

Large Language Models 3.0

Large Language Models 1.0. It's been about half a decade since we saw the emergence of the original transformer model, BERT, BLOOM, GPT 1 to 3, and many more. This generation of large language models (LLMs) peaked with PaLM, Chinchilla, and LLaMA. What this first generation of transformers has in common is that they were all pretrained on large unlabeled text corpora.
Large Language Models 2.0. Recently, we have seen many pretrained LLMs being finetuned on labeled target data, either using reinforcement learning with human feedback or more classic supervised learning objectives, as discussed in the previous issue of Ahead of AI. Popular examples of these second-generation LLMs include InstructGPT and ChatGPT, as well as Alpaca and Bard (discussed in this newsletter)
Large Language Models 3.0. It's interesting to think about what the 3rd generation of large language models looks like. Popular themes in recent months were parameter-efficient finetuning and pretraining on domain-specific data (examples are discussed later in this newsletter). However, parameter-efficient finetuning and pretraining on domain-specific data are ways to leverage LLMs more computationally and data-efficiently. Instead, the next generation of LLMs is likely centered around multimodal and multitask learning, bringing new capabilities to large language models. I expect to see more research in this direction in the upcoming months.
This newsletter, among others, covers recent large language models centered around parameter efficiency and multimodality. Note that this month has also been extremely strong for open-source AI, so the Open Source Highlights are particularly exciting this time.
Articles & Trends
Extending LLaMA
Last month, Meta's LLaMA alternative to GPT-3 made big waves (we covered LLaMA in the previous issue of Ahead of AI). As a testament to how quickly the AI research field is moving these days, there were already many projects building on top of LLaMA.
One of the notable projects is Alpaca. Alpaca is an instruction-finetuned 7B language transformer based on the 7B LLaMA model. However, instead of using reinforcement learning with human feedback (RLHF, covered in Ahead of AI issue 6), Alpaca takes a supervised approach using 52k instruction-output pairs.
Instead of using human-generated instruction-output pairs, the researchers retrieved the data by querying the GPT-3-based text-davinci-003 model. So, Alpaca essentially uses a form of weakly supervised or knowledge-distillation-flavored finetuning. Note that this can be competitive with human annotations. For example, in the Self-Instruct paper (https://arxiv.org/abs/2212.10560), the authors found that bootstrapping a model on its generations can result in performance competitive with InstructGPT.

The training recipe is available on GitHub, and according to the authors, it can be replicated with 8 A100 GPUs and a ~$600 budget.
Here's a small wishlist in case the authors are working on an Alpaca research paper:
Why 52k instruction-output pairs (and not more or less)? What are the scaling laws for finetuning here?
How does the performance of supervised finetuning here compare with proximal policy optimization-based finetuning?
Is there a significant performance difference when swapping text-davinci-003 with ChatGPT's GPT 3.5 or GPT 4?
Note that the Alpaca website (crfm.stanford.edu/alpaca/) was recently taken down, but the project is still available on GitHub. The reason why Alpaca was taken down is summarized in this news article -- it "can generate false information, propagate social stereotypes, and produce toxic language."
Making Finetuning More Efficient
Classically, we finetune large language models by either updating all layers or by only swapping and updating the output layers -- in my experience, updating all layers is computationally more intensive but leads to much better predictive performance (I am covering this in the upcoming Unit 8 of Deep Learning Fundamentals).

Recently, researchers began focusing on alternative finetuning paradigms that are more compute- and memory-friendly. These paradigms are commonly referred to as parameter-efficient finetuning methods. I am skipping a detailed discussion of these techniques in this issue. However, I recommend the excellent Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning survey published last week, which provides an excellent overview.

A notable new parameter-efficient finetuning technique is LLaMA-Adapter covered below.
LLaMA-Adapters For Parameter-Efficient Finetuning of LLMs
In the LLaMA-Adapter: Efficient Fine-tuning of LLaMA paper, the authors propose an adapter method that allows using LLaMA for instruction finetuning.
In contrast to the aforementioned Alpaca method, LLaMA-Adapter does not finetune the whole model end-to-end. Instead, it adds a small number of 1.2M parameters on top of a pretrained, frozen 7B LLaMA model.
Using the same 52K Instruction-following examples that Alpaca used, responses are comparable to Alpaca. But in contrast to Alpaca, which took 3 hours on 8 A100 to finetune, LLaMA adapters can be finetuned in 1/3 of the time. (Caveat: Matching the modeling performance was mentioned in the paper, but I couldn't find any metrics.)
To make it work well in practice, the researchers also proposed a gating mechanism, initialized to all zeros, to prevent the adapters from perturbing the performance of the pretrained LLaMA model at the beginning of the training.

