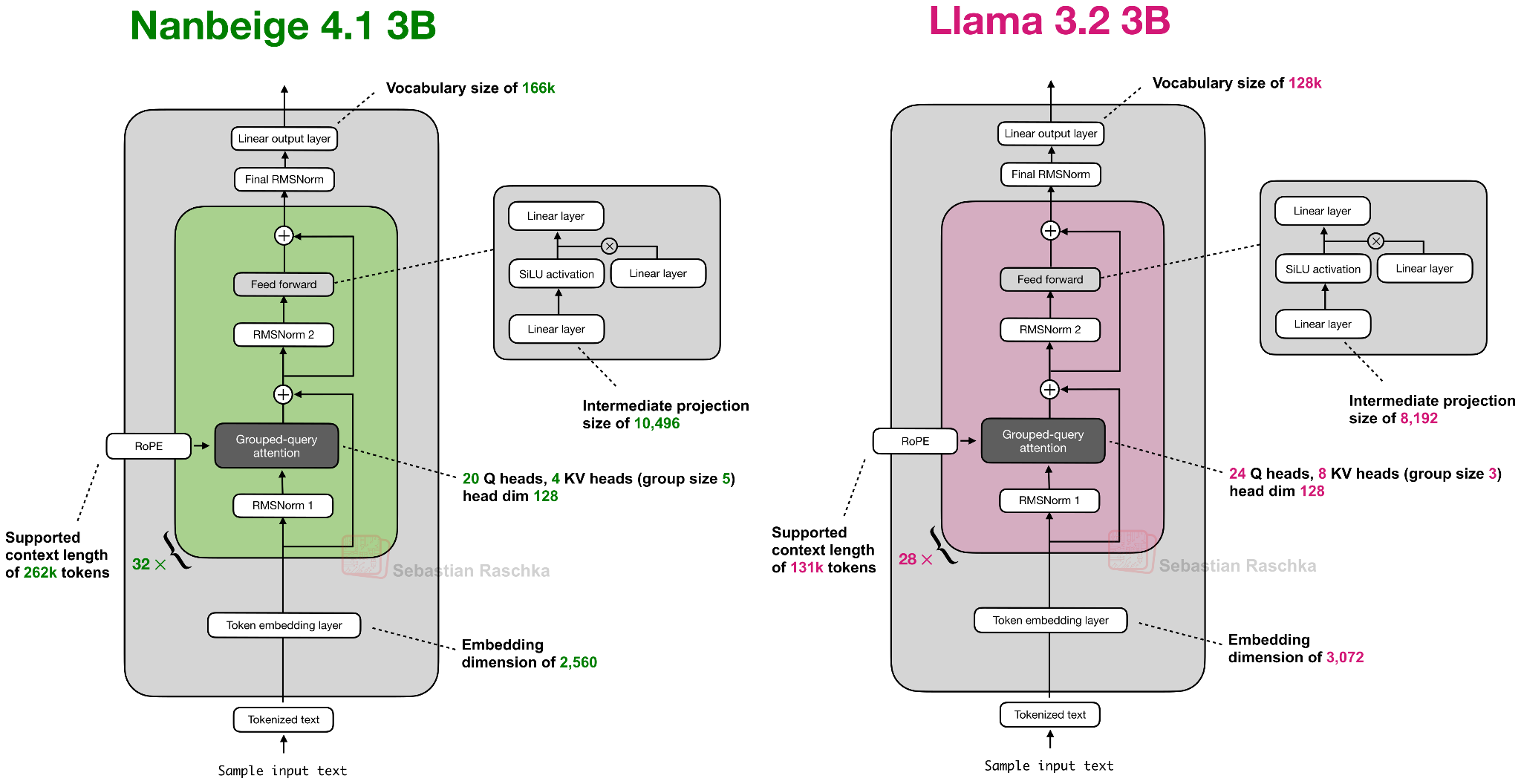
Nanbeige 4.1 3B uses the same architectural components as Llama 3.2 3B, with some minor scaling differences (slightly smaller embedding dimensions and larger intermediate projections, and so on). The one difference not shown in the figure above is that Nanbeige does not tie the input embedding weights to the output layer weights, whereas Llama 3.2 3B does. (In my experience, weight tying is a nice way to reduce the total number of parameters, but it almost always results in worse training performance as evidenced by higher training and validation losses.)
As mentioned before, this article focuses primarily on the architecture comparisons. And in this case, most of the performance gains (compared to the Nanbeige 4 3B predecessor) come from additional post-training with supervised fine-tuning and reinforcement learning, but interested readers can find more information in the detailed technical report.
8. Qwen3.5 and the Continuation of Hybrid Attention
While the previous section briefly covered Qwen3 as the most open-weight model family, it is getting a bit long in the tooth as its release is almost a year ago (if we don’t count the Qwen3-Next variants geared towards efficiency). However, the Qwen team just released a new Qwen3.5 model variant on February 15.
Qwen3.5 397B-A17B, a Mixture-of-Experts (MoE) with 397B parameters (17B active per token), is a step up from the largest Qwen3 model, which is 235B parameters in size. (There is also the 1 trillion-parameter Qwen3-Max model, but it was never released as an open-weight model.)
The obligatory benchmark overview shows that Qwen3.5 exceeds the previous Qwen3-Max model across the board, with a much stronger focus on agentic terminal coding applications (the main theme this year). Qwen3.5 appears to be roughly on par with GLM-5 and MiniMax M2.5 in terms of pure agentic coding performance (e.g., SWE-Bench Verified).
