

New Foundation Models: CodeLlama and other highlights in Open-Source AI

In this edition of the newsletter, we direct our attention to one of the most prominent highlights of the summer: the release of the Llama 2 base and chat models, as well as CodeLlama, the latest highlights in the open-source AI large language model (LLM) landscape.
Additionally, we delve into the leaked GPT-4 model details, discussing an analysis of its performance over time and covering emerging alternatives to the prevalent transformer-based LLMs.
OpenAI announced its new finetuning API this week, designed to train the GPT-3.5-turbo on custom data sets. This new offering might further fuel the ongoing conversations around closed, proprietary AI systems and the open-source AI models that can be deployed on-premises.
The field of AI continues to shift and evolve, with significant contributions from the open-source community, including in the development of finetuning technologies such as Llama-Adapters, LoRA, QLoRA, and beyond. I am particularly excited to see what innovations will come from the NeurIPS LLM Efficiency Challenge.
Pretrained Large Language Models
A Closer Look At Llama 2
Let's dive right in and start with (what I consider) the biggest LLM-related release this summer, Llama 2. Meta's Llama 2 is the official successor to the popular LLaMA model. Both the original LLaMA model and Llama 2 releases were accompanied by very detailed research articles, which I highly appreciate:
LLaMA: Open and Efficient Foundation Language Models, Touvron et al., Feb 2023
Llama 2: Open Foundation and Fine-Tuned Chat Models, Touvron et al., Jul 2023
Like LLaMA, Llama 2 is a model suite consisting of multiple pretrained LLMs of different sizes. So, what's new and what's interesting about Llama 2? Let's discuss this one by one.
Naming Conventions
First things first. LLaMA stands for Large Language Model Meta AI. The capitalization makes it a bit tedious to type, but the good news is that the official spelling of its successor is just "Llama 2". So, if you stumble upon LLaMA in this article, I am referring to LLaMA v1, and Llama 2 refers to the new model, which we are focusing on here.
What's New?
Before we discuss individual details further below, here's a brief summary of what's new:
Llama 2 was trained on 40% more data than the original LLaMA model.
Also, Llama 2 now supports 2x larger inputs.
The larger 34B and 70B models have a small architectural change using multi-query attention, which we will discuss later.
Another big change is that the Llama 2 modeling suite now includes finetuned models (via supervised finetuning and reinforcement learning with human feedback); more details later.
The Llama 2 license now permits commercial use.

Model Sizes
LLaMA (7B, 13B, 33B, and 65B) and Llama 2 (7B, 13B, 34B*, and 70B) come in various sizes, offering different modeling performance and computational requirement trade-offs. However, while LLaMA only offered pretrained base models, Llama 2 offers both pretrained base models and finetuned chat models. Here, base model means that it's only been trained on the next-word pretraining task. The finetuned chat models have been finetuned on instruction datasets using supervised learning and reinforcement learning with human feedback (RLHF), but more later.
* (Interestingly, Meta only releases the 7B, 13B, and 70B models, not the 34B model.)
License
Most readers may want to know the license and usage restrictions before deciding whether to invest more time into Llama 2 and read the further details below. While LLaMA was a big hit and a celebrated effort in the research community, it was also mildly criticized for its restrictive license. The LLaMA inference code was open source, whereas the model weights, granted on a case-by-case basis to academic researchers, were not released as open source. In short, the LLaMA license allowed research but not commercial use, whereas the Llama 2 license now also permits use in commercial applications (see the Request to Access page for details). However, while the Llama 2 license is permissive enough for most use cases, it is not an open-source license; as discussed in the article Meta's LLaMa 2 license is not Open Source. Personally, I find the Llama 2 usage terms more than reasonable, even though using the term "open source" may be confusing and potentially misleading here. (Nonetheless, for simplicity, I will group Llama 2 among the open-source models for the remainder of the article.)