This adapter method is particularly interesting as it allows us to add other input modalities like image and video tokens, which brings us to the next topic: multimodal LLMs.
Multimodality Might Be the Next Big Thing: PaLM-E
What's next for large language models (LLMs)? Unfortunately, it's hard to tell. We've seen that pure text models are getting better and better. However, it is difficult to say whether we are approaching the limit of what pure text LLMs are capable of, whether with pretraining on general language corpora or finetuning on labeled target datasets.
I am pretty confident that we will see much more research and experiments on making pure text models perform better, for example, by increasing parameter or dataset sizes or improving the architecture and training techniques.
Nonetheless, it's interesting to think about other directions future LLM developments will focus us. For example, the next trend may be focused on extending the capabilities with vision, other modalities, and multitask training.
Last year, Google published PaLM: Scaling Language Modeling with Pathways -- a strong alternative to GPT. Now, about one year later, PaLM-E: An Embodied Multimodal Language Model was just released. So let's take a look at what that is all about.
The focus of PaLM-E was on robotic manipulation planning. But interestingly, the model also showed emergent abilities for visual question answering and captioning when trained on multimodel inputs. Of course, PaLM-E is not the first language model that also supports image inputs. However, what's interesting and novel here is that one or more images can be flexibly included in any part of the sentence.
It should be noted that PaLM-E continues to be trained as a solely decoder-based LLM, which autoregressively generates text completions based on a given prefix or prompt. So, how do they enable the input of state representations or images? Pretty simple: they pretrained networks to encode them into embeddings. For example, for images, they experiment with a 4B & 22B parameter vision transformer (ViT) to produce embedding vectors. These embedding vectors are then linearly projected to match the embedding dimensions of the word token embeddings.
During training, to form the multimodel sentences in the first place, they use special tokens (<img1>, <img2>, etc.), as shown in the figure above, that then get swapped with the embedded images (similar to how word tokens are embedded via embedding layers.)
The most interesting question is whether we should freeze the pretrained LLM and only train the ViT embedding network. Finetuning the LLM appears to be better, and co-training on the "full mixture" achieves more than double the performance. I.e., the big takeaway of this paper is that multitask training improves performance compared to training models on individual tasks.

Other Multimodal LLMs (MLLMs)
Note that PaLM-E is, of course, not the first and only LLM supporting multiple modalities (aka MLLM). Other recent or popular examples include
Kosmos-1, presented in Language Is Not All You Need: Aligning Perception with Language Models
Is It Worth Training Large Language Models From Scratch?
Is it worth training your own large language model (LLM) on domain-specific data from scratch? Researchers at Bloomberg did just that and shared a detailed technical report describing the dataset, model configuration, and training procedure. In my experience, it makes sense if we want to apply LLMs to novel data sources (e.g., protein amino acid sequences, as ProtBERT and others demonstrated). But how about adjacent data like finance articles?