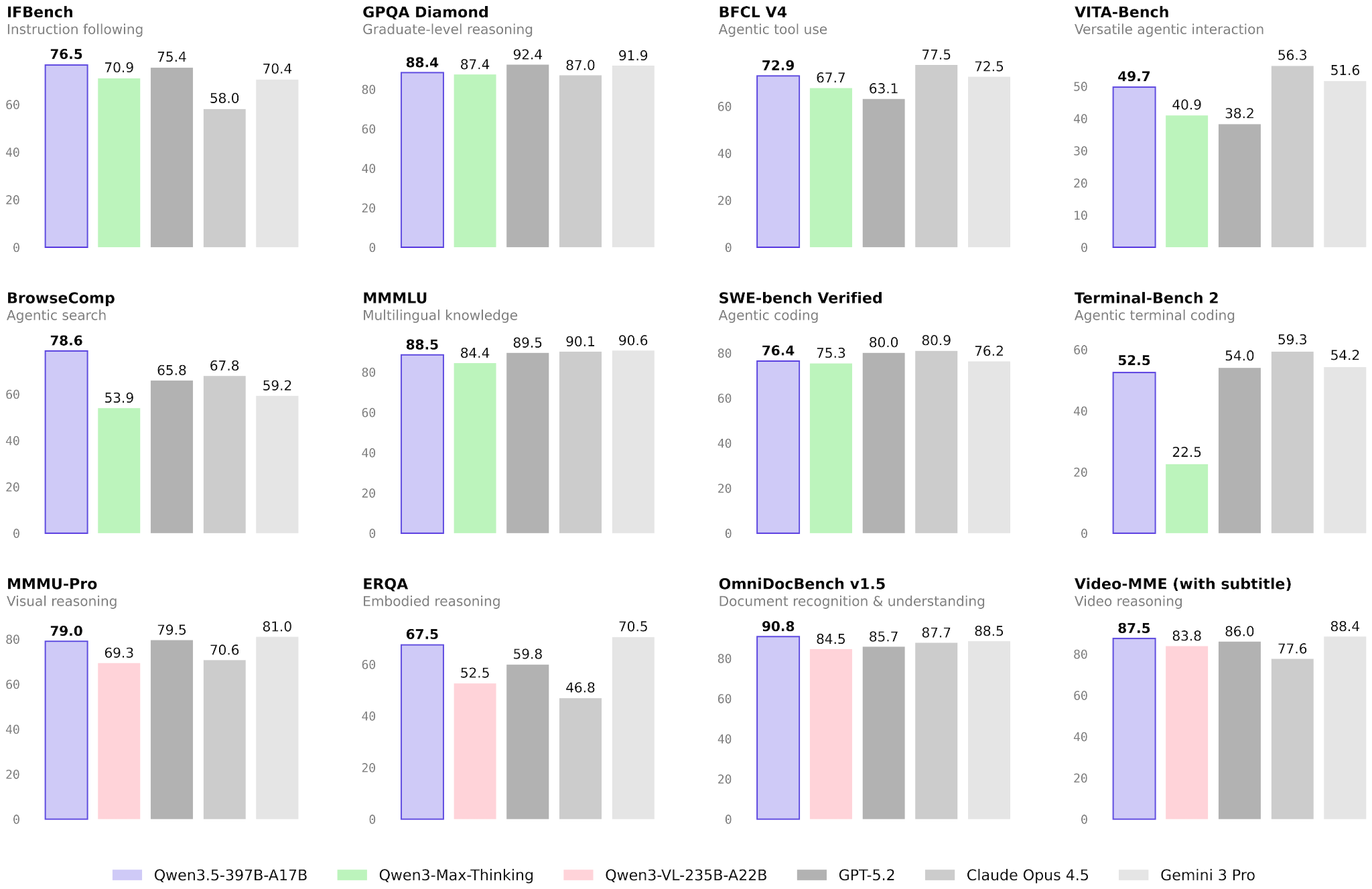
Since the Qwen team likes to release a separate coding model (e.g., see Qwen3-Coder-Next, which we discussed previously), this makes me curious to see how a potential Qwen3.5-Coder will perform.
Architecture-wise, Qwen3.5 adopts the hybrid attention model (featuring Gated DeltaNet) that Qwen3-Next and Qwen3-Coder-Next (section 4) used. This is interesting because Qwen3-Next models were initially an alternative to the full-attention Qwen3 models, but this suggests that the Qwen team has now adopted the hybrid attention mechanism into its main line of models.
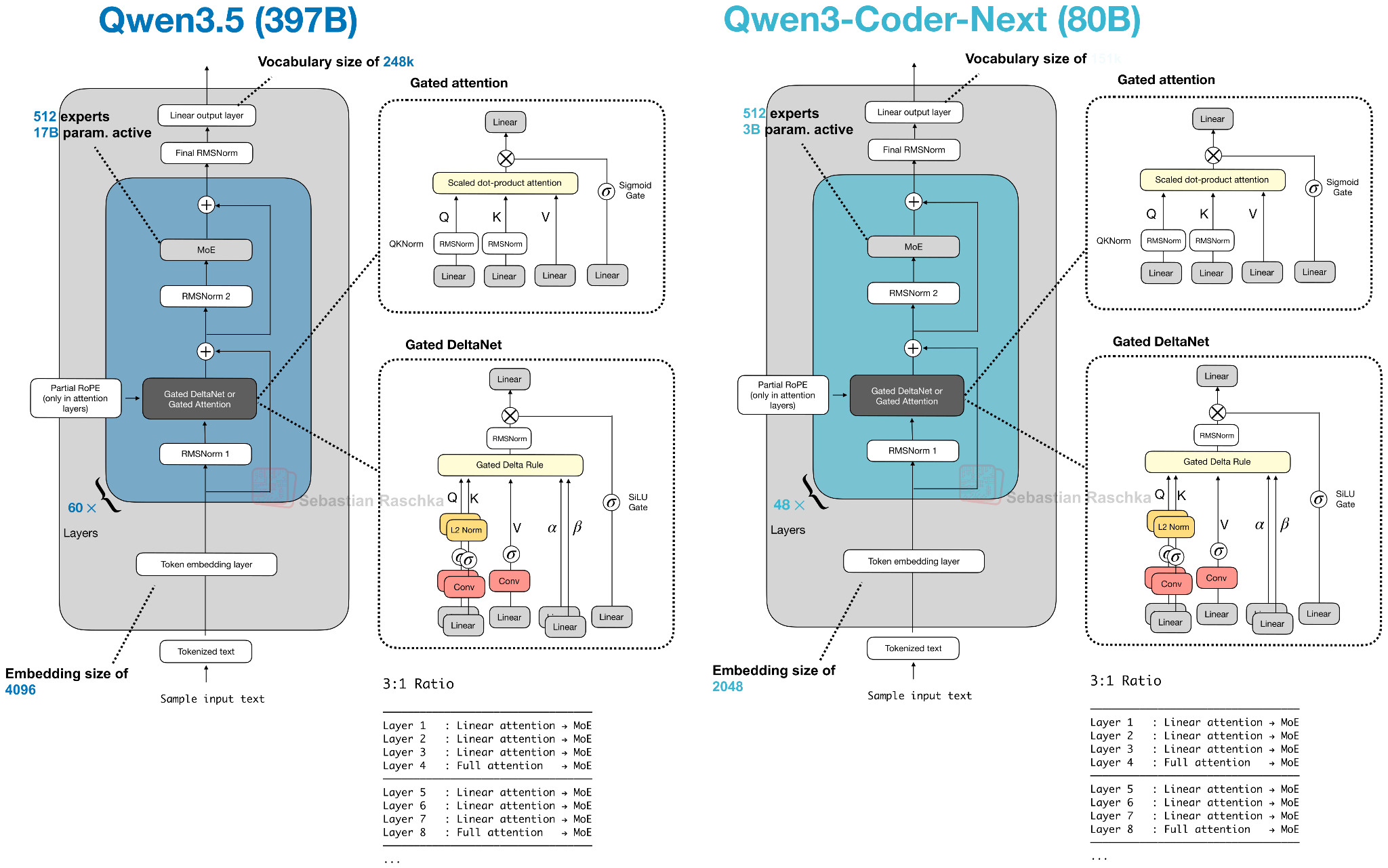
Besides scaling up the model size, as shown in the figure above, Qwen3.5 now also includes multimodal support (previously, it was only available in separate Qwen3-VL models).
Anyways, Qwen3.5 is a nice refresh of the Qwen series, and I hope that we will see smaller Qwen3.5 variants in the future, too!