Performance of Llama 2 Base Models
Now that we have addressed the license and usage question in the previous paragraph, let's get to the most interesting part and address the elephant in the room: "How good is Llama 2"? To address this question fairly, we have to distinguish between Llama 2 base models and finetuned Llama 2 chat models.
Let's talk about the base models first, which are decoder-style LLMs that have been only trained via the conventional next-word prediction pretraining task.
For more information about decoder-style vs encoder-style LLMs, see my article below:
Understanding Encoder And Decoder LLMs

Several people asked me to dive a bit deeper into large language model (LLM) jargon and explain some of the more technical terms we nowadays take for granted. This includes references to "encoder-style" and "decoder-style" LLMs. What do these terms mean?
In short, Llama 2 base models compare extremely favorably to other open-source models as shown in the annotated figure below.

However, Llama 2 base models perform worse than popular closed-source models, but this is expected since the closed-source models listed in the table below are 1) finetuned and 2) much larger (GPT-3.5 has 175B parameters versus 70B parameters in Llama 2). We will see a fairer comparison to the finetuned Llama 2 models later.

Training Data
The 77-page Llama 2 report is surprisingly detailed, which I really appreciate. Interestingly, though, in contrast to the first LLaMA model, the report doesn't offer any insights into the training data besides the following short description:
> more robust data cleaning, updated our data mixes, trained on 40% more total tokens
We can speculate that this is either due to 1) keeping a competitive advantage over other open source models or 2) avoiding copyright related lawsuits.
The following Business Insider article argues that it might be due to the latter: Llama copyright drama: Meta stops disclosing what data it uses to train the company's giant AI models.
Llama 2 Chat Models
Among the highlights of the Llama 2 model suite are the chat models. These chat models are based on the Llama 2 base models and have undergone additional instruction finetuning similar to InstructGPT and ChatGPT.
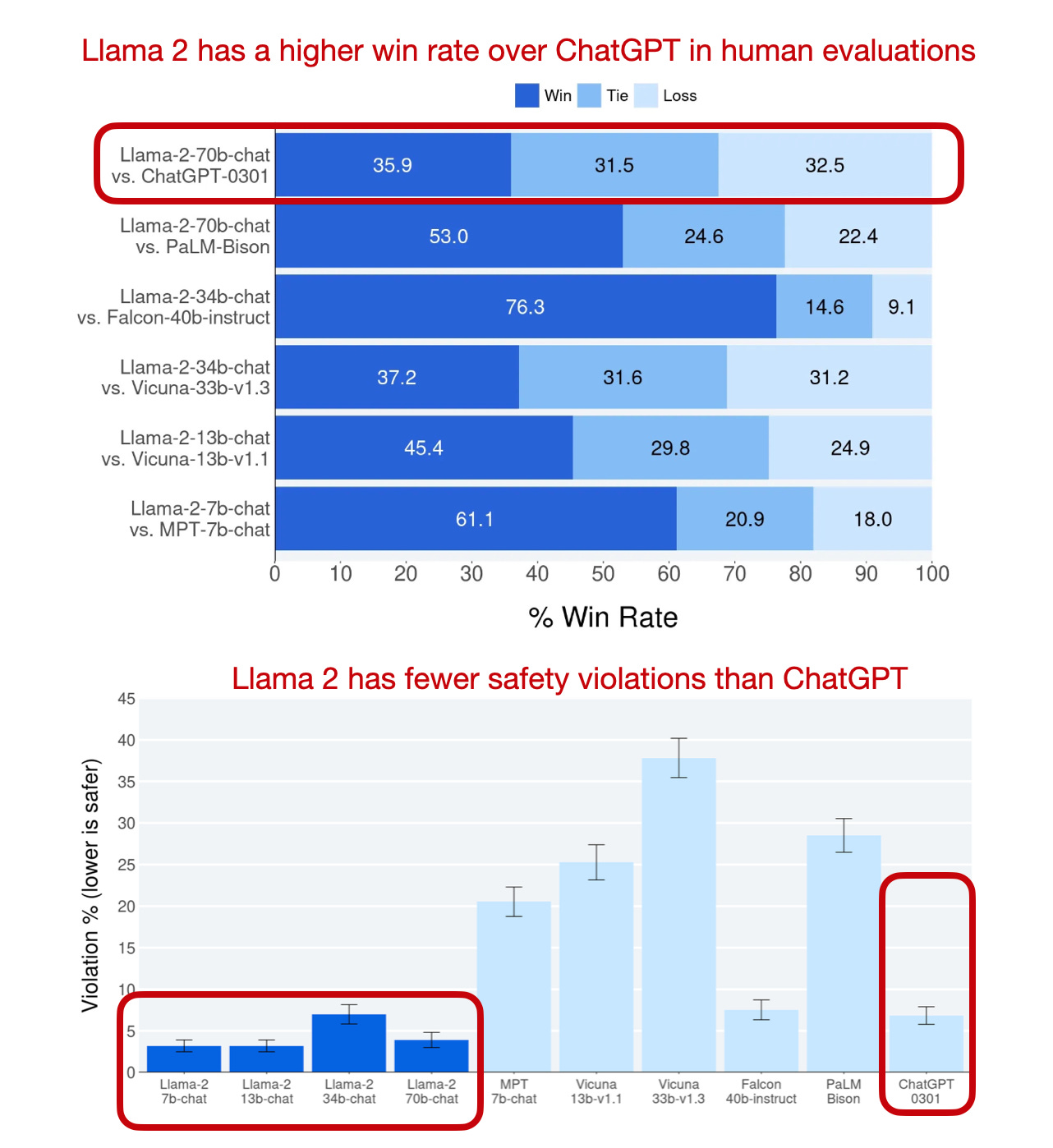
The Llama 2-chat models compare very favorably against other popular chat models, as shown in the annotated figure below.