Let's discuss the model proposed in BloombergGPT: A Large Language Model for Finance in more detail. BloombergGPT is a 50-billion parameter language model for finance, trained on 363 billion tokens from finance data and 345 billion tokens from a general, publicly available dataset. For comparison, GPT-3 is 3.5x larger (175 billion parameters) but was trained on 1.4x fewer tokens (499 billion).
Of course, Bloomberg GPT outperformed other LLMs on finance-related tasks. Interestingly, it also still performed well on general language tasks. I would have loved to know whether a 2-stage pretraining or a domain-specific finetuning would have yielded even better performance on the domain-specific data. I presume the authors didn't carry out these experiments due to cost reasons.
This brings us to the next topic: What hardware was the model trained on? The model was trained on 64 x 8 A100 GPUs using AWS for ~53 days. Doing some napkin math assuming a discounted 1.1 per hour rate for an A100 GPU, that would be 1274 (hours) x 1.1 (dollars per hour) 64 x 8 (GPUs) = 700k, which doesn't sound too bad, given that the LLaMA paper reported $600k training costs. But the caveat is that it didn't include hyperparameter optimization and failed runs.
Why did the authors use an architecture with "only" 50 billion parameters since GPT-3 is 3.5x larger? That's easier to answer. They adopted the Chinchilla scaling laws and found this to be a good size given the available size of the finance data.
Is it worth (pre)training the LLM on the combined dataset from scratch? Based on the paper, the model performs really well in the target domain. However, we don't know whether it's better than a) further pretraining a pretrained model on domain-specific data or b) finetuning a pretrained model on domain-specific data.
Why didn't they explore finetuning or continuing the training based on existing LLMs such as BLOOM? Finetuning (via RLHF or supervised finetuning) may have been more challenging to automate. And maybe they preferred to avoid continuing training an existing model because they didn't like the 3.5x larger BLOOM model size due to the scaling laws.
However, if you want to use the combined pretraining approach, BloombergGPT delivers an excellently described blueprint, including detailed descriptions of the architecture, datasets, and hyperparameters.
Models for Other Domains
Note that Bloomberg GPT is not the first model trained on proprietary domain-specific data from scratch. There are many examples of models trained on biomedical or legal documents. A recent example includes the Do We Still Need Clinical Language Models? paper shared in February.

General Architecture And Training Improvements: Meeting In The Middle
I mentioned that we would see more architecture and training tweaks for pure-language models. One paper from this category is Meet in the Middle: A New Pre-training Paradigm. This paper proposes a bidirectional LLM using the full sequence information during pretraining and context from both sides during inference.
The "bidirectional" here differs from BERT-style encoders that use masked language modeling to predict masked words. Instead, in Meet in the Middle (MiM), they process the sequence literally left-to-right & right-to-left like in bidirectional LSTMs.
At first glance, the idea looks similar to BiLSTMs. It's a different approach, though: it's not about concatenating the hidden states from the forward and backward directions. Instead, MiM is about finding agreement. They use a regularizer to force both directions to generate similar tokens.
There is no additional parameter overhead as the decoder is shared for both the forward and backward directions. Moreover, with enough parallelism, it can even be faster (if the two models agree entirely, each model only needs to generate half of the sequence autoregressively)
Caveat: I think for "complete the prompt"-type of queries, MiM may not work during inference, but I don't see a problem for instruction-based queries.
It could make sense to discard the backward direction during inference, i.e., use the backward idea to take more advantage of the data during pretraining, but only use the forward decoder during inference. But based on the ablation studies, the bidirectional model performs better than the unidirectional one though.