Edit: Just as I finalized this article, the Qwen team launched said smaller model variants:
9. Ant Group’s Ling 2.5 1T with Lightning Attention
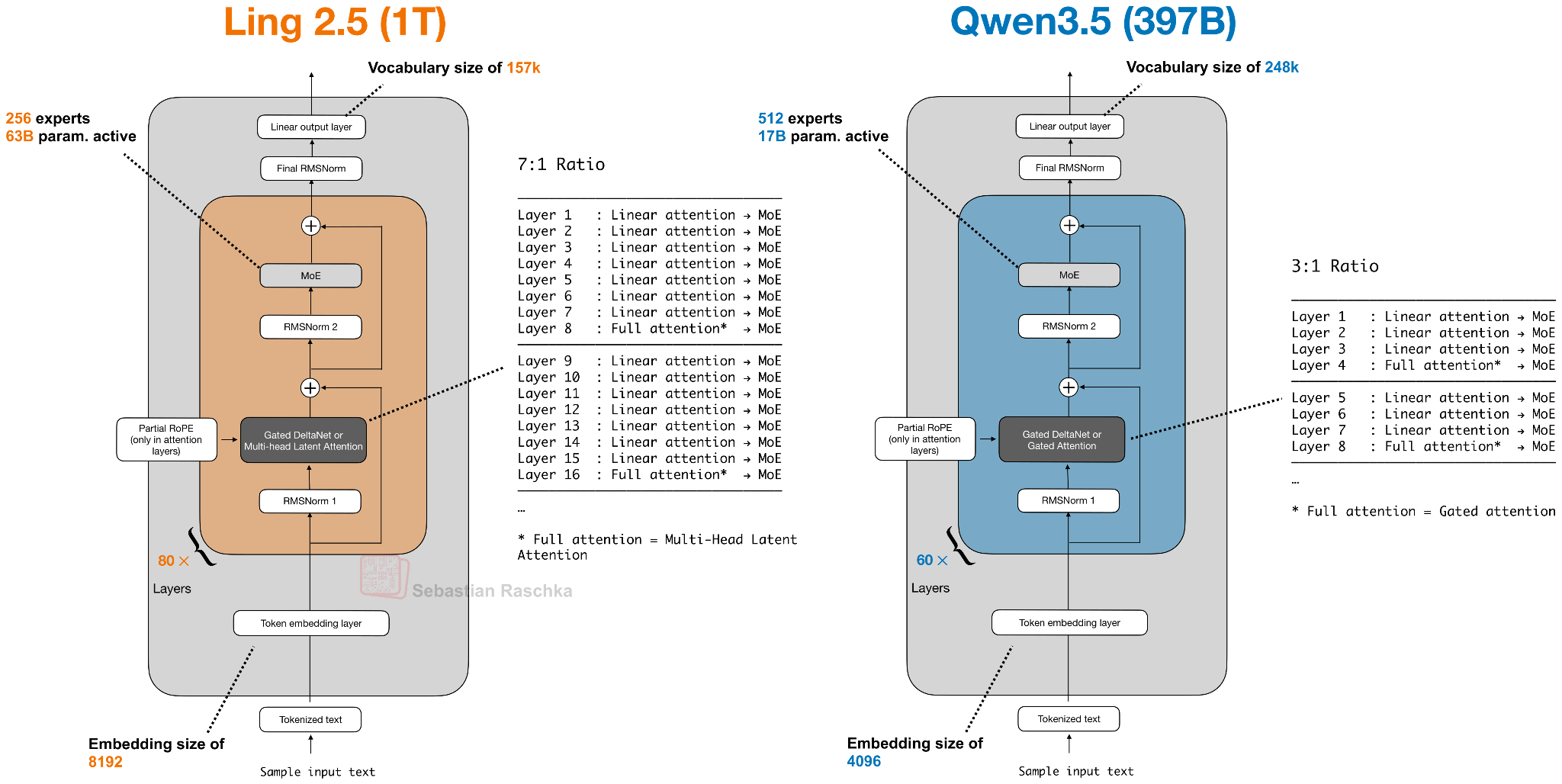
Ling 2.5 (and the reasoning variant Ring 2.5) are 1-trillion-parameter LLMs with a hybrid attention architecture in a similar spirit to Qwen3.5 and Qwen3-Next.
However, instead of Gated DeltaNet, they use a slightly simpler recurrent linear attention variant called Lightning Attention. In addition, Ling 2.5 adopts the Multi-Head Latent Attention (MLA) mechanism from DeepSeek.
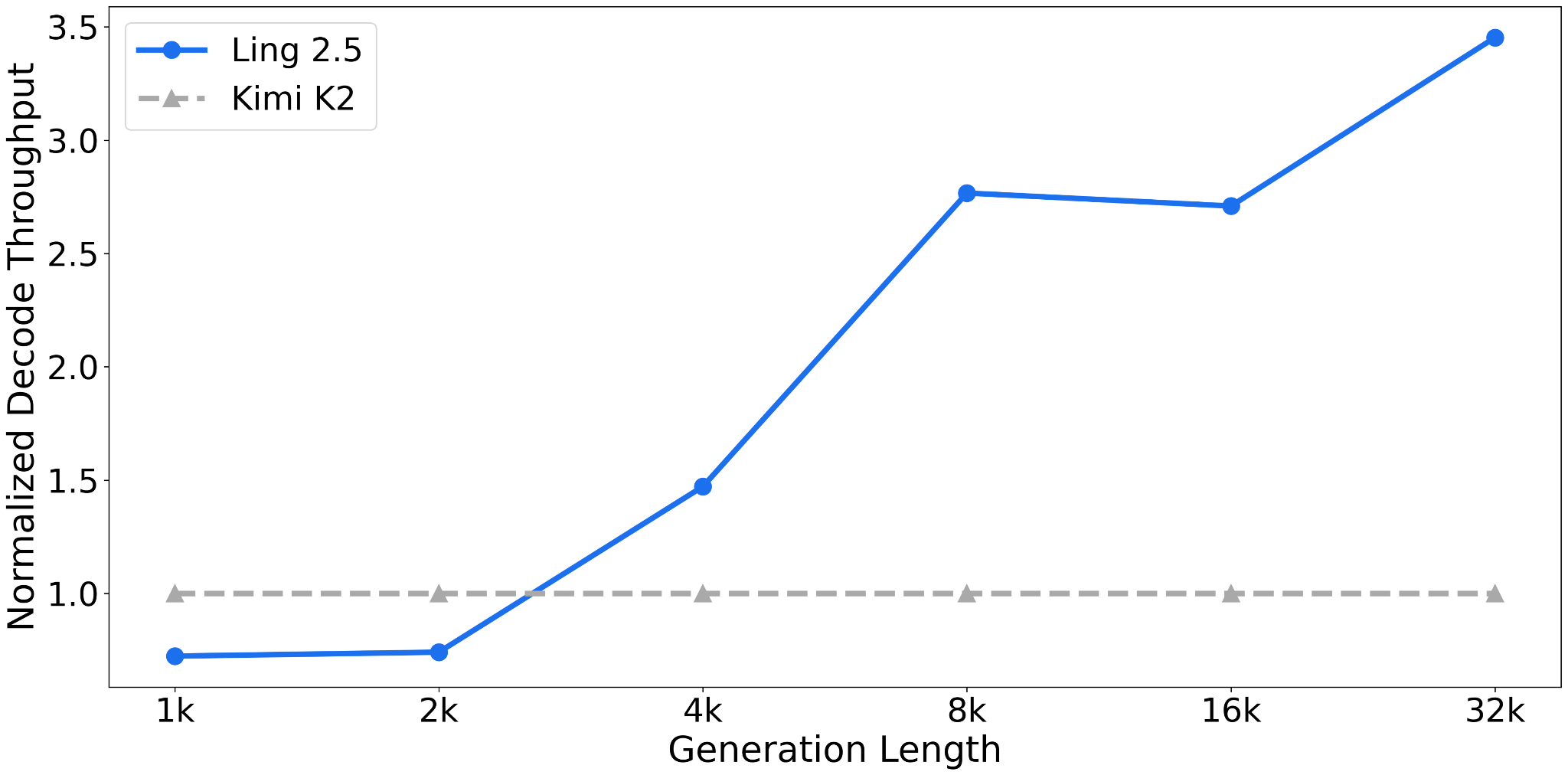
Ling 2.5 is not the strongest model in terms of absolute benchmark performance, but its selling point is very good efficiency in long contexts (due to the hybrid attention). Unfortunately, there are no direct comparisons to Qwen3.5, but compared to Kimi K2 (1T parameters; the same size as Ling 2.5), Ling 2.5 achieves a 3.5x higher throughput at a sequence length of 32k tokens.