The finetuning was done in multiple stages: supervised-instruction finetuning as in Alpaca (the first LLaMA model finetuned by researchers at Stanford, and later many other open source LLMs) followed by reinforcement learning with human feedback (RLHF) similar to ChatGPT, as summarized in the annotated figure below.

The section on supervised tuning placed a focus on utilizing a smaller subset of high-quality data, comprising only thousands of samples from their pool of millions. This approach was aligned with the "less is more" philosophy as discussed in the LIMA paper, a subject I previously covered in a previous issue of this newsletter:

Following the initial supervised finetuning, the models were further refined using RLHF. While an in-depth discussion of RLHF is beyond the scope of this already extensive article, further information can be found in a previous issue of this newsletter as well:

It is worth mentioning that InstructGPT and ChatGPT leveraged proximal policy optimization (PPO) for RLHF training. In contrast, the Llama 2 authors conducted experiments with two different methods, rejection sampling and RLHF with PPO.
The authors also nicely illustrated the evolution of the Llama 2 70B Chat models, tracing their journey from the initial supervised finetuning (SFT-v1) to the final RLHF finetuning stage with PPO (RLHF-v5). The chart reflects consistent improvements in both the harmlessness and helpfulness axes, as shown in the annotated plots below.

In the future, it will be interesting how Direct Policy Optimization (DPO), a reinforcement learning-free alternative I previously covered in AI Research Highlights In 3 Sentences Or Less (May-June 2023), compares to these RLHF approaches.
Llama 2 Implementation Details and Interesting Tidbits
The Llama 2 paper is very detailed, and covering all its aspects in this newsletter issue would be impossible. However, below, I wanted to highlight a few more tidbits that I found interesting.
For instance, 34B and 70B parameter Llama models use grouped-query attention (GQA). GQA can be regarded as a more generalized form of multi-query attention, a concept previously employed in models such as Falcon.