The Competitive Machine Learning Landscape
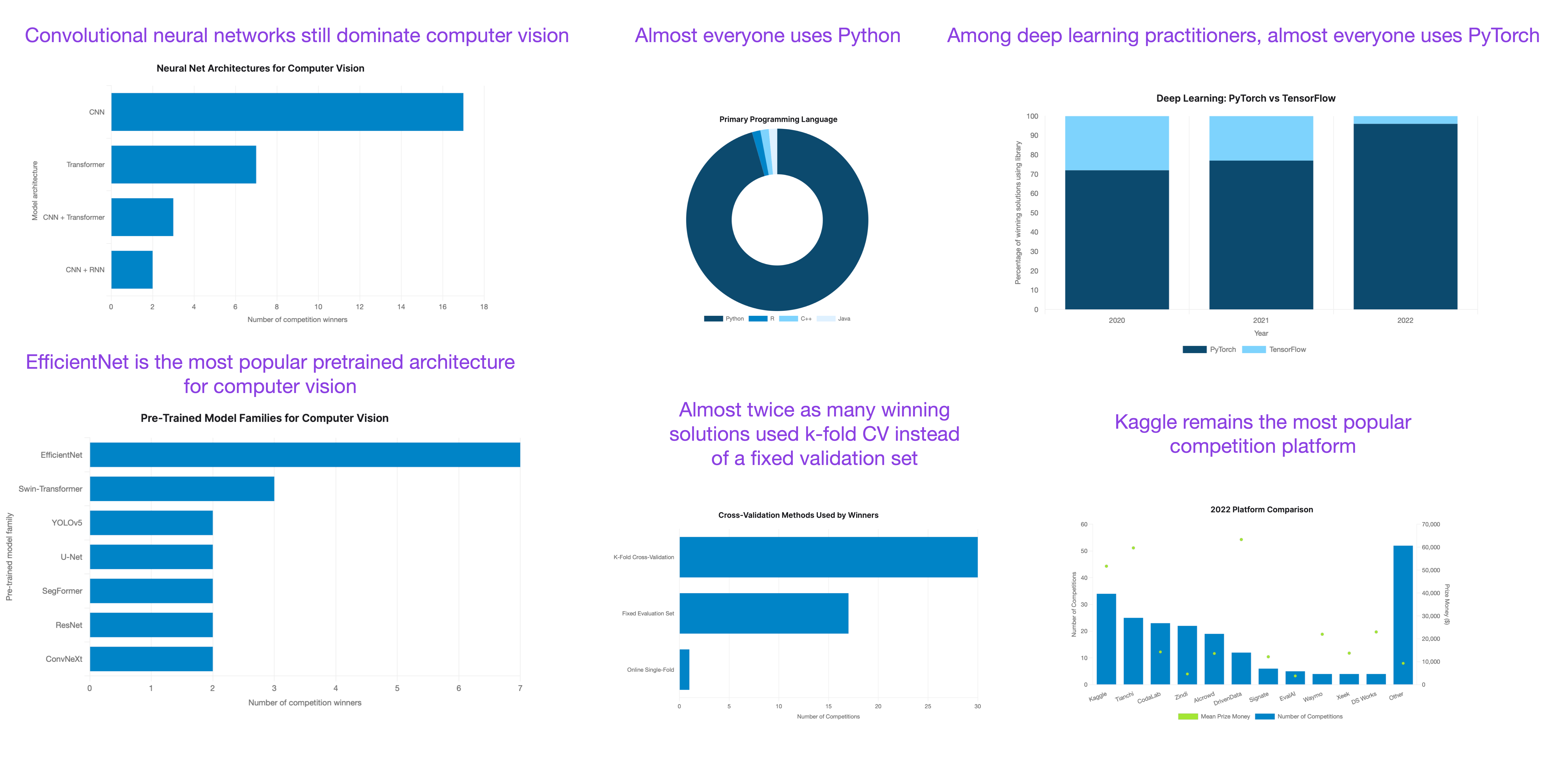
Machine learning competitions are often a good indicator of what techniques actually work well in practice on new datasets. The comprehensive State of Competitive Machine Learning 2022 report came out in March and contained many interesting and surprising insights! Below are some of the main takeaways.
As expected, transformers dominate natural language processing (NLP). ALL NLP-related winning solutions used transformers.
Convolutional neural networks still dominate computer vision. And EfficientNet is the most popular pretrained architecture for computer vision -- most people finetune pretrained models rather than training from scratch.
Almost twice as many winning solutions used k-fold CV instead of a fixed validation set.
Kaggle (barely) remains the most popular competition platform.
Almost everyone uses Python.
Out of 46 winning solutions using deep learning, 44 used PyTorch, and only 2 used TensorFlow.
A big surprise for tabular competitions: the reign of XGBoost seems over. While gradient boosting still wins most tabular competitions, LightGBM is now the preferred approach, with CatBoost coming in second. XGBoost is third.
Winning solutions of 7 out of the 10 tabular competitions used gradient boosting, 5 out of 10 used deep neural networks (implemented in PyTorch), and most winning solutions were ensemble methods.
Research Highlights in Two Sentences or Less
There are many other exciting new research papers I've read or skimmed since the last issue of Ahead of AI. Unfortunately, covering them all would turn this newsletter into a book. So, I decided to introduce a new section, Research Highlights where I am linking other researcher papers that I found particularly interesting.
Natural Language Processing
Resurrecting Recurrent Neural Networks for Long Sequences (https://arxiv.org/abs/2303.06349)
Recurrent neural networks are efficient at inference on long sequences but slow to train and difficult to optimize. This paper introduces linear recurrent units and shows that the careful design of recurrent neural networks can perform well on long-range tasks while also having good training speed.
High-throughput Generative Inference of Large Language Models with a Single GPU (https://arxiv.org/abs/2303.06865)
This paper introduces FlexGen, a high-throughput generation engine designed for running LLMs with limited GPU memory.
Pretraining Language Models with Human Preferences (https://arxiv.org/abs/2302.085)
According to this study, pretraining LMs with human feedback leads to significantly better preference satisfaction than the standard approach of pretraining with LM and then fine-tuning with feedback, which involves learning and unlearning undesirable behavior. The results indicate that it is advisable to go beyond imitation learning during LM pretraining and include human preferences from the beginning of the training process.
Hyena Hierarchy: Towards Larger Convolutional Language Models (https://arxiv.org/abs/2302.10866)
Hyena is a drop-in replacement for attention that uses implicitly parametrized long convolutions and data-controlled gating. Hyena sets a new state-of-the-art for dense-attention-free architectures in language modeling on standard datasets (WikiText103 and The Pile), achieving Transformer quality with 20% less training compute required at sequence length 2K.
A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT (https://arxiv.org/abs/2303.04226)
A history and survey of digital content generation, including images and text, covering topics ranging from GANs to ChatGPT.
Foundation Models for Decision Making: Problems, Methods, and Opportunities (https://arxiv.org/abs/2303.04129)
Pretrained large language models hold promise for creating powerful new systems for applications such as dialogue, autonomous driving, healthcare, education, and robotics. This paper provides an overview of recent research in this area.
Computer Vision
Consistency Models (https://arxiv.org/abs/2303.01469)
Consistency models are a novel type of generative model that can produce high-quality samples without requiring adversarial training. They are designed to overcome the limitations of diffusion models and support fast one-step image generation.
Scaling up GANs for Text-to-Image Synthesis (https://arxiv.org/abs/2303.05511)
GigaGAN scales up text-to-image synthesis, allowing models to take advantage of large datasets. The GigaGAN architecture offers several benefits, including much faster inference times, generating high-resolution images, and supporting various latent space editing applications.
Your Diffusion Model is Secretly a Zero-Shot Classifier (https://arxiv.org/abs/2303.16203)
The paper discusses the significant improvements in text-based image generation capabilities brought by large-scale text-to-image diffusion models, which can also provide conditional density estimates useful for tasks beyond image generation. Finally, the paper proposes a generative approach to classification called Diffusion Classifier, which utilizes density estimates from text-to-image diffusion models to perform zero-shot classification without additional training.