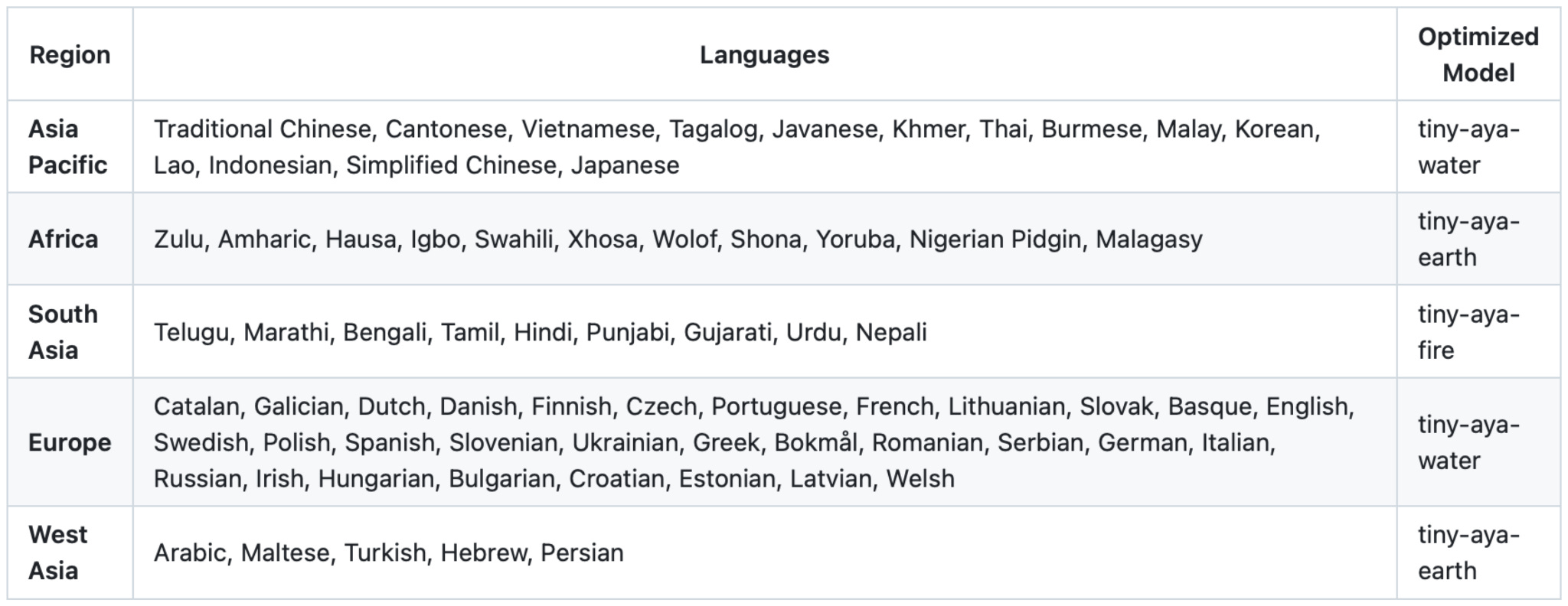
10. Tiny Aya: A 3.35B Model with Strong Multilingual Support
Released on February 17, Tiny Aya is a new, “small” LLM by Cohere that is said to be the “most capable multilingual open-weight model” at the 3B parameter size class. (Tiny Aya outperforms Qwen3-4B, Gemma 3 4B, and Ministral 3 3B according to the announcement post).
This is a great model to run and experiment with locally. The only caveat is that while it’s an open-weight model, its licensing terms are relatively restricted and only allow non-commercial use.
That aside, Aya is a 3.35B parameter model that comes in several flavors that are useful for
personal and (non-commercial) research use:
tiny-aya-base (base model)
tiny-aya-global (best balance across languages and regions)
tiny-aya-fire (optimized for South Asian languages)
tiny-aya-water (optimized for European and Asia Pacific languages)
tiny-aya-earth (optimized for West Asian and African languages)
More specifically, below is a list of languages the models are optimized for.
Architecture-wise, Tiny Aya is a classic decoder-style transformer with a few noteworthy modifications (besides the obvious ones like SwiGLU and Grouped Query Attention), as illustrated in the figure below.
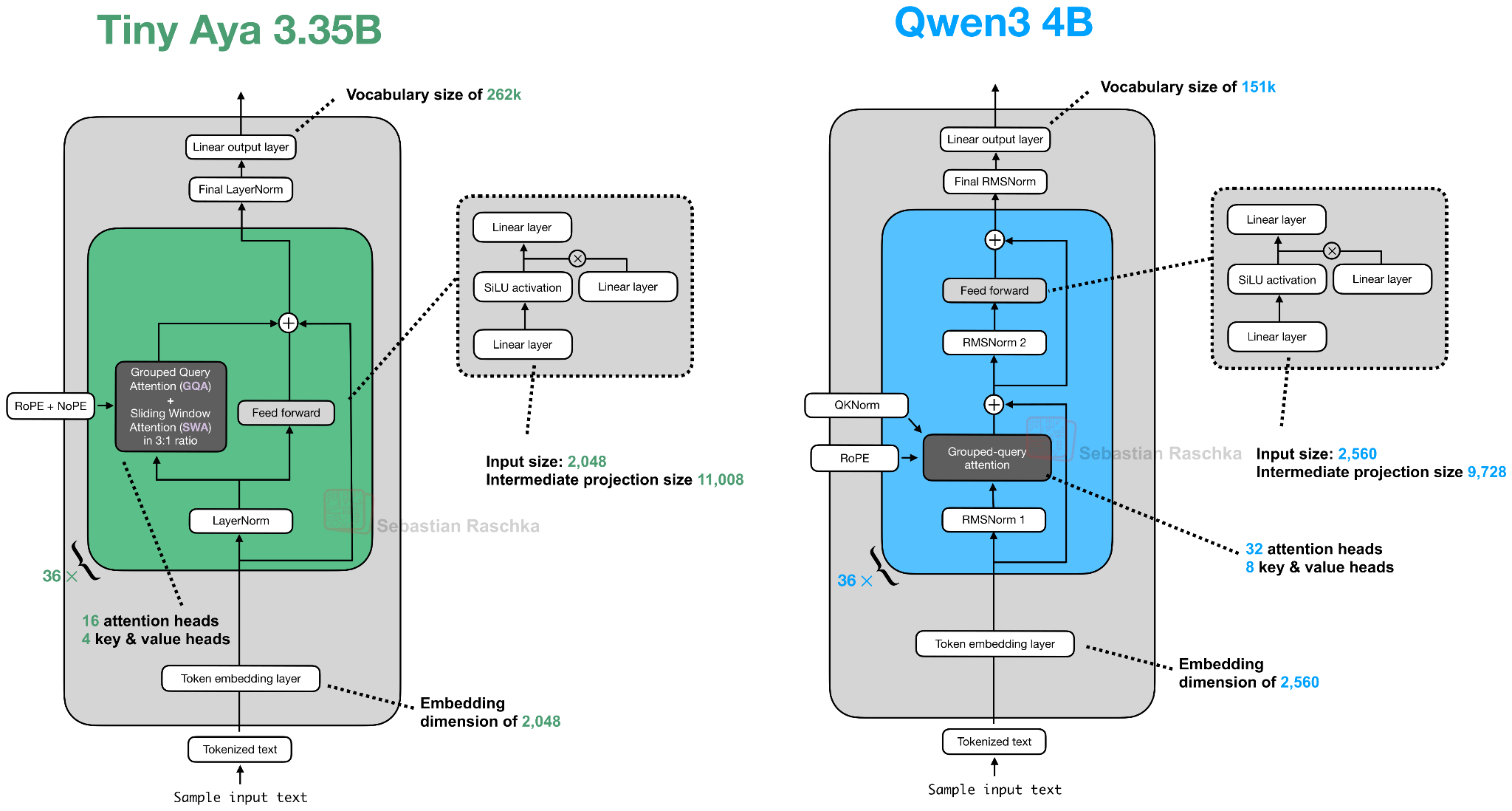
Overall, the most noteworthy highlight in this architecture is the parallel transformer blocks. Here, the parallel transformer block computes attention and an MLP from the same normalized input, then adds both to the residual in a single step. I assume this is to reduce serial dependencies inside a layer to improve computational throughput.