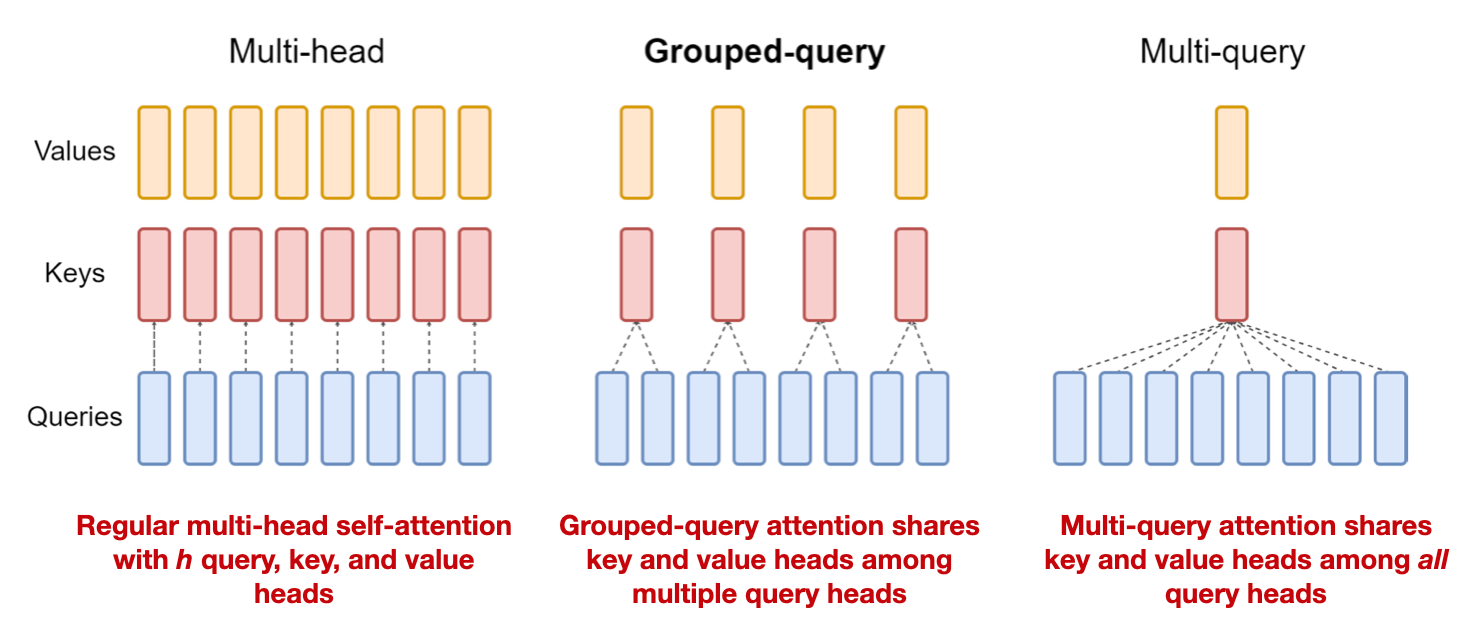
The likely motivation behind this is to reduce computational requirements with minimal impacts on the modeling performance.
Do we still need to finetune models?
While the Llama 2 base and chat models perform well, there's still room for improvement through finetuning. Think of Llama 2 as a revised foundational model that can be further fine-tuned for more specialized tasks.
To illustrate the potential benefit of finetuning, let's take the example of the BoolQ benchmark. Surprisingly, Llama 2 doesn't outperform DeBERTa-1.5B, an encoder-only model, on this particular task. It's a reminder that even strong models like Llama 2 can be outperformed by smaller finetuned models, especially when targeting specific tasks.

For fairness, the DeBERTa-1.5B model (initially proposed at ICLR 2021) was finetuned on the training data portion of BoolQ, whereas Llama 2 was used via few-shot prompting.
While this experiment has not been done yet, a finetuned Llama 2 model could perform even better on this dataset -- or at least better than the Llama 2 base model.
(And as shown via DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing at ICLR 2023, it's also possible to even use a much smaller 300M parameter model for good performance on this task.)
Using Llama 2
As we've seen above, Llama 2 is an extremely capable model. However, how do we use Llama 2 in a custom project?
Meta maintains a GitHub repository with the inference code to use the Llama 2 weights.
In addition, Llama is now also supported in Lit-GPT, an open-source repository that supports a large variety of LLMs for pretraining and finetuning. Among others, I recently helped implement QLoRA support in Lit-GPT and included a few Llama 2 performance benchmarks below.

Andrej Karpathy also released a GitHub repository for Llama 2 inference (not pretraining or finetuning) in just plain C code, which can be interesting for tinkers who want to just run but not finetune Llama 2.
Code Llama
Llama 2 is awesome. However, coding tasks were not its strong suit. For instance, the HumanEval benchmark is a coding-related benchmark from the paper Evaluating Large Language Models Trained on Code.