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models (https://arxiv.org/abs/2303.04671v1)
Visual ChatGPT is a system that enables users to interact with ChatGPT using both languages and images and complex visual questions or editing instructions that require collaboration between multiple AI models.
Towards Democratizing Joint-Embedding Self-Supervised Learning (https://arxiv.org/abs/2303.01986)
This paper aims to make self-supervised learning methods for image data like SimCLR (a topic I am covering in the upcoming Deep Learning Fundamentals Unit 7) more accessible. The researchers simplify SimCLR and demonstrate that it is feasible to train SimCLR to learn valuable representations with a single image patch as a negative example and basic Gaussian noise as the sole data augmentation for the positive pair.
Sigmoid Loss for Language Image Pre-Training (https://arxiv.org/abs/2303.15343)
The paper proposes a simple pairwise sigmoid loss for image-text pre-training that does not require a global view of pairwise similarities for normalization. With this approach, they achieve high accuracy on zero-shot ImageNet classification in two days using large models and large batch sizes.
Headlines
It seems that ChatGPT truly opened the AI floodgates back when it first launched in December. Since then, AI has entered mainstream perception, and news about large language models still dominates the major news outlets. And what's more, with every passing month, large language models are even picking up more steam. Since many companies just recently jumped onto the bandwagon and started training their own models (see BloombergGPT discussed above), which takes time, I am confident that we will see and find large language models everywhere by the end of the year.
ChatGPT
OpenAI announed to discontinue support for the Codex API and code-davinci-002 and then reversed course amidst complains from researchers.
Due to a ChatGPT bug, users were able to see the titles of other users’ conversation history.
OpenAI launched GPT4 with an accompanying technical report lacking of any technical details of how it works or differs from previous GPT models. The announcement dissappointed research and open source communities who expected reports similar to previous GPT models.
OpenAI also launched ChatGPT plugins.
Microsoft's GitHub announced Copilot-X, whichintegrates GPT-4 into GitHub's Copilot.
ChatGPT Competitors
Google launched Bard chatbot to compete with ChatGPT.
According to recent announcements, Google plans to improve Bard with more advanced models like PaLM
Following the dissappointment surrounding Bard, Alphabet "forced the two AI research teams [Google Brain and DeepMind], to overcome years of intense rivalry to work together."
One of Google's top AI engineers quit after Bard was trained on ChatGPT data; Google denied the accusation.
Google announced the PaLM API for developers analogous to OpenAI's ChatGPT API.
Anthropic unveiled Claude, a ChatGPT competitor that the startup claimed is less prone to generating hallucinations.
Huawei trained a trillion parameter language model on Chinese texts using their own Ascend 910 AI processors instead of NVIDIA GPUs.
Elon Musk expressed interest in creating a competitor to OpenAI
AI Regulation
The US Copyright Office offers advice on the copyright eligibility of art created by AI. In summary: Copyright may apply to the creative result of AI-generated art if there is significant human creativity involved.
ChatGPT complicated EU plan to regulate AI since large language models have no single intended use and can be used for good and bad purposes.
The Federal Trade Commission (FTC) warned of the dangers of overhyping AI and the potential for false claims. The post highlights that companies making exaggerated claims about AI will be monitored closely by the FTC.
An open letter signed by prominent figures demanded six-month pause on experiments training GPT-4 successors. (I commented on it here)
Open Source Highlights
It was a particularly great month for open source. After concerns that AI development was trending towards close source (see GPT-4), open source got a second wind and is trending upwards, which is awesome.
PyTorch 2.0
It may feel old hat since PyTorch 2.0 was first announced in December 2022 (and covered in Ahead of AI #3), but PyTorch 2.0 was now finally officially released on March 15! As announced earlier, the two main highlights are the 100% backwards compatibility as well as the new torch.compile function to optionally compile model graphs.
I recently used torch.compile for finetuning a BLOOM model (Finetuning Large Language Models On A Single GPU Using Gradient Accumulation) and noticed a quite significant speed boost indeed (note: the longer you train, the more likely your model will benefit from compilation).