For those readers familiar with Cohere’s Command-A architecture, Tiny Aya seems to be a smaller version of it. Also, an interesting detail is that the Tiny Aya team dropped QK-Norm (an RMSNorm applied to keys and queries inside the attention mechanism); QK-Norm has become quite standard for improving training stability in terms of reducing loss spikes. According to a developer on the Cohere team, QK-Norm was dropped “since it can interact with long context performance.”
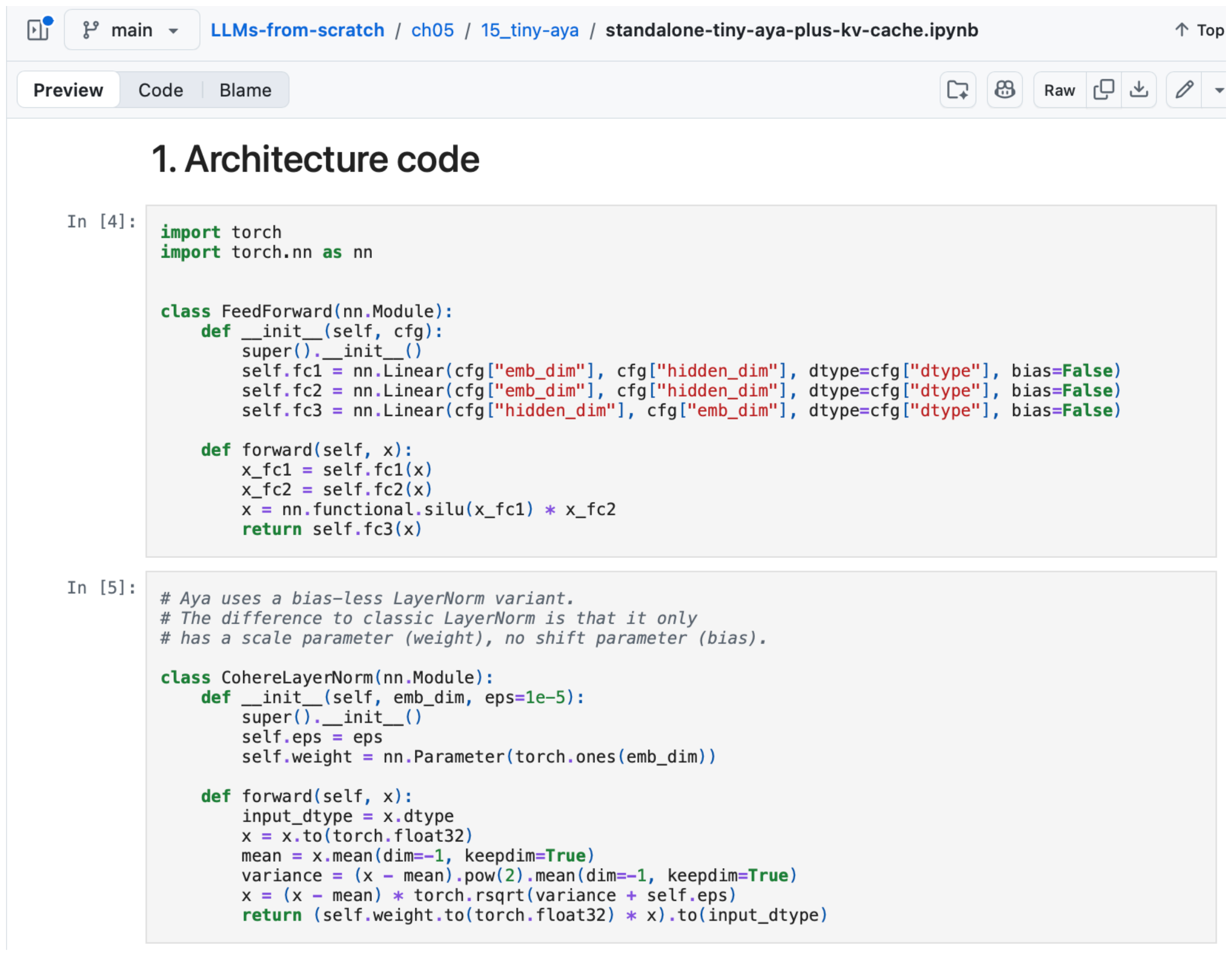
As you may know, I occasionally code architectures from scratch. Since I found the parallel transformer block quite intriguing and the model runs fine on low-end hardware, I implemented it from scratch (for educational purposes), which you can find here on GitHub.
Conclusion
This article was quite the whirlwind tour covering the main open-weight LLM releases around February 2026. If there is a takeaway from this, it’s that there are various model architectures (all derived from the original GPT model) that work well. Modeling performance is likely not attributed to the architecture design itself but rather the dataset quality and training recipes (a good topic for a separate article).
That said, architectural design remains an essential part of building a successful LLM, and many developers seem to be steering towards adding more and more computational performance tweaks. For example, this includes adapting MLA (Kimi K2.5, GLM-5, Ling 2.5) and DeepSeek Sparse Attention (GLM-5) to continue the Gated DeltaNet (Qwen3.5) or similar forms of linear attention (Ling 2.5).