Two days ago, Meta released a new suite of code models (7B, 13B, and 34B), under the same license as Llama 2, that have been specifically trained on code. These models come in three flavors: a general code model (Code Llama), an instruction-following model (Code Llama-instruct), and a version specialized to Python code (Code Llama-Python). Note that all Code Llama models were initialized with Llama 2 weights before they were further trained on code.
The 34B Code Llama model is about twice as good as the original 70B Llama 2 model, closing the gap to (the much larger) GPT-4.

Why No 70B Code Llama Model?
Interestingly, Code Llama is only available as 7B, 13B, and 34B parameter versions; unlike Llama 2, there is no 70B version. While the paper doesn’t provide any explanation, I suspect this could be due to two reasons:
The Code Llama models were trained on 500B additional code tokens, starting with Llama 2 weights, whereas Llama 2 models were trained on 2T tokens. Since the Code Llama model was trained on 4x fewer domain-specific tokens, maybe a CodeLlama 70B version did not perform well enough due to LLM scaling laws—there was not enough training data.
Code Llama models support context sizes of 100k, which is very useful when working with code. Llama 2, in contrast, only supports up to 4k tokens as input. These 70B models may be computationally infeasible (or reasonable hardware clusters) if they were to support 100k token inputs.
GPT-4 Model Details Have Leaked
Switching gears from open-source to closed-source models, there have also been a few interesting news on the GPT-4 front last month. For instance, the GPT-4 mode details have now apparently (finally) been leaked:
> GPT-4 is a language model with approximately 1.8 trillion parameters across 120 layers, 10x larger than GPT-3. It uses a Mixture of Experts (MoE) model with 16 experts, each having about 111 billion parameters. Utilizing MoE allows for more efficient use of resources during inference, needing only about 280 billion parameters and 560 TFLOPs, compared to the 1.8 trillion parameters and 3,700 TFLOPs required for a purely dense model.
> The model is trained on approximately 13 trillion tokens from various sources, including internet data, books, and research papers. To reduce training costs, OpenAI employs tensor and pipeline parallelism, and a large batch size of 60 million. The estimated training cost for GPT-4 is around $63 million.
Source: https://www.reddit.com/r/LocalLLaMA/comments/14wbmio/gpt4_details_leaked/
In particular, the fact that GPT-4 is apparently using a Mixture of Experts (MoE) approach is very interesting and important to highlight. MoE means that it is to improve the performance of a system by combining the predictions or decisions of several specialized sub-models or "experts."
So, suppose we want to improve models like Llama 2 further and outperform GPT-4-like offerings (by a large margin). In that case, we may not only have to scale the model to a similar size (in this case, 25x larger to be comparable) but also consider using MoE approaches.
Is GPT-4 Getting Worse?
We often see claims that OpenAI degrades the ChatGPT performance over time to save computation time and cost. In the recent How is ChatGPT's behavior changing over time? paper, researchers make an interesting observation that GPT-4's modeling performance appears to be indeed getting worse over time. Is it due to distillation methods to save costs or guard rails to prevent certain types of misuse? (By the way, it is interesting to see research efforts being diverted into studying these changes that could likely already be answered by a researcher and engineers who worked on these models.)

As a follow-up, I highly recommend reading the Substack article Is GPT-4 getting worse over time? by Sayash Kapoor and Arvind Narayananwho highlight important shortcomings of the research article above. For instance,
> What seems to have changed is that the March version of GPT-4 almost always guesses that the number is prime, and the June version almost always guesses that it is composite. The authors interpret this as a massive performance drop — since they only test primes. For GPT-3.5, this behavior is reversed.
So, the claim that GPT-4 is getting worse over time may not be necessarily true. There are ongoing changes with regard to its behavior, though.
In practice, one of the biggest advantages of using an API is that we don't have to worry about hosting and serving the model itself. However, this is also the biggest shortcoming if we build services on top of it. Sure, performance improvements are usually appreciated. However, intransparent changes to the model behavior can also cause all your previously working queries to not work reliably the next morning. The more you build on top of a closed API, the more annoying this problem can become.
ChatGPT Finetuning As A Service
Last Wednesday, OpenAI announced its new finetuning service for ChatGPT. This is super interesting for those who want to finetune LLMs on custom data.
It will be interesting to see how it fares against open-source solutions from which the most recent cutting-edge finetuning techniques emerged (Llama-Adapters, LoRA, QLoRA, and more).
Also, the recent open-source Llama 2 model, which we discussed above, compares very favorably to ChatGPT / GPT-3.5, as shown below.
Based on the OpenAI documentation and marketing materials, it doesn't seem like the service will be restricted to just changing the style or tone of the LLM's responses. Instead, it appears that OpenAI is offering a fully-fledged instruction tuning service.
However, this also means it will likely still be impossible to fully adapt the models to new specialized target domains like medical, financial, or legal contexts. That's because new knowledge is usually ingested via pretraining, not finetuning; this is also true for open-source models.