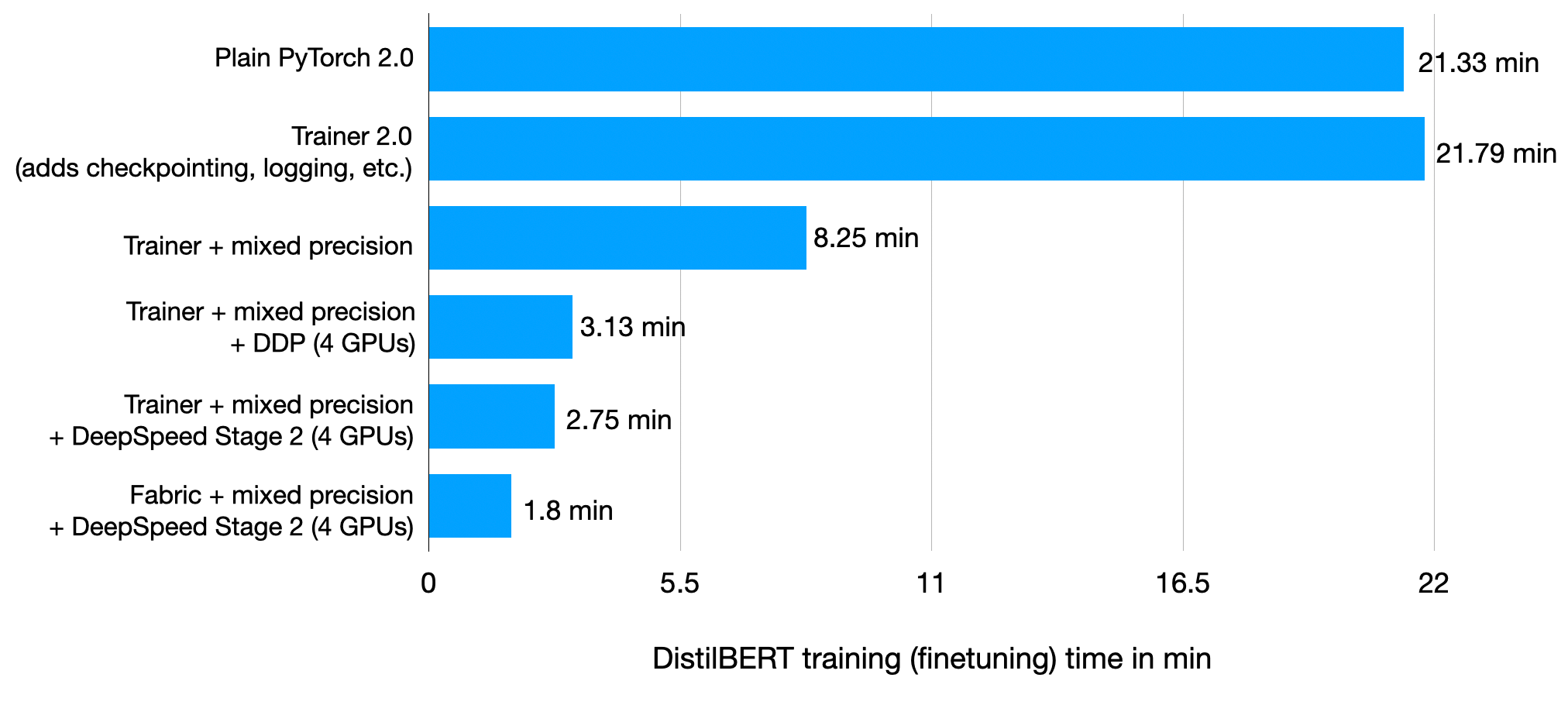
Lightning 2.0: Trainer 2.0 for PyTorch and Accelerated Training with Fabric
Lightning 2.0 was just released this month, featuring an update to the open-source Lightning Trainer for PyTorch models and the new open-source Fabric library to accelerate pure PyTorch training loops with advanced multi-GPU training paradigms, mixed-precision training, and more.