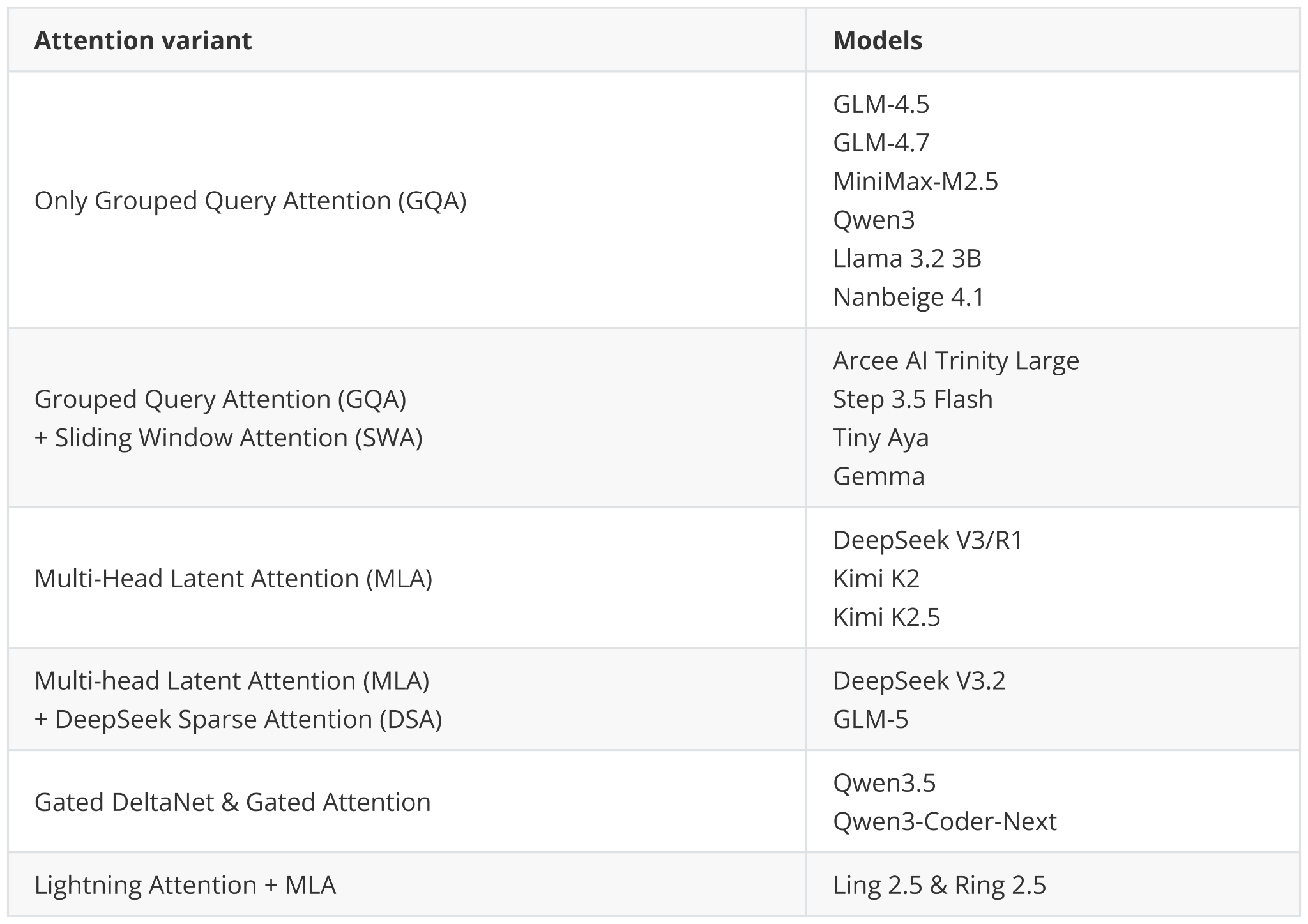
Also, more classic efficiency tweaks like grouped query attention and sliding window attention (Arcee Trinity, Step 3.5 Flash, Tiny Aya) remain popular. Among the new releases, only MiniMax M2.5 and Nanbeige 4.1 stayed very classic here, using only Grouped Query Attention without any other efficiency tweak.
DeepSeek V4
DeepSeek V4 is the model everyone is waiting for. Unfortunately, as of this writing, it hasn’t been released yet. However, I plan to add it to this article once it’s released, which is likely on or before the first week of March.
Another interesting model is Sarvam (30B & 100B) from India. The model was recently announced, but it hasn’t been released yet. Stay tuned for an update here as well.
Update 1: Sarvam 30B and 105B (Mar 6, 2026)
As promised, here is a short update on Sarvam.
While waiting for DeepSeek V4 we got two very strong open-weight LLMs from India.
There are two size flavors, Sarvam 30B and Sarvam 105B model (both reasoning models), which were released as open-weight models on March 6th alongside a fairly detailed announcement blog.
Interestingly, the smaller 30B model uses “classic” Grouped Query Attention (GQA), whereas the larger 105B variant switched to DeepSeek-style Multi-Head Latent Attention (MLA).
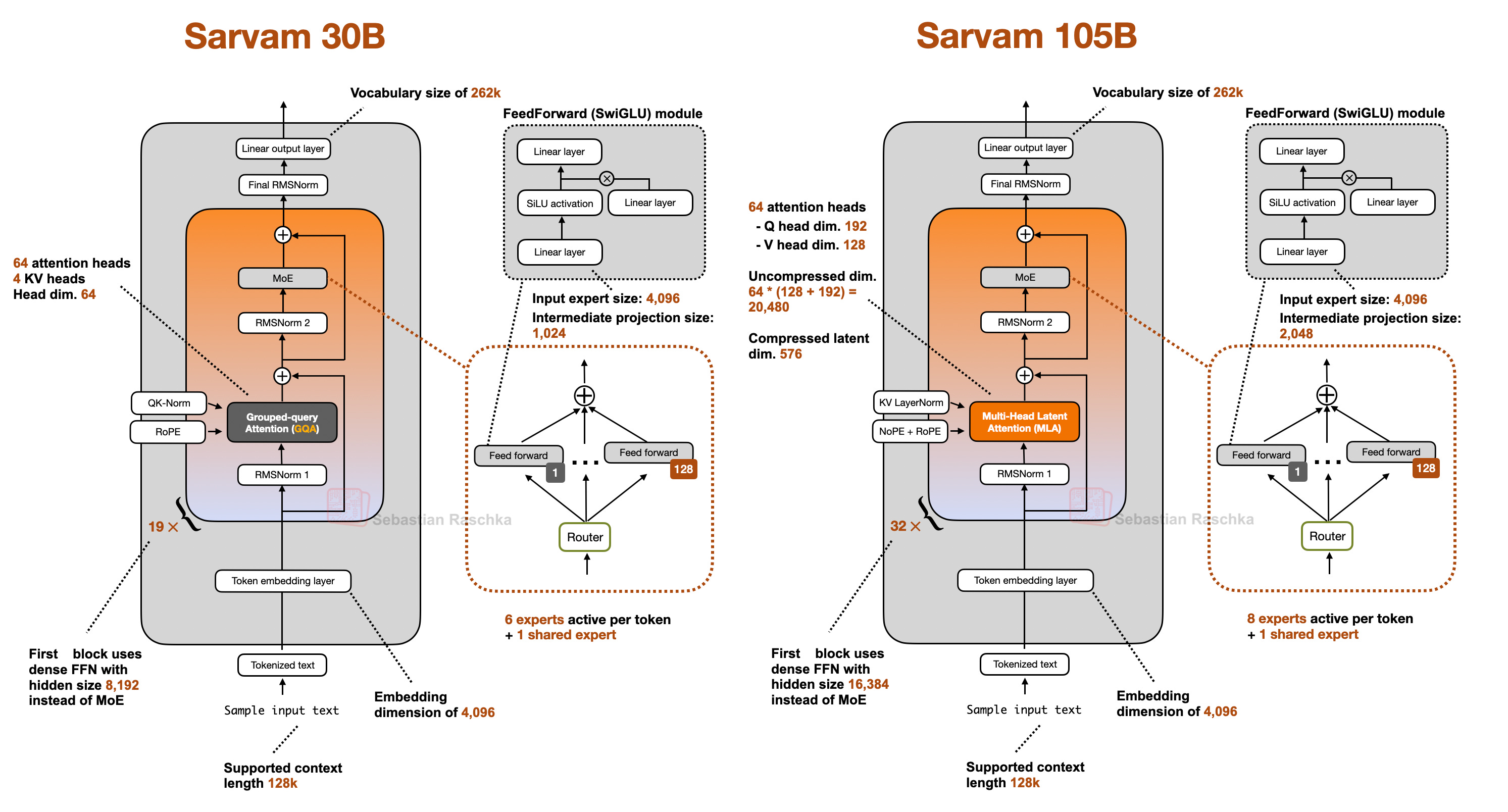
As I wrote about in my analyses before, both are popular attention variants to reduce KV cache size (the longer the context, the more you save compared to regular attention).