While OpenAI does not specify which finetuning method they will use, opting for low-rank adaptation (LoRA) as a finetuning technique would make sense. I believe this would be the easiest and most cost-effective because they won't have to store a new 175B parameter LLM for each customer. With LoRA, you can use the same base LLM but only need to store the LoRA weights.
Scaling LLMs and Alternatives to Transformer-based LLMs
One of the open research challenges is how to extend LLMs to larger input contexts. Recent approaches include
1) the RMT paper on scaling transformers to 1 million tokens;
2) the convolutional Hyena LLM for 1 million tokens;
3) LongNet: scaling transformers to 1 billion tokens.
While there are several use cases for such long LLMs, for example, asking questions about particular long document inputs, the elephant in the room is: How well do LLMs use these longer contexts?
New research (Lost in the Middle: How Language Models Use Long Contexts) shows that LLMs are good at retrieving information at the beginning of documents. They do less well in terms of retrieving information if it's contained in the middle of a document.

The analysis in this paper is focused on ChatGPT (as it's shown in the figure) and Claude. Of course, it would be interesting to include other models (Hyena, LongNet etc.) in the future.
Nonetheless, this is quite interesting!
1) I would expect that the opposite is true for, e.g., RNN-based LLMs like RWKV (since it's processing information sequentially, it might rather forget early information)
2) To my knowledge, there is no specific inductive bias in transformer-based LLM architectures that explains why the retrieval performance should be worse for text in the middle of the document. I suspect it is all because of the training data and how humans write: the most important information is usually in the beginning or the end (think paper Abstracts and Conclusion sections), and it's then how LLMs parameterize the attention weights during training.
More Transformer Alternatives
I mentioned several alternatives to transformer-based LLMs in the paragraph above, such as the recurrent RWKV LLM and the convolutional Hyena LLM.
The newest transformer alternative is Retentive Network (also called RentionNet), which was proposed in a paper last month with a bold headline: Retentive Network: A Successor to Transformer for Large Language Models.
This paper proposes another alternative to large language transformers, one that has linear instead of quadratic complexity concerning the input sequence lengths. RetentionNet can be trained in a parallel mode and switched to a recurrent model to extend context lengths without increasing memory cost to achieve good inference performance. The largest model was 6.7B parameters, and it will be interesting to see future studies comparing RetNet to Llama-2 70B and others.

Will it be a widely used alternative to transformer-based LLMs? After the initial hype, it doesn't seem like it's being adopted in any other projects at the moment, but time will tell.
What are "Frontier AI Models"?
The AI community loves coining new terms!
For quite a while, I found myself resistant to using the term "foundation model." I was convinced that there was no need to introduce a new phrase to describe pretrained large language models (LLMs) or pretrained vision transformers (ViTs).
Initially, many people saw the paper that coined the term "foundation model" appeared to provide academics as a means to garner citations. (This sentiment was evidenced by the 113-author Stanford article that coined this term, collecting 1372 citations as of today.) However, despite early criticisms, the term has started to gain more widespread acceptance in recent times. In keeping with this trend, I've also begun incorporating "foundation models" into my vocabulary.
Last month, authors from the Centre for the Governance of AI (with co-authors from Google DeepMind, OpenAI, and Microsoft): wrote a new paper, Frontier AI Regulation: Managing Emerging Risks to Public Safety to coin a new term “frontier AI models” on top of foundation models:
> We define “frontier AI models” as highly capable foundation models that could exhibit dangerous capabilities.
We live in interesting times.
Hardware Corner
Despite or because of all the recent LLM progress, there's been an ongoing GPU shortage, especially when it comes to NVIDIA's H100 chips. As VentureBeat recently reported, Nvidia GPU shortage is ‘top gossip’ of Silicon Valley.
While everyone is fighting over H100, NVIDIA also announced its next generation of GPUs, the GH200, which is going to offer 141 GB of RAM (as opposed to 80 GB in the H100) -- maybe another way of solving the LLM long-context problem with brute (hardware) force.