You can check out the Lightning 2.0 release notes here.
Recently, I wrote a blog post, Some Techniques To Make Your PyTorch Models Train (Much) Faster using the Trainer 2.0 and Fabric in case you are interested in some hands-on examples of finetuning a large language model.
Lit-LLama
Lit-LLaMA is a rewrite of Meta's LLaMA large language models (discussed in the previous issue) implemented on top of nanoGPT. The motivation for this rewrite was that the LLaMA repository only contains the inference, not the training code. Furthermore, the original LLaMA code is licensed under GPL, incompatible with several other open-source licenses; Lit-LLaMA is licensed under a permissive Apache v2 open-source license.

GPT4All
This project provides a demonstration of how to train a large language model using Meta's LLaMa. The team also shared the data they collected, along with the data curation process, training code, and final model weights. In addition, they also share quantized 4-bit versions of the model, which can be run on a laptop CPU. The code comes with a GPL license.
Twitter's Algorithm
None other than Twitter open-sourced their recommendation algorithm on GitHub. It's interesting to find both TensorFlow and PyTorch used in their code base. Also, other popular libraries such as scikit-learn, TorchMetrics, and matplotlib are part of their repository.
Taking a closer look at their trust_and_safety_models, it appears most predictive language models are based on BERT -- it's a very versatile encoder-style language model that I like using for various predictive modeling tasks as well.

MLxtend 0.23
MLxtend is a library with machine utility functions that I have been maintaining for almost a decade. I just released a new version last weekend with some improvements thanks to the kind contributions by the community. Among others, the new MLXtend 0.23 version features multiprocessing for the popular plot_decision_regions function and a new frequent pattern mining algorithm, H-Mine.
Notable Quote
"We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence"
-- Noam Shazeer (second author of the original transformer paper) in the GLU Variants Improve Transformer paper
This magazine is a personal passion project that does not offer direct compensation. However, for those who wish to support me, please consider purchasing a copy of one of my books. If you find them insightful and beneficial, please feel free to recommend them to your friends and colleagues.

Your support means a great deal! Thank you!
Great work Sebastian!
Boston dynamics?