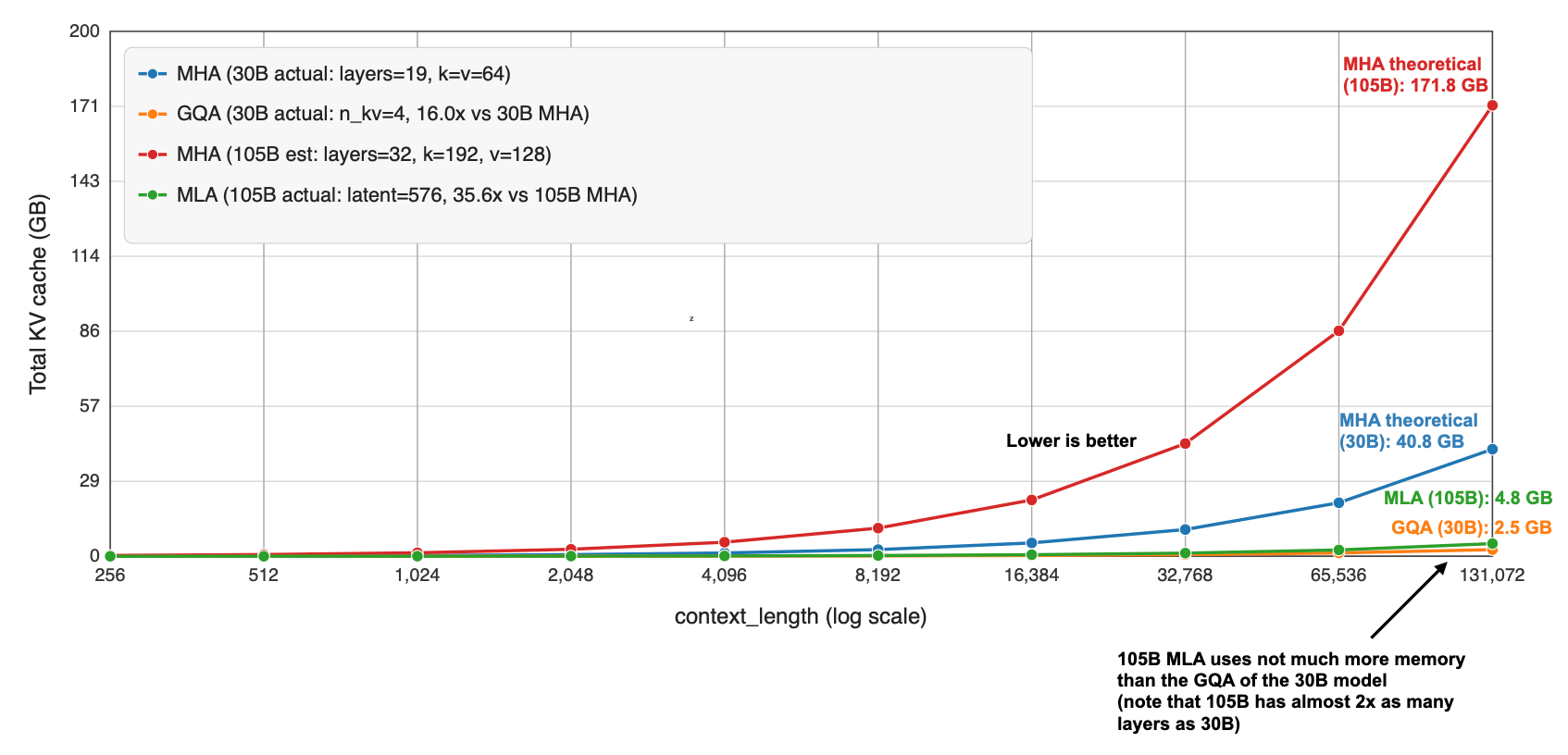
MLA is more complicated to implement, but it can give you better modeling performance if we go by the ablation studies in the 2024 DeepSeek V2 paper (as far as I know, this is still the most recent apples-to-apples comparison).
Speaking of modeling performance, the 105B model is on par with LLMs of similar size: gpt-oss 120B and Qwen3-Next (80B). Sarvam is better on some tasks and worse on others, but roughly the same on average.
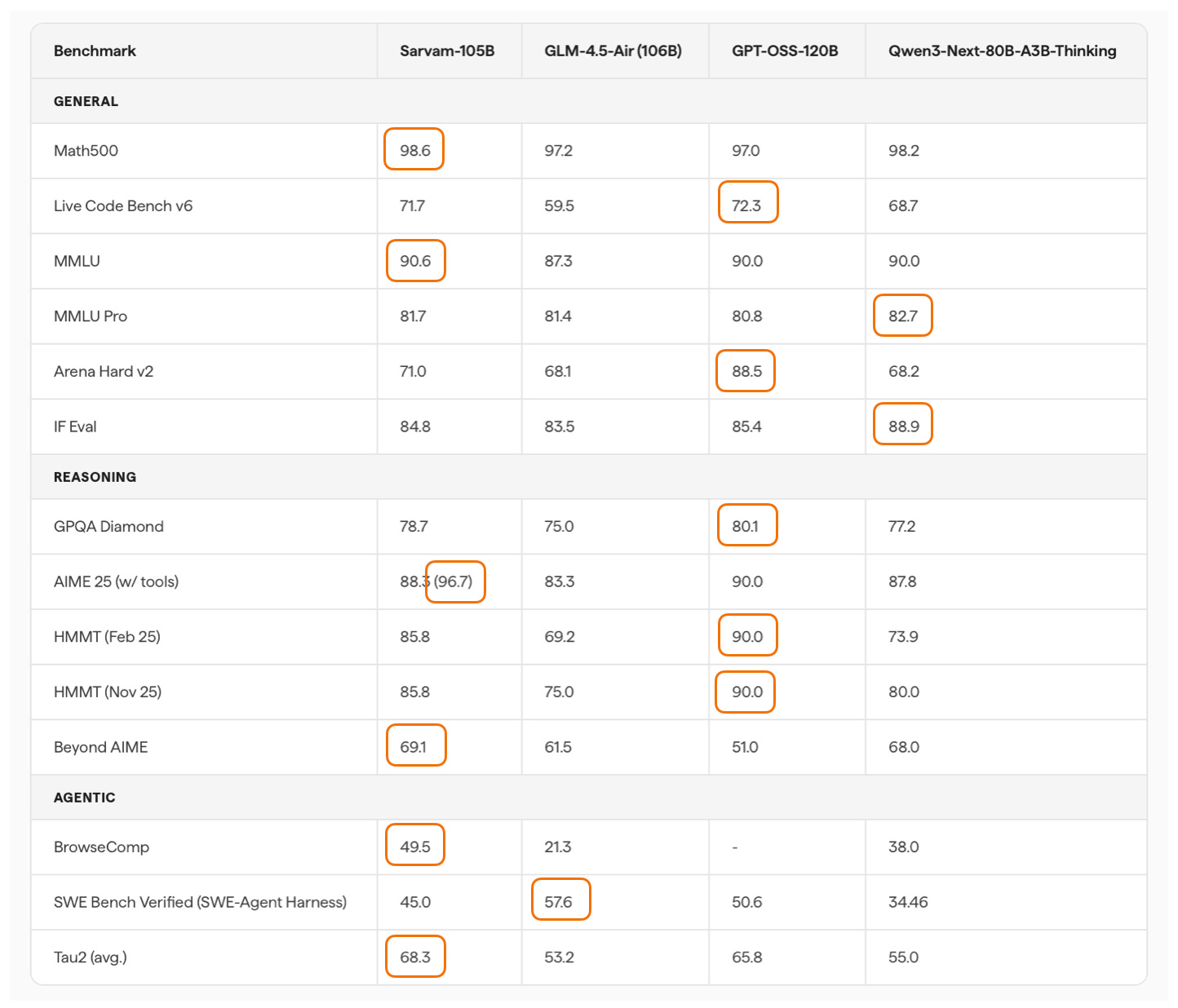
It’s not the strongest coder in SWE-Bench Verified terms, but it is surprisingly good at agentic reasoning and task completion (Tau2). It’s even better than Deepseek R1 0528 (not shown in the figure above).
Considering the smaller Sarvam 30B, the perhaps most comparable model to the 30B model is Nemotron 3 Nano 30B, which is slightly ahead in coding per SWE-Bench Verified and agentic reasoning (Tau2) but slightly worse in some other aspects (Live Code Bench v6, BrowseComp).
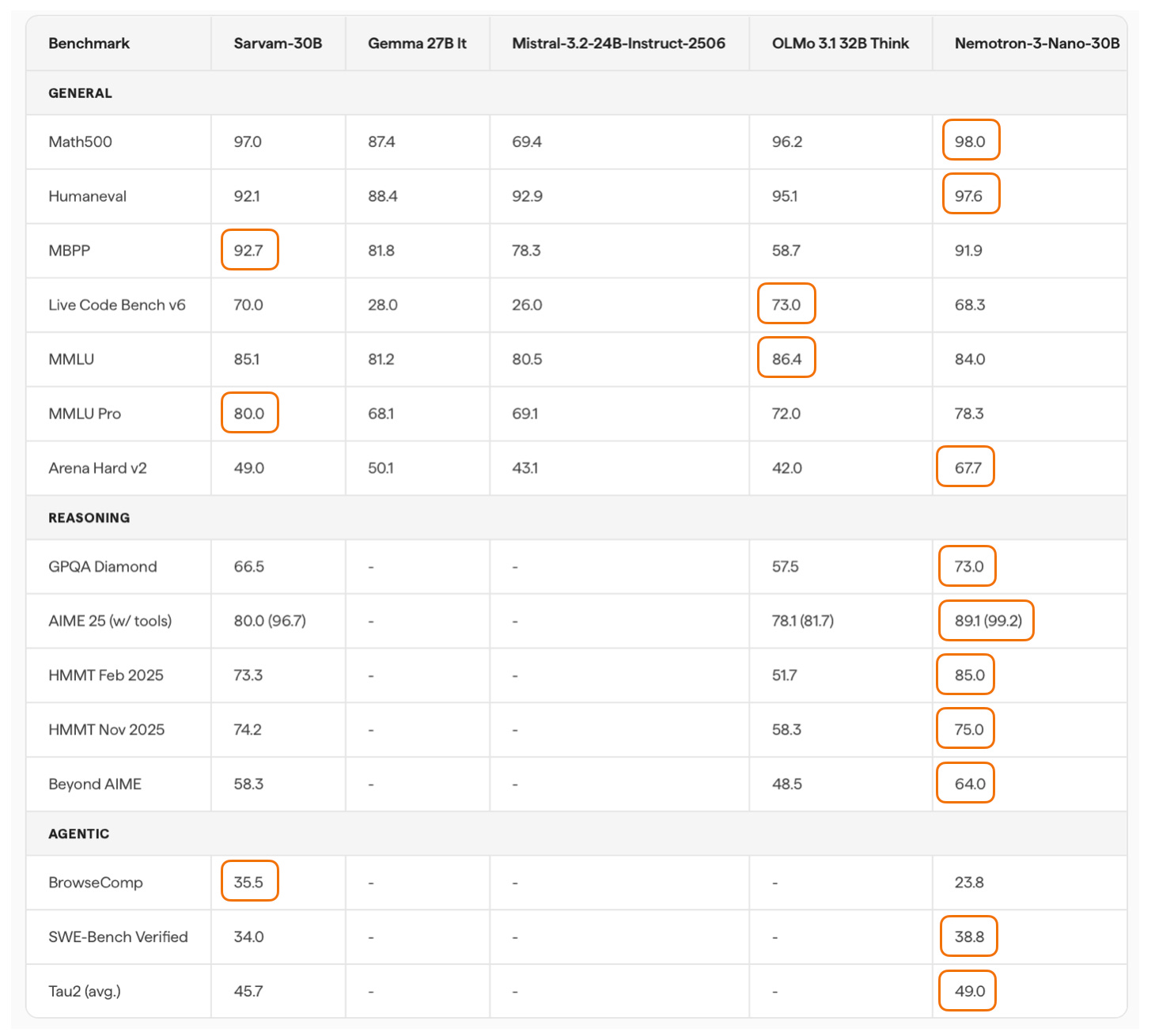
Unfortunately, Qwen3-30B-A3B is missing in the benchmarks above, which is, as far as I know, is the most popular model of that size class. Interestingly, though, the Sarvam team compared their 30B model to Qwen3-30B-A3B on a computational performance analysis, where they found that Sarvam gets 20-40% more tokens/sec throughput compared to Qwen3 due to code and kernel optimizations.
One thing that is not captured by the benchmarks above is Sarvam’s good performance on Indian languages. According to a judge model, the Sarvam team found that their model is preferred 90% of the time compared to others when it comes to Indian texts. (Since they built and trained the tokenizer from scratch as well, Sarvam also comes with a 4 times higher token efficiency on Indian languages.
This magazine is a personal passion project, and your support helps keep it alive.
If you’d like to support my work, please consider a subscription or purchasing a copy of my Build a Large Language Model (From Scratch) book or its follow-up, Build a Reasoning Model (From Scratch). (I’m confident you’ll get a lot out of these; they explain how LLMs work in depth you won’t find elsewhere.)
Thanks for reading, and for helping support independent research!
")
If you read the book and have a few minutes to spare, I’d really appreciate a brief review. It helps us authors a lot!
Your support means a great deal! Thank you!
Really enjoyed this architectural deep-dive — the side-by-side diagrams are genuinely the clearest way to internalize how much design debt is being paid down across the field right now.
The observation about MiniMax M2.5 sticking with plain GQA was what stood out most to me. There's something almost contrarian about choosing simplicity when everyone else is racing toward hybrid linear attention. I'd be curious whether that translates into easier fine-tuning or more predictable scaling behavior in practice.
The note on Tiny Aya dropping QK-Norm for long-context reasons is also a good reminder that "training stability" and "inference behavior" aren't always aligned goals — would love to see an ablation on that tradeoff somewhere.
Looking forward to the DeepSeek V4 addition!
There is a typo in Heading 8: Qwen3.5 and the Continutation of Hybrid Attention. It should be Continuation.