LLMs and Copyright Laws
What is the current status on LLMs and generative AI regarding copyright laws? 8 months into 2023, it seems that this question still doesn't have (m)any definitive answers. Below, I polled a few articles based on the best of my knowledge. However if you have any additional insights or resources, I'd love to hear! Note that I am not a lawyer and cannot comment on any of the legal aspects. Also, since I am not a lawyer, the following information should not be taken as legal advice.
According to Wikipedia, "The copyright status of LLMs trained on copyrighted material is not yet fully understood."
In this context, a recent article and study that appeared in the Atlantic, Revealed: The Authors Whose Pirated Books Are Powering Generative AI is worth highlighting.
This article addresses the recent legal action taken by various authors against Meta, accusing the company of utilizing their copyrighted works in the training of LLaMA v1. The reason for this lawsuit was the training data, which included Books3 section of The Pile, encompassing no less than 170,000 books. Notably, the same dataset was used for EleutherAI's GPT-J (a model similar to GPT-3) and BloombergGPT, Bloomberg's language model for finance, which was detailed in the third issue of Ahead of AI.
Moreover, NPR recently reported that the New York Times is preparing a lawsuit against OpenAI since it's concerned that ChatGPT generates text that responds to inquiries, drawing from the initial reporting and writing produced by the paper's team.
Laws are laws, and developers should work with content creators to avoid violating copyright laws. In addition, it would be helpful if there were updated legal guidelines that clearly address the use of LLMs. For drafting policies or amending laws, it could be helpful to consider "fair use" contexts. In other words, it may also be helpful to distinguish between LLMs developed for commercial purposes (for example, ChatGPT) and LLMs that are solely developed for research purposes whose licenses forbid commercial applications (for example, Meta's LLaMA).
What is "fair use"? According to Wikipedia, in the United States, the principle of "fair use" within copyright law may allow the utilization of copyrighted materials without authorization, provided that the use involves a substantial transformation of the work and does not endanger the copyright owner's interests. However, whether this concept of fair use extends to the training of machine learning models is still unresolved.
How do other countries handle the use and training of AI concerning copyrighted materials?
A few months ago, PetaPixel and other news websites reported that Japan declared that it would permit generative AI training on any kind of data and that it will not enforce copyrights when it comes to training generative AI models.
The AI Act in the EU requires companies to publicly disclose any copyrighted work used in training, as reported by Lexology. However, this article is not very clear on what happens if copyrights are violated.
Overall, it seems that a lot of rules are still being drafted and amended. I am hoping that the rules, whatever they are, remain clear so that AI researchers and practitioners can adjust and act accordingly.
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
It's a real pleasure to read the summary of such a knowledgeable man as you, kudos!
Now, I'm a little bit surprised that you didn't introduce multi-modality in LLMs as a main axis of research/differentiation. Pairing text to vision is already relatively straightforward and there is also sub-modality differentiation in the sound landscape with speech to text enlarged to text to sound (e.g. the Bark model), but this is only the beginning....
IMHO, generalized multi-modality it is a too neglected straightforward path towards AGI as it would solve a good part o the thorny issue of symbol grounding in those models (the other parts being feedback from retro-action from the world to the models, a direct pathway toward the synthesis of genuine evolved intentionality).
With models encompassing our 5 senses and proprioception, they should evolve inner world representations more aligned with human ones. One can even speculate if those LLMs would converge toward an universal underlying neural coding scheme like e.g. a kind of Grossberg' ART refinement, as described in this paper, https://www.mdpi.com/2078-2489/14/2/82
Awesome write-up. I tend to try to follow the news as they occur, but you do such a great job in distilling everything that I may just consume your newsletter. I wonder if you use any LLM to help you writing or organizing raw